CPP_review
C++ 复习
零. 导读
1. 基本理念
- 勿在浮沙筑高台
2. 内容
(1) 培养正规,大气的编程习惯
- 基于对象(Object Based): 面对的是单一的 class 的设计、将数据和函数封装成类,只有内部的函数可以处理数据;并通过类创建对象。
Class(Data, Functions) -> Objects - 面向对象(Object Oriented): 学习 classes 之间的关系:继承(inheritance)、复合(composition)、委托(delegation)
(2) 泛型编程(generic programming)
(3) 深入探索面向对象之继承所形成的的对象模型(object model),包含隐藏于底层的 this、虚指针、虚表、虚机制以及虚函数所造成的多态效果。
3. 关于 C++
(1) C++ 的历史: B语言(1969) → C语言(1972) → C++ 语言(1983) [new C → C with Class → C++] → Java 语言 → C# 语言
(2) C++ 演化:C++ 98(1.0) ☆ → C++ 03(TR1, Technical Report 1) → C++ 11 (2.0) ☆ → C++ 14
(3) C++ 包括 C++语言 和 C++标准库 两部分
4. 书籍推荐:
语言:C++ Primer (Fifth Edition)、The C++ Programming Language (Fourth Edition)
规范:Effective C++ (Third Edition) → Efficitive Modern c++
标准库: The C++ Standard Library、STL 源码剖析
一. 基础
1.代码的基本形式

扩展名 (extension file name) 不一定是 .h 或者 .cpp, 也可能是 .hpp 或其他或无扩展名。
(1) 头文件引用
// complex.cpp
#include <iostream> # 引用 C++ 头文件, 无须 .h
#inlcude <cstdio> # 引用C头文件, 去掉头文件,前面加 c
#include "utils.h" # 引用自定义的头文件 (2) 头文件布局
// complex.h
#ifndef __COMPLEX__ // (1) 头文件的防卫式声明:防止重复定义
#define __COMPLEX__
class ostream;
class complex;
complex& __doapl (complex* ths, const complex& r); // 1. 前置声明
class complex class declarations { ... }; // 2. 类声明
complex::function ... // 3. 类定义
# endif 2. 类的声明与定义 class head + class body
2.1 access level(访问级别)
访问级别分为 private , public, protected 三类,其位置可以交错。 数据放在 private 区,封装在类内,然后通过函数访问数据。
2.2 修饰关键字
(1) inline
有些函数可以直接定义在 body 中,另外一些在 body 之外定义。函数若在 class body 内定义,会被默认成为 inline 函数。具体是否内联,需要有编译器而定。 将函数声明为 inline,表示要求编译器在每个函数调用点上,将函数的内容展开。面对一个 inline 函数, 编译器可将该函数的操作改为以一份函数代码副本代替。这将使我们获得性能改善。
!编译器一般不会内联包含循环、递归、switch 等复杂操作的内联函数。在类声明中定义的函数,除了虚函数的其他函数都会自动隐式地当成内联函数。
优点:
内联函数同宏函数一样将在被调用处进行代码展开,省去了参数压栈、栈帧开辟与回收,结果返回等,从而提高程序运行速度。
内联函数相比宏函数来说,在代码展开时,会做安全检查或自动类型转换(同普通函数),而宏定义则不会。
在类中声明同时定义的成员函数,自动转化为内联函数,因此内联函数可以访问类的成员变量,宏定义则不能。
内联函数在运行时可调试,而宏定义不可以。
缺点:
代码膨胀。内联是以代码膨胀(复制)为代价,消除函数调用带来的开销。如果执行函数体内代码的时间,相比于函数调用的开销较大,那么效率的收获会很少。另一方面,每一处内联函数的调用都要复制代码,将使程序的总代码量增大,消耗更多的内存空间。
inline 函数无法随着函数库升级而升级。inline函数的改变需要重新编译,不像 non-inline 可以直接链接。
是否内联,程序员不可控。内联函数只是对编译器的建议,是否对函数内联,决定权在于编译
(2) const : 常 🌟🌟
const 表示不会改变数据的内容, const 可以修饰对象、成员函数和成员变量。const 修饰对象表示该对象的成员变量不可改变, const 修饰成员函数表示成员函数不能改变成员变量的值。
double real() const {return re;}
complex& operator += (const complex&);
const string str("Hello World!");通过对象调用成员函数, 可能会产生如下的四种情况:
| const object | non-const object | |
|---|---|---|
| const member functions | √ | √ |
| non-const member functions | × | √ |
使用的基本原则:
不能通过 const 对象调用 non-const 成员函数
当成员函数的 const 和 non-const 版本同时存在, const object 只会(只能) 调用 const 版本。 non-const object 只会(只能) 调用 non-const 版本。如下所示的代码, 通过 const 进行函数签名的区分,实现 const 函数和 non-const 函数的分开调用:
// 该段代码存在于 class template std::basic_string<...> // 实现了操作符 [] 的 const 和 non-const 的函数重载, 其中 const 函数并不会更改对象 // 也不用过多的考虑引用计数和写时复制, 其设计相对简单。 charT operator[](size_type pos) const { ...... /* 不需要考虑 Copy On Write */ } reference operator[](size_type pos) { ...... /* 需要考虑 Copy On Write */ }
(3) static: 静态 🌟🌟
这里的静态是指对象的生存周期:
- 静态生存期:其生命在作用域 (scope) 结束之后仍然存在,直到整个程序结束
- 动态生存期: 起始于定义的位置,终止于最近的
“}”
当成员变量或者成员函数是 non-static 的时候, 每个对象会有一个内存存储。通过对象调用这个 non-static 的成员函数时,会将该对象的地址传递给这个成员函数
class complex{
public:
double real() const { return re; } // return re; 会默认翻译为 return this->re;
private:
double re, im;
};
complex c1, c2, c3;
cout << c1.real(); // 翻译为 cout << complex::real(&c1);
cout << c2.real(); // 翻译为 cou << complex::real(&c2); 当成员变量或者成员函数是 static 的时候, 整个类共享一份成员变量。 这个成员变量不属于任何对象,而属于整个类。
- static 函数可以通过类或者对象进行调用。
- 需要在类定义的外部对这个成员变量进行定义。
- 静态成员函数不能调用非静态成员变量。
class Account{
public:
static double m_rate;
static void set_rate(const double & x) { m_rate = x; }
};
double Account::m_rate = 8.0; // 需要在类定义的外部对这个静态成员进行定义
int main(){
// static 函数 可以通过 类 或者 对象 进行调用
Account::set_rate(5.0);
Account a;
a.set_rate(7.0);
}2.3 函数
(1) 参数传递和返回值传递
- 参数传递 pass by value vs pass by reference(to const)
尽量不用 pass by value(小于4个字节的可以传值),而要使用 pass by reference。 如果传递引用并不希望修改,前面需要加上 const。
- 返回值传递 return by value vs return by reference(to const)
返回值的传递也尽量使用引用传递。局部变量不能传递引用,因为局部变量会在返回时被销毁。
(2) 设计构造函数
- 构造函数尽量使用初始值列表的语法形式,这是在初始化时设定初值,而不是在初始化之后再进行赋值。
- 构造函数的函数名称和类名相同,没有返回值,并且可以重载。
- 不能显示调用,而是在初始化的时候进行自动调用。
- 与构造函数相对应的是析构函数,不带指针类的设计不需要写析构函数
(3) 默认参数和函数重载 (overloading)
- 默认参数多个时候,有默认参数的参数需要放在后面。
- 参数的个数和类型不同,返回值不同不能重载
- 默认参数和函数重载可能会发生冲突。编译器会无法确认需要调用的函数
(4) 友元 friend:友元可以获取类的数据, 但是破坏了封装性。相同 class 的各个 objects 互为友元。
(5) 操作符重载 与 this 指针
this 指针:所有的成员函数都带有一个隐藏的指针,指向调用者。
- 成员函数(有this)
complex::operator += (const cimplex& x){
return __dopal(this, r);
}PS: 传递者无需要知道接受者是以什么形式接受的
- 非成员函数(无this)
inline complex operator +(const complex& x, const complex& y){
return complex(real(x) + real(y), imag(x) + imag(y));
}
// PS: typename() 创建临时对象(6) << 重载
ostream& operator << (ostream & os, const complex & x){
return os << '(' << real(x) << ',' << imag(x) << ')';
}二. 拷贝构造、拷贝复制、析构函数
类定义的时候,编译器会默认生成六个成员函数:构造函数、拷贝构造函数、拷贝赋值函数、析构函数、取地址运算符、取地址运算符(const版本)。其中拷贝构造函数、拷贝赋值函数、析构函数被称为三大函数(Big Three)。
如果自定义的类带有指针,则需要自己去定义拷贝构造函数和拷贝复制函数。 why?
