transformer-for-vision-task
transformer 是一种新提出的神经网络组件, 主要利用注意力机制来提取内在特征。本文主要介绍了视觉方向上 transformer 的应用。
本文先从 transformer 的基本组件 self-attention 入手, 介绍 self-attention 机制并逐渐展开至 transformer 模型。 然后在 计算机视觉领域挑选了四个重要的模型:ViT(classification)、DETR(detection)、D-DETR(detection) 和 TTSR(super resolution) 进行分享。最后阐述一些高效的 transformer 机制。
1. transformer 的提出 : attention is all your need
transformer 在 NLP 领域应用有三个重要的节点:
- 2017年06月:首次完全基于注意力机制的 transformer, 并将其用于机器翻译和英语分析任务,发表于论文《 Attention is all your need 》。这是 transformer 的起点, 也是本文介绍的重点。
- 2018年10月:引入了一种新的语言表示模型,称为 BERT, 通过联合调节左右上下文,从未标记的文本中预训练一个 transformer。
- 2020年05月: GPT-3诞生:在 45TB 的纯文本数据上预训练了一个具有 1750 亿超参数的巨型 transformer 模型 GPT-3。这个模型在不进行微调的情况下,在不同的自然语言任务上实现了强大的性能。
1.1 vanilla transformer
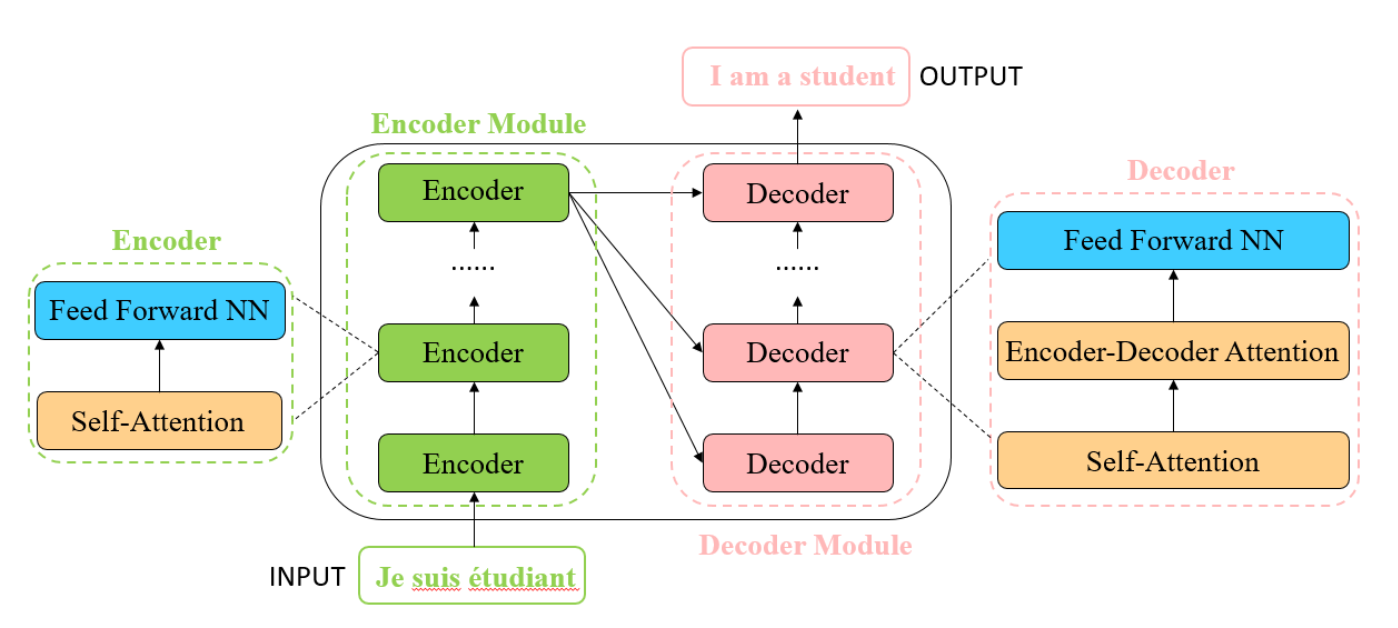
原始的 transformer 用于进行机器翻译任务, 其模型如下图所示, 它由一系列的 encoder 和 decoder 组成。 每个 encoder 由 self-attention 层和 feed forward nn 组成, 每个 decoder 则是由 self-attention、encoder-decoder attention 和 feed forward nn 组成。 在输入之前先将句子中的每个单词 embedding 为固定维度的向量, 然后经过 encoder-decoder 进行编解码,最后将输出的向量重新编码为一个 个单词组成句子, 从而完成翻译任务。图中的 encoder 中的 Self-Attention 和 decoder 中的 Encoder-Decode Attention 和几乎相同, 只是输入有所差别。
1.2 self attention layer
参考实现: http://nlp.seas.harvard.edu/2018/04/03/attention.html
self attention 机制可以描述为将一个查询 query 和一组键值对 key-val 映射到一个输出 output,其中 query、key、val 和 output 都是向量。输出 output 是以值的加权和来计算的,其中分配给每个值的权重 weight 是由 query 与对应 key 的相似度计算出来的。其具体的操作如下所示:
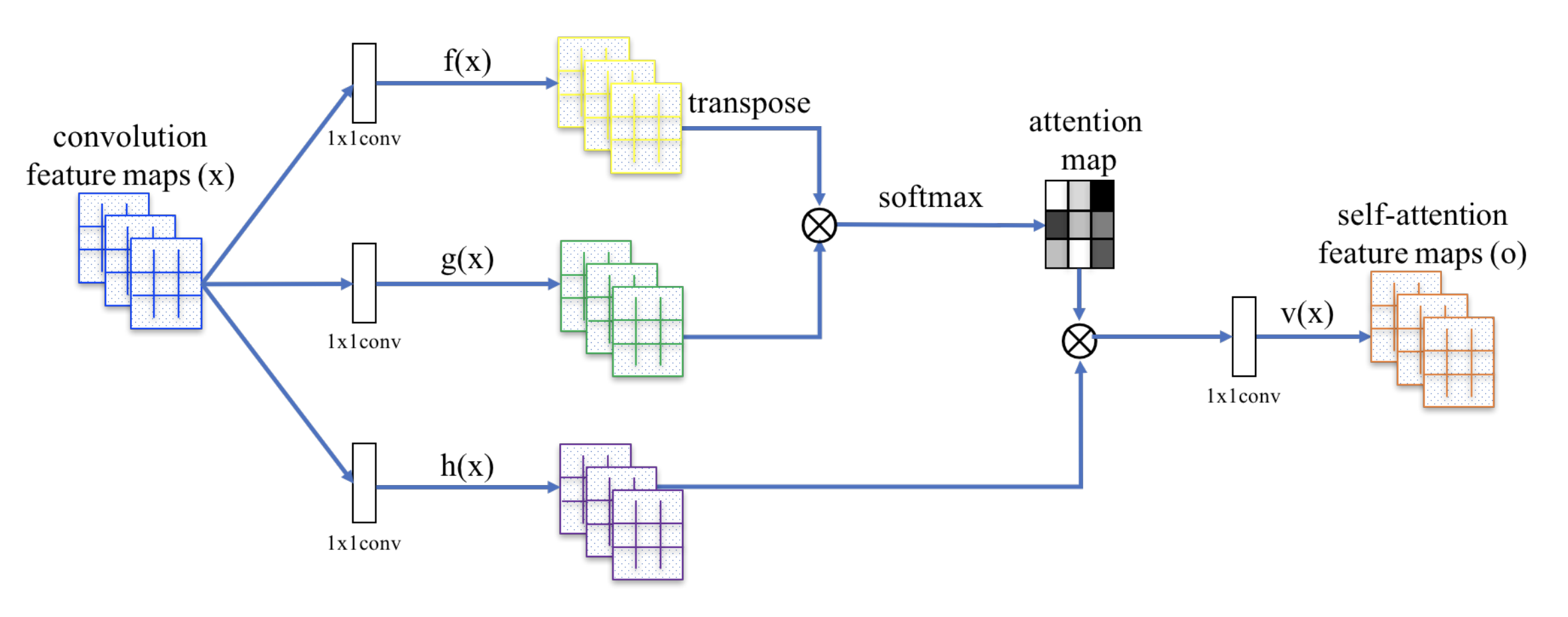
在 self-attention 层, 首先将输入 vector 转化为三个不同的 vector, 这三个向量被称为 query vector(to match others) , key vector(to be matched) 和 value vector(information to be extracted)。将这三个向量打包为 Q、V、K 三个矩阵。在此之后,执行如下步骤:
Setp 1:计算不同输入之间的分数, 这里记为: $S = Q \cdot K^T$
Step 2:梯度标准化:$S_n = S / \sqrt{d_K}$
Step 3: 借助 softmax 将分数转化概率 $P = softmax(S_n)$
Step 4: 将 P 作为权重,乘以 V 矩阵 $Z = V \cdot P$
上述的处理过程可以被统一到如下的公式中:
该公式的解释很简单。 第1步计算两个不同向量之间的分数,该分数的含义是当前位置的单词和其他单词的关联程度。第 2 步对分数进行规范化处理,主要是使其有更稳定的梯度(点积结果较大,输入 softmax 的值较大,从而导致 梯度较小),以达到更好的训练效果。第 3 步将分数转变成概率。第四步是将每个值向量乘以概率,概率较大的向量会被下面几层更加注意(attention)。 一个简单的 self-attention 实现如下:
def attention(query, key, value, mask=None, dropout=0.0):
d_k = query.size(-1)
scores = torch.matmul(query, key.transpose(-2, -1)) / math.sqrt(d_k)
if mask is not None:
scores = scores.masked_fill(mask == 0, -1e9)
p_attn = F.softmax(scores, dim = -1)
# (Dropout described below)
p_attn = F.dropout(p_attn, p=dropout)
return torch.matmul(p_attn, value), p_attn 解码器中的 Encoder-Decode attention 和编码器中的 Self-Attention 几乎相同。不同的是矩阵 K 和 矩阵 V 来自于 编码器, 而 Q 来自上一层输出。
1.2 Multi-Head Attention
为了提升 self-attention 层的性能,加入了一种叫做 multi-head attention 的机制,进一步完善了 self-attention 层。考虑我们在浏览句子的时候,对于一个给定的参考词,往往需要同时关注其他几个词, 而单头的注意力机制限定了对某一个特定位置的关注能力。多头注意力机制通过赋予注意力层不同的表示子空间来实现的。具体来说,对不同的头使用不同的查询、键和值矩阵,由于随机初始化,它们可以在训练后将输入向量投射到不同的表示子空间。