默认的拷贝构造函数仅仅是将值拷贝过去,反映在指针上就是改变指针的指向。如下图所示,默认拷贝构造和默认的拷贝赋值会将 b 的指针也指向 a,这也就所谓的浅拷贝。这会导致两个问题:
(1) 别名 alias: a 和 b 的指针指向同一块内存, 这种操作很危险
(2) b 原有的指向的内容没有释放,从而产生内存泄漏

class String{
String(const char* cstr = 0);
String(const String& str);
String& operator=(const String& str);
~String();
char* get_c_str() const { return m_data; }
private:
char * m_data;
};
// 构造函数
inline String::String(const char* cstr =0)
{
if(cstr){
m_data = new char[strlen(cstr) + 1];
strcpy(m_data, cstr);
}else { // 为指定初值
m_data = new char[1];
* m_data = '\0';
}
}
// 析构函数
inline String::~String(){
delete[] m_data;
}
// 拷贝构造函数
inline String::String(const String& str)
{
m_data = new char[strlen(str.m_data) + 1];
strcpy(m_data, str.m_data);
}
// 拷贝赋值函数 copy assignment operator
inline String& String::operator=(const String& str){
// 一定要在 operator= 中检查是否 self assignment
if(this == & str)
return * this;
delete [] m_data; // (1) 清除自身内容
m_data = new char[strlen(str.m_data) + 1]; // (2) 重新申请一段内存, 用于存储
strcpy(m_data, str.m_data); // (3) 将原有的数据 copy 过来
return * this;
}
int main(){
String s1();
String s2("Hello");
String s3(s1);
cout << s3 << endl;
s3 = s2;
cout << s3 << endl;
}如果没有自我赋值检查, 左右两个 pointers 指向同一个 memory block。 前述 operator= 做的第一件事情就是 delete,此时自身对象的 m_data 将会被释放, m_data 指向的内容将不存在。然后,当企图访问 rhs时, 会产生不确定行为(undefined behavior)。
三. 内存管理
1. 指针和引用的区别 ? 🌟🌟
int x = 0;
int* p = &x; // p is a point to x: p 本身是一个变量,但是存储的是 x 的地址
// 一个小小的技巧: 这里的 * 是靠近 int 的, 表示 p 是 int* 类型
int &r = x; // r is a reference to x: r 代表 x。r, 此时 x 都是 0(1) 指针是在内存中的四/八字节存储空间,指针存储的内容就是一个地址,根据这个地址可以找到另外一片内存,指针就是这片内存的索引。简单的讲,指针就是一种保存变量地址的变量。
引用则相当于是为对象起了一个别名, 引用和原来的对象具有相同的大小和地址。
(2) 在编译器方面,两者是一样的,编译器会将两者编译为相同的汇编指令。有一句很好的话可以来形容:reference 就是漂亮的 point。
(3) 两者主要的区别是在语法层面:
sizeof(指针) 的大小是4/8,sizeof(引用) 的大小是被引用对象的大小;
初始化(引用必须初始化为一个对象的引用、指针则可以初始化为空)、可改变(引用不可以改变、指针则可以更改指向)、传参(作为参数传递时,指针需要被解引用才可进行操作,引用可直接修改)
静态(没有静态引用、但是有静态指针)、自加运算符(含义不一样,引用是对其值进行自加, 指针则是表示指针进行移动)
(4) 使用:
引用相对于指针更加安全。平时编程时,在能使用引用的情况下,就不要轻易使用指针,当然,在操作数组或者大面积内存时,用指针更好。
reference 通常不用于声明变量,而用于参数类型和返回值类型的描述。 reference 的一个优点是可以保持调用端和被调用端的写法与传值写法相同。
引用并不能作为函数签名的区别,这会引起二义性。 但是 const 可以。
// 如下两个函数声明, 会产生二义性!
double imag(const double& im) { ... }
double imag(const double im) {...}2. 所谓 stack(栈), 所谓 heap(堆) 🌟🌟
在 C++ 中, 内存分为 5 个区, 分别是堆、栈、自由存储区、全局/静态存储区和常量存储区。
- 栈:存在于某作用于某作用域(scope) 的一块内存空间(memory space)。内存由编译器在需要时自动分配和释放。通常用来存储局部变量和函数参数(为运行函数而分配的局部变量、函数参数、返回地址等存放在栈区)。栈运算分配内置于处理器的指令集中,效率很高,但是分配的内存容量有限。
- 堆:由操作系统提供的一块 global 的内存空间,程序可动态分配 dynamic allocated 从中获得若干区块。一般是使用由 new 进行分配,使用 delete 或 delete[] 释放。如果未能对内存进行正确的释放,会造成内存泄漏。但在程序结束时,会由操作系统自动回收。
- 自由存储区:和堆类似,不过存储那些有 malloc 分配,用 free 释放的内存块。
- 全局/静态存储区:用于存储全局变量和静态变量
- 常量存储区:存放常量,且不允许更改
class Complex { ... };
...
{
Complex c1(1, 2); // c1 占用的空间来自 stack
Complex* p = new Complex(3); // complex(3) 是个临时对象,
// 所占用的空间是 new 在 heap 动态分配而得, 并由 p 指向
}3. 区分四种对象
class Complex { ... };
...
{
complex c1(1, 2); // stack object: 其生命在作用域结束之际结束,
// 这种作用域内的 object,又称为 auto object, 因为它会被自动清理。
static Complex c2(1, 2); // static object: 其生命在作用域(scope) 结束之后仍然存在,直到整个程序结束
Complex * p = new Complex; // heap object: 其生命周期随着 deleted 之际结束。
// 当你申请了一段内存,你就有责任释放它, 否则就会产生内存泄漏。
...
delete p;
}
Complex c3(1, 2); // global object: 其生命在整个程序结束之后才结束。
// 你也可以视为一种 static object, 其作用域是整个函数。
int main(){
...
}4. new 和 delete
(1) new:先分配 memory, 再调用 ctor
Complex * pc = new Complex(1, 2);
// 编译器会将其转化为如下语句:
Complex * pc;
void mem = operator new(sizeof(Complex)); // (1) 分配内存 --> 其内部调用 malloc(n)
pc = static_cast<Complex*>(mem); // (2) 转型
pc -> Complex::Complex(1, 2); // (3) 构造函数 --> Complex::complex(pc, 1, 2);(2) delete: 先调用 dtor, 再释放内存
String * ps = new String("Hello");
...
delete ps;
// 编译器将其转化为:
String::~String(ps); // 析构函数
operator delete(ps); // 释放内存 -> 其内部调用 free(ps)5. 动态分配所得的内存块
class complex{
...
private:
double re, im;
};
class String{
...
private:
char* m_data;
};Complex * pc = new Complex(1, 2);
String * ps = new String("Hello!");(1) 内存的分配情况
- 实际所占用的内存 complex: (4*2) string: (4) 绿色部分
- debug header (32+4) -> 在 debug 模式下才有 灰色部分
- 字节对齐 complex:(3/0) string: (0/1) -> 调整为8的倍数 青色部分
- 上下cookies (4*2) 粉红色部分
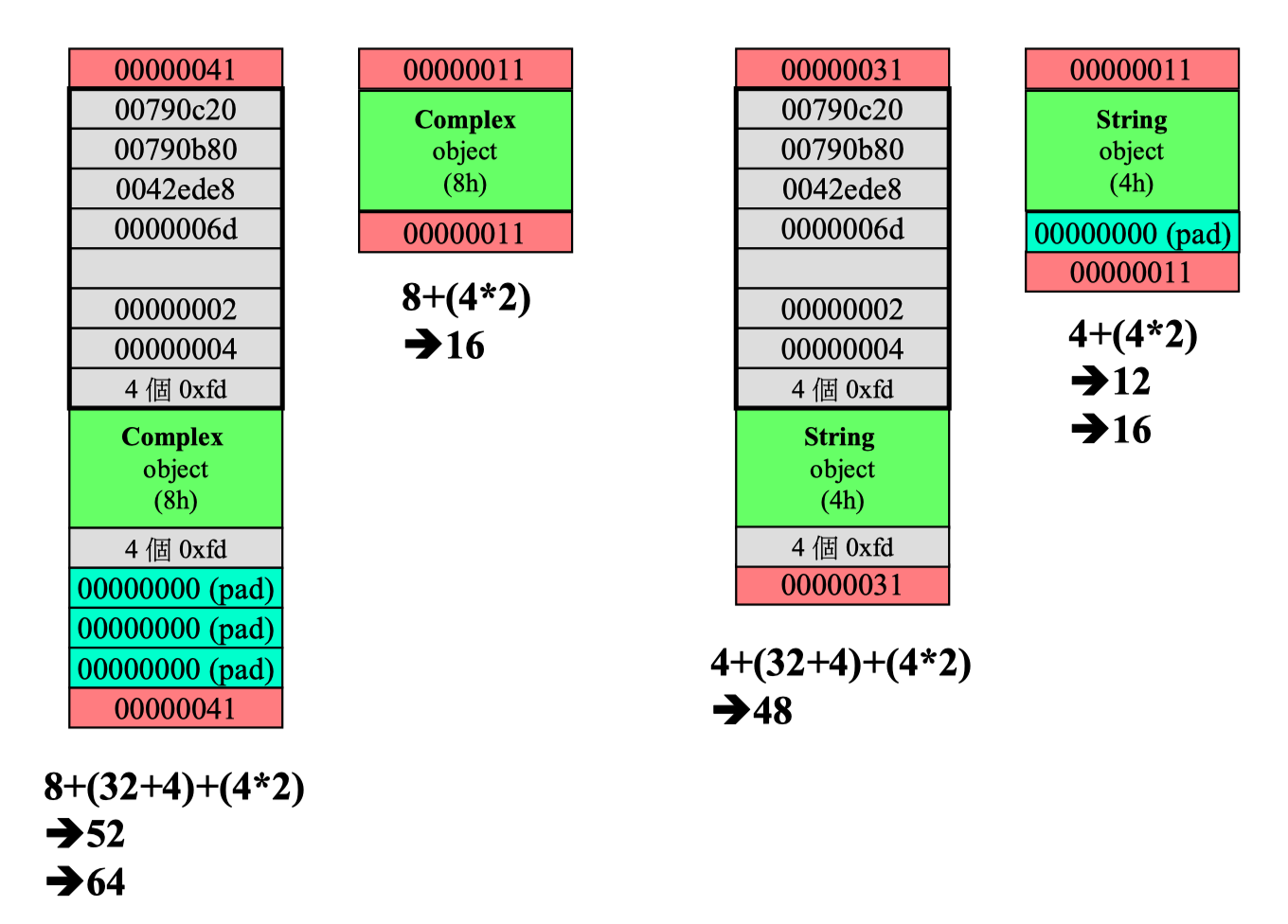
(2) 动态分配数组所得的 array
Complex * p = new Complex[3];
String * p = new String[3];- 实际所占用的内存(含有一个整数来标记数组的长度) complex: (3*4*2+4) string: (4*3+4) 灰色部分+中间白色
- debug header (32+4) → 在 debug 模式下才有 黄色部分
- 字节对齐 complex:(2/3) string: (1/1) → 调整为8的倍数 青色部分
- 上下cookies (4*2) 上下白色部分
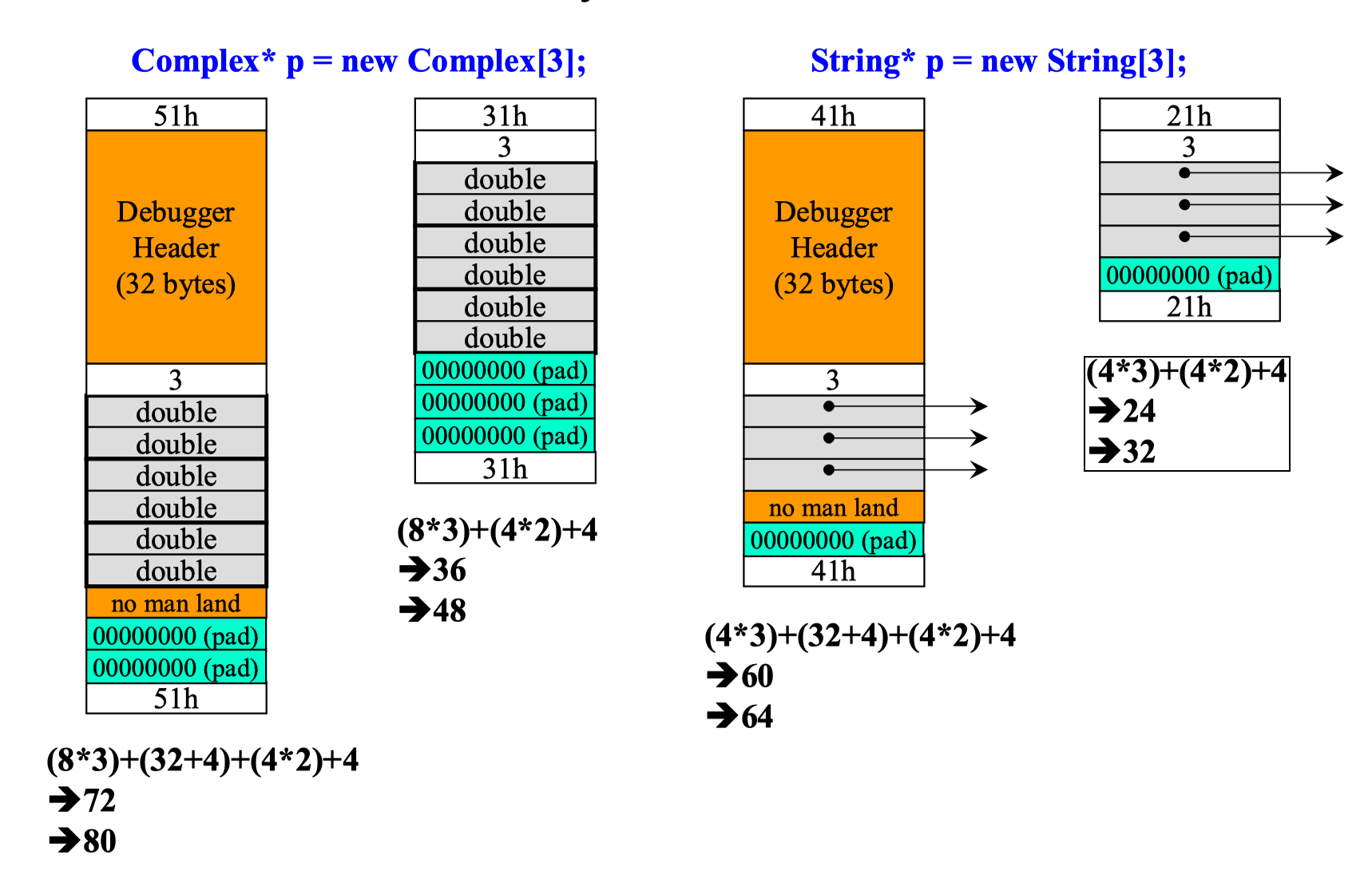
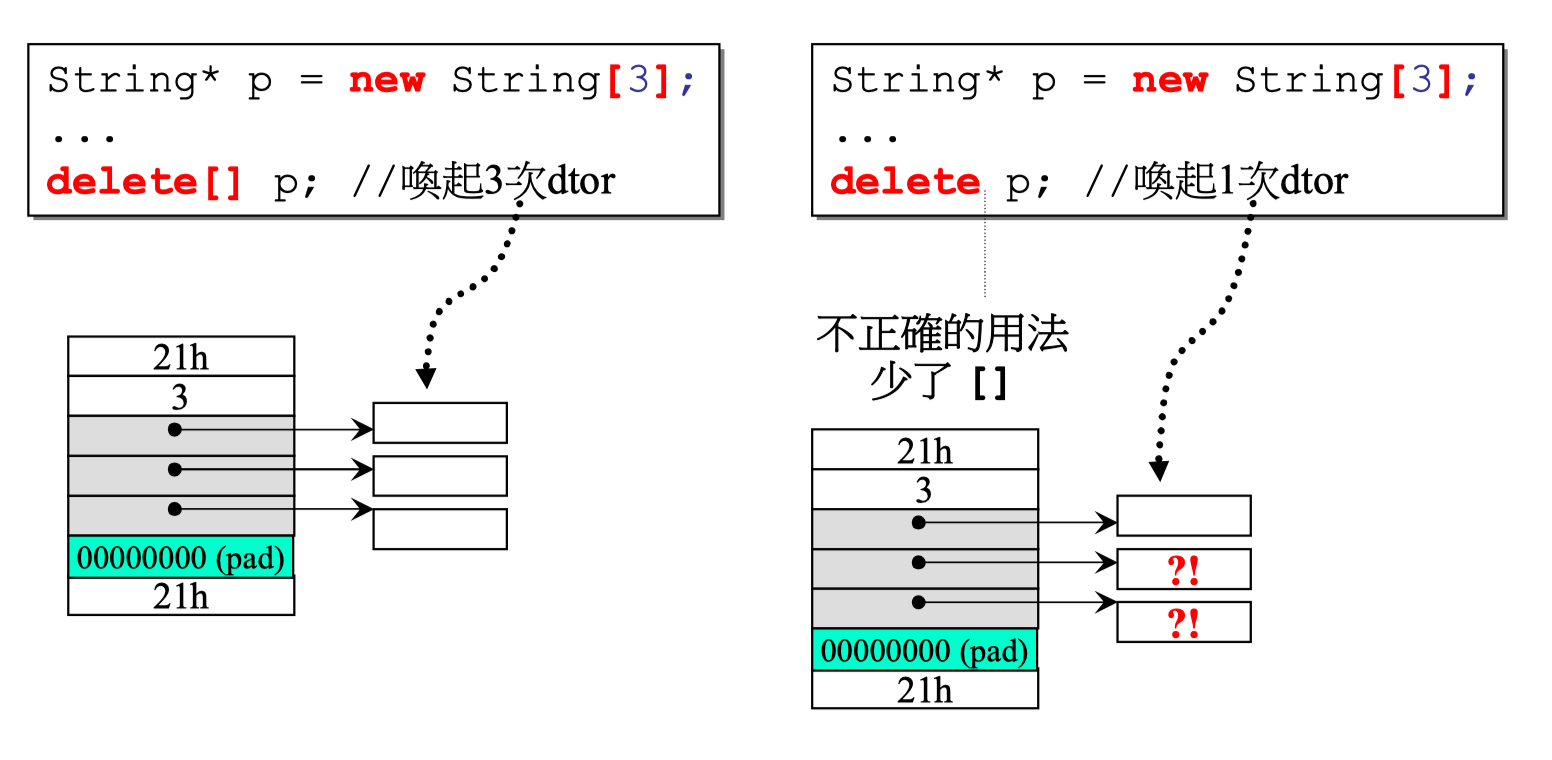
(2) arrary new 一定要搭配 array delete
如果 delete 的时候没有使用 [], 则之后调用一次析构函数, 默认只删除了 array[0]。 对于数组的其他元素则没有删除。 会造成内存泄漏。
6. 简述一下 new、delete、malloc、free 的关系?
malloc 与 free 是C++/C 语言标准库函数, new/delete 是C++ 的运算符, 他们分别用于申请动态内存(malloc)和释放内存(free)。
对于非内部数据类型的对象而言,对象在创建的同时要自动执行构造函数, 对象在消亡之前要自动执行析构函数。 由于malloc/free 是库函数而不是运算符,不在编译器控制权限之内,不能够把执行构造函数和析构函数的任务强加于 malloc/free, 所以只用 malloc/free 无法满足动态对象的要求。 因此, C++ 语言需要一个能完成动态内存分配和初始化工作的运算符 new, 以及一个能完成清理和释放内存工作的运算符 delete。
实际上, new 首先调用 operator new 函数申请空间(底层通过 malloc 实现),然后调用构造函数进行初始化,最后返回自定义类型的指针; delete 首先调用析构函数,然后调用 operator delete 释放空间(底层通过 free 实现)。
四. OOP(Object Oriented Programming)
面向对象谈的是对象和对象之间的关系,对象是由类派生而来,所以其实质是类和类之间的关系。常见的类之间的关系有三种:Inheritance 继承、Composition 组合 和 Delegation 委托。
1. composition(复合) : has-a
(1) 代码示例
// 这里体现了 23 个设计模式中的 -- adapter: 利用一个类来实现另一个类
// queue 里面有一个 deque, 这种关系叫做 composition 复合
// queue 借用 deque 的已有的实现来实现自己
template <class T>
class queue {
...
protected:
deque<T> c; // 底层容器
public:
// 以下完全利用 c 的操作完成
bool empty() const { return c.empty(); }
size_type size() const { return c.size(); }
reference front() { return c.front(); }
reference back() { return c.back(); }
//
void push(const value_type& x) { c.push_back(x); }
void pop() {c.pop_front(); }
};
(2) 复合的 UML 表示

(3) 内存表示
(4) Composition(复合) 关系下的构造和析构
构造由内而外: Container 的构造函数首先调用 Component 的 default 构造函数,然后才执行自己。
Container::Container(...):Component() { ... };析构由外而内: Container 的析构函数首先执行自己,然后才调用 Component 的析构函数。
Container::~Container(...){ ... ~Component() };2. Delegation(委托) :Compostion by reference
(1) 示例代码:
// 这个示例体现了设计模式中的 handle/Body(pImpl) point to implementation
// String 有一个 StringRep, 但是这个 "有" 是通过指针来实现的
// 一个类的真正的实现通过另一个类来实现,该类只是对外的接口,
// 当该类需要某个行为的时候,都调用另一个类的函数来服务
class StringRep;
class String{
public:
String();
String(const char* s);
String(const String& s);
String &operator=(const String& s);
~String();
...
private:
StringRep* rep; // piml
}
// file String.cpp
#include "String.hpp"
namespace {
class StringRep {
friend class String;
StringRep(const char* s);
~StringRep();
int count;
char* rep;
};
}
String::String(){ ... } ...(2) UML 表示
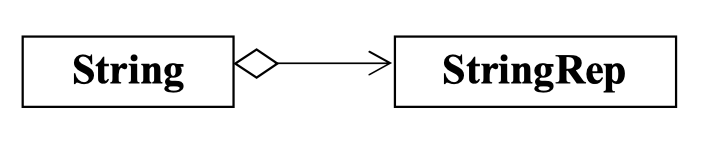
3. Inheritance(继承) 表示 is-a
函数的继承继承的是调用权!
(1) 示例代码:
struct _List_node_base _List_node_base {
_List_node_base* _M_next;
_List_node_base* _M_prev;
};
template<typename _Tp>
struct _List_node : public _List_node_base{
_Tp _M_data;
};(2) UML 表示和内存表示

!base class 的 dtor 必须是 virtual , 否则会出现undefined behavior
(3) Inheritance(继承)关系下的构造和析构
构造由内而外:Derived 的构造函数必须调用 Base 的 default 构造函数, 然后才执行自己。
Derived::Derived(...): Base() {...};析构由外而内: Derived 的析构函数首先执行自己,然后才调用 Base 的析构函数。
Derived::~Derived(...){... ~Base() }(4) Inheritance(继承) + Composition(复合)
构造由内而外:Derived 的构造函数首先调用 Base 的 default 构造函数, 然后调用 Component 的 default 构造函数,然后才执行自己。
Derived::Derived(...): Base(),Component() {...};析构由外而内: Derived 的析构函数首先执行自己, 然后调用 Component 的析构函数, 然后调用 Base 的析构函数。
Derived::~Derived(...){... ~Component(), ~Base() }4. 基于 Delegation(委托) 和 Inheritance(继承) 的设计模式
4.1 观察者模式
观察者组合到某个对象中,当更新的时候,通知观察者。 如下所示:Observer 和 Subject 是 Delegation 关系, 另外 Observer 可以作为父类,派生出许多子类, 并且子类可以组合到 Subject 类中。
class Observer{
public:
virtual void update(Subject* sub, int value) = 0;
};
class Subject{
int m_value;
vector<Observer *> m_views;
public:
// 添加观察者
void attach(Observer* obs){
m_views.push_back(obs);
}
// 更新数据, 将该数据 更新到所有的观察者
void set_val(int value){
m_value = value;
notify();
}
void notify(){
for(int i = 0; i < m_views.size(); ++i){
m_views[i]->update(this, m_value);
}
}
// 删除操作
// ...
}
4.2 composite(复合)
如下图所示, 父类为 Component, 两个子类均继承自 Component。 然后 Primitive 和 Composite 为委托关系。
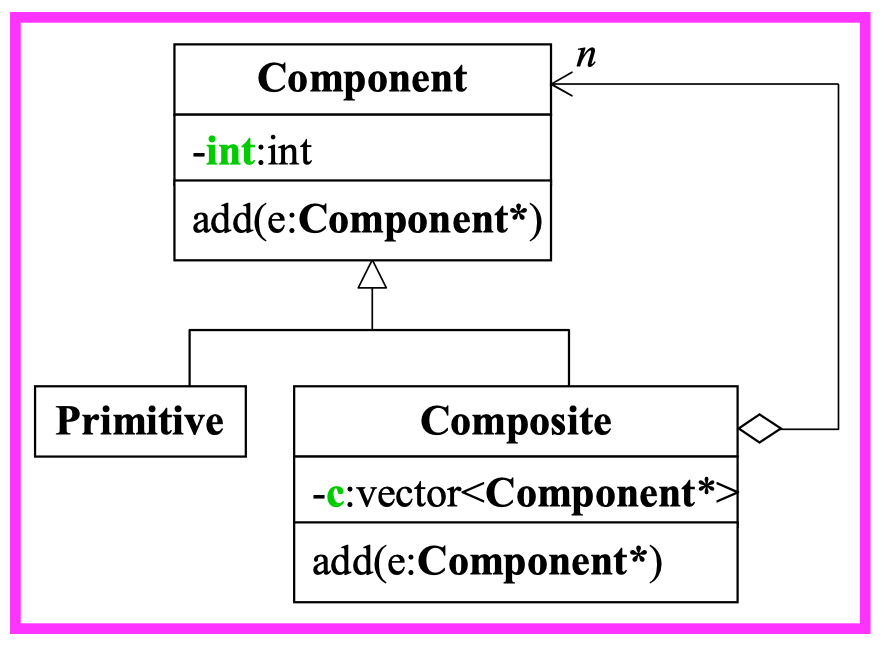
class Component {
int value;
public:
Component(int val) { value = val; }
virtual void add( Component* ) { }
};
class Primitive: public Component {
public:
Primitive(int val): Component(val) {}
};
class Composite: public Component {
vector <Component*> c;
public:
Composite(int val): Component(val) { }
void add(Component* elem) {
c.push_back(elem);
}
// ...
};4.3 prototype
考虑如下一种情况,需要一个继承体系,父类(抽象类)想要去创建未来才会出现的子类。其中父类由框架编写者编写,子类则由其他开发者编写。 解决方法为:让派生类创建自身,让父类有办法看到子类(注册),并进行复制。
父类如何做: (1) 实现 findAndClone: 实现子类的创建 (2) addPrototype 函数, 实现注册
子类如何做?
(1) 声明一个静态对象,然后将构造函数声明为私有,并在其中进行注册(调用 addPrototype)。
如下所示的 _LSAT: LandSatImage 和 -LandSatImage(),在其中调用了 addPrototype 进行注册。
(2) 实现 clone 函数,然后借助一个 protected 的 构造函数返回新建对象。
如下所示的 clone 函数,借助于 #LandSatImage(int) 新建对象并返回。
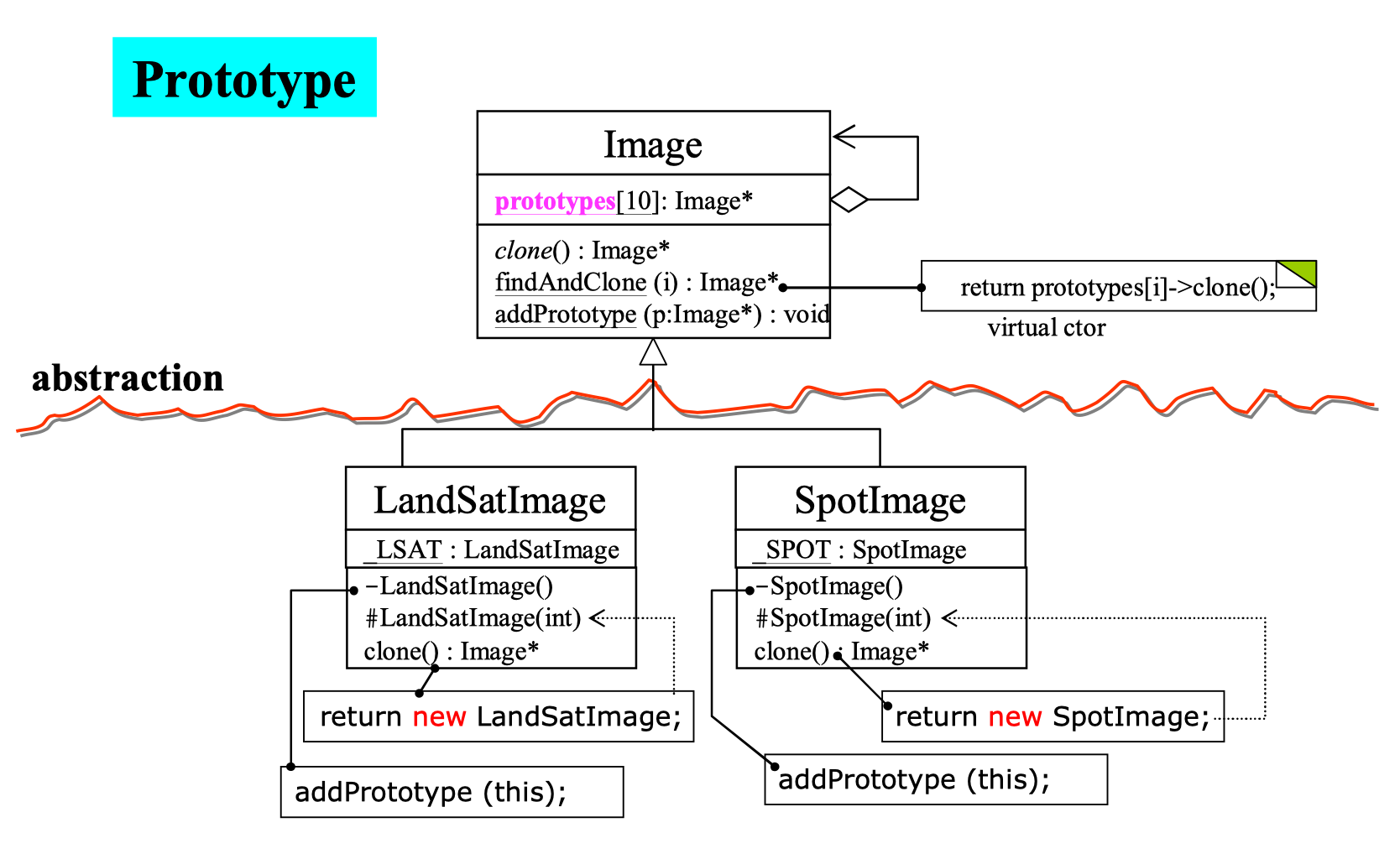
5. Inheritance(继承) with virtual functions(虚函数)
5.1 虚函数和纯虚函数
(1) 成员函数可以分为三类:
- 非虚函数: 你并不希望 derived class(子类) 重新定义(override, 覆写/重写) 它。
- 虚函数: (在函数前添加 virtual):你希望 derived class 重新定义(override, 覆写/重写) 它, 并且它已有默认定义。
- 春旭函数函数: 你希望 derived class 一定要重新定义(override, 覆写/重写)它, 你对它没有默认定义。
class Shape{
virtual void draw() const = 0; // pure virtual
virtual void error(const std::string& msg); // impure virtual
int objectID() const; // non-virtual
};重载(overload)、覆盖( 重写override) 的区别是什么?
overload 重载: 在 C++ 程序中,可以将语义、功能相似的几个函数用同一个名字表示,但参数不同(包括类型、顺序、个数不同)。重载的调用时根据参数列表来决定调用哪一个函数。其特征是:
相同的范围(在同一个类中), 函数名字相同, 参数不同)
override 覆盖: 是指派生类函数覆盖基类函数。覆盖的调用时根绝对象类型的不同决定调用哪一个。特征是:
不同的范围(分别位于派生类与基类); 函数名字相同; 参数相同; 基类函数必须有 virtual 关键字
5.2 模板方法 Template method
借助于虚函数和多态,可以实现模板方法:父类把其中的一个动作写成虚函数,延缓到子类来进行实现,在调用时通过子类进行调用。 这就是著名的 Template method。
// 开发者实现的内容: 对于没有办法写出的 Serialize(), 所以将其定义为虚函数
#include <iostream>
using namespace std;
class CDocument
{
public:
void OnFileOpen(){
// 这是个算法, 每个cout 输出代表一个实际动作
cout << "dialog ..." << endl;
cout << "check file status ... " << endl;
cout << "open file ... " << endl;
Serialize();
cout << "close file ... " << endl;
cout << "update all views ... " << endl;
}
virtual void Serialize() {};
};
// 使用者继承父类,并自己去实现 Serialize() 函数
class CMyDoc: public CDocument
{
public:
virtual void Serilize(){
// 只有应用程序本身才知道如何读取文件
cout << "CMyDoc::Serialize() " << endl;
}
}
int main()
{
CMyDoc myDoc; // 假设对应(File/Open)
myDoc.OnFileOpen();
}6. 虚指针 和 虚表
(1) 只要类有虚函数,其含有成员就有一个虚指针, 指向虚表, 然后在运行时,通过这个虚指针,找到这个虚表,进而调用这个函数
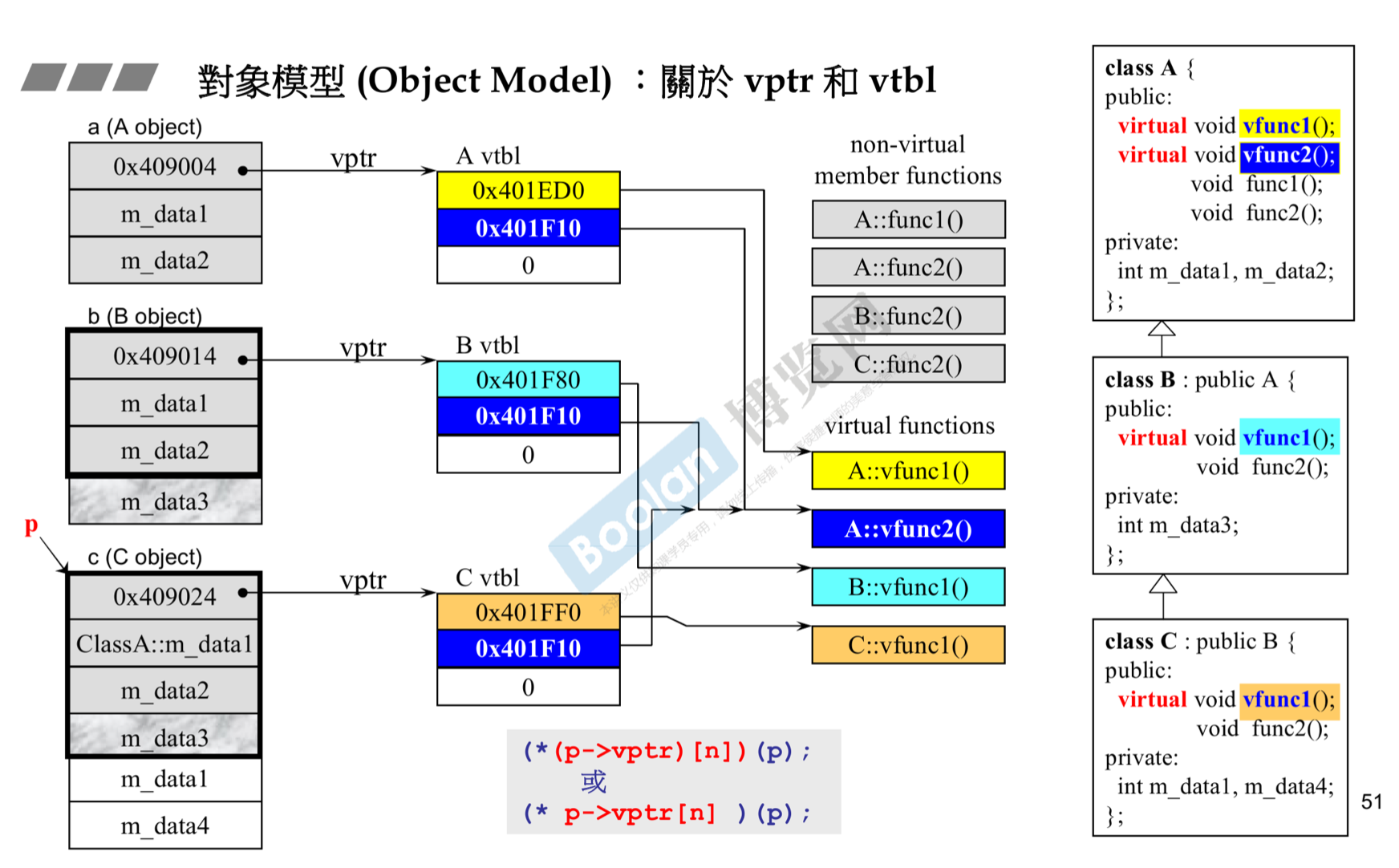
(2) 动态绑定要满足三个条件: 子类成员函数声明为虚函数、指针向上转型、调用虚函数
(3) 动态绑定 与静态绑定的区别:
静态绑定和动态绑定的主要区别在于:在什么时候将函数实现和函数调用关联起来,是在编译期间还是运行期间。
静态绑定是指在编译期间就可以确定函数的调用地址,并产生代码。也就是说函数调用地址是早早绑定的。 其代码直接编译为:
call xxxx动态绑定的函数调用的地址不能在编译期间确定,需要等到运行时才确定,这被叫做延迟绑定。动态绑定往往通过虚函数来实现,虚函数允许派生类重新定义成员函数,而派生类重新定义基类成员函数并实现动态绑定。动态绑定的代码一般编译为
call dword ptr [edx]。这里不再是一个固定的地址,而是通过虚指针找到虚表,然后找到第 n 个函数, 然后将其当做函数指针进行调用。
五. 泛型编程
模板 template
1. 函数模板
template <typename T>
class complex{
....
T re,im;
}
complex<double> c1(2.5,1.5);2. 类模板
template<typename T>
class complex {
public:
complex (T r = 0, T i = 0) : re (r), im (i) { }
complex& operator += (const complex&);
T real () const { return re; }
T imag () const { return im; }
private:
T re, im;
friend complex& __doapl (complex*, const complex&);
};
// 调用
{
complex<double> c1(2.5,1.5); c2(2,6);
complex<int> ...
}
3. 函数模板
class stone{
public:
stone(int w, int h, int we)
: _w(w), _h(h), _weight(we) { }
bool operator< (const stone& rhs) const{
return _weight < rhs._weight;
}
private:
int _w, _h, _weight;
};
template <class T>
inline const T& min(const T& a, const T& b){
return b < a ? b : a; // 需要类 T 对 < 进行函数重载
}
// 调用
stone r1(2,3), r2(3,3), r3;
r3 = min(r1, r2); // 参数推导的结果,T 为 stone,于是调用 stone::operator <六、C++11
1. namespace
通过 namespace 将代码包起来,防止冲突
当使用的时候可以有两种:
- using directive: using namespace std; cin; cout
- usding declaration: std::cout; std::cin;
2. auto
list<string> c:
auto ite = find(c.begin(), c.end(), target);3. ranged-base for
for(decl : coll){
statement
}
// 例如
for(int i: {1, 2, 3, 4, 5, 6, 7, 8}){
cout << i << endl;
}
vector<double> vec;
...
for(auto elem : vec){
cout << elem << endl; // pass by value
}
for(auto & elem: vec){ // pass by reference
elem *= 3;
}4. variadic templates
七. STL 容器
八、常见问题 ?
1. class 和 struct 的区别?
class 和 struct 的区别在于 class 默认的成员是 private,而 struct 默认的成员是 public 类型的
2. "xx" 和 <xx> 的引用方式的区别!
<> 先去系统目录中找头文件,如果没有在到当前目录下找。所以像标准的头文件 stdio.h、stdlib.h等用这个方法。
而 " " 首先在当前目录下寻找,如果找不到,再到系统目录中寻找。 这个用于include自定义的头文件,让系统优先使用当前目录中定义的
3. private、public 和 protected 的继承体系?
4. 单例模式 (Singleton) 中需要将 constructor 放在 private 中, 试实现一个单例模式?
5. 从空间大小、碎片问题、生成方向、分配方式和分配效率对栈和堆进行比较:
(1) 空间大小:一般来讲在 32 位系统下,堆内存可以达到 4G 的空间。但是对于栈来讲,一般都是有一定的空间大小的,例如,在 VC6 下面,默认的栈空间大小是 1M(好像是,记不清楚了)。
(2) 碎片问题:对于堆来讲,频繁的 new/delete 势必会造成内存空间的不连续,从而造成大量的碎片,使程序效率降低。对于栈来讲,则不会存在这个问题,因为栈是先进后出的队列,以至于永远都不可能有一个内存块从栈中间弹出。
(3) 生长方向:对于堆来讲,生长方向是向上的,也就是向着内存地址增加的方向;对于栈来讲,它的生长方向是向下的,是向着内存地址减小的方向增长。
(4) 分配方式:堆都是动态分配的,没有静态分配的堆。栈有 2 种分配方式:静态分配和动态分配。静态分配是编译器完成的,比如局部变量的分配。动态分配由 alloca 函数进行分配,但是栈的动态分配和堆是不同的,他的动态分配是由编译器进行释放,无需我们手工实现。
(5) 分配效率:栈是机器系统提供的数据结构,计算机会在底层对栈提供支持:分配专门的寄存器存放栈的地址,压栈出栈都有专门的指令执行,这就决定了栈的效率比较高。堆则是 C/C++函数库提供的,它的机制很复杂,堆的效率比栈要低得多
TBD
四种类型转换:static_cast, dynamic_cast, const_cast, reinterpret_cast
模板特化、偏特化,萃取 traits 技巧
继承、虚继承、菱形继承等
volatile、extern
智能指针原理:引用计数、RAII(资源获取即初始化)思想
智能指针使用:shared_ptr、weak_ptr、unique_ptr等
C++11 部分新特性,比如右值引用、完美转发等
转换函数
类型转换运算符(conversion operator) 是类的一种特殊成员函数, 它负责将一个类类型的值转换未其他类型。 其一般形式如下所示:
operator type() const; 其中 type 表示某种类型。 类型转换运算符可以面向任意类型进行定义, 只要该类型能够作为函数的返回类型。 因此我们不允许转换成数组或者函数类型, 但允许转换成指针或者引用类型。
类型转换运算符既没有显式的返回类型, 也没有形参, 而且必须定义成类的成员函数。 类型转换运算符通常不应该改变待转换对象的内容, 因此, 类型转换运算符一般被定义成 const 成员。
class Fraction
{
public:
Fraction(int num, int den = 1)
: m_numerator(num), m_denominator(den) {}
operator double() const{
return (double) (m_numerator / m_denominator);
}
private:
int m_numerator; // 分子
int m_denominator; // 分母
}
// 调用
Fraction f(3, 5);
double d = 4 + f; // 调用 operator double() 将 f 转换为 0.6explicit
当我们使用 explicit 关键字声明构造函数时, 它只能以直接初始化的形式使用。 而且, 编译器将不会再自动转换过程中使用该构造函数。 考虑如下应用场景:
class Fraction
{
public:
Fraction(int num, int den = 1)
: m_numerator(num), m_denominator(den) {}
operator double() const{
return (double) (m_numerator / m_denominator);
}
private:
int m_numerator; // 分子
int m_denominator; // 分母
}
// 调用
Fraction f(3, 5);
double d = f + 4; // Error: ambiguous
// 产生二义性的原因:
// 可以使用构造函数,将 4 转换为 Fraction, 然后两者进行相加
// 也可以将 f 转换为 double, 然后两个 double 相加
// 可以使用 explicit 进行声明, 在构造函数之前添加 explicit 关键字, 然后进行隐式转换。5. 智能指针
智能指针的本质是类模板,主要是为了我们更加方便(也更加安全的)使用动态内存,它的行为类似于常规指针,重要的区别是它负责自动释放所指向的对象。
template<class T>
class shared_ptr{
public:
T& operator*() const { return * px; }
T* operator->() const {return px; }
shared_ptr(T*p): px(p) {}
private:
T* px;
long * pn;
...
}本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!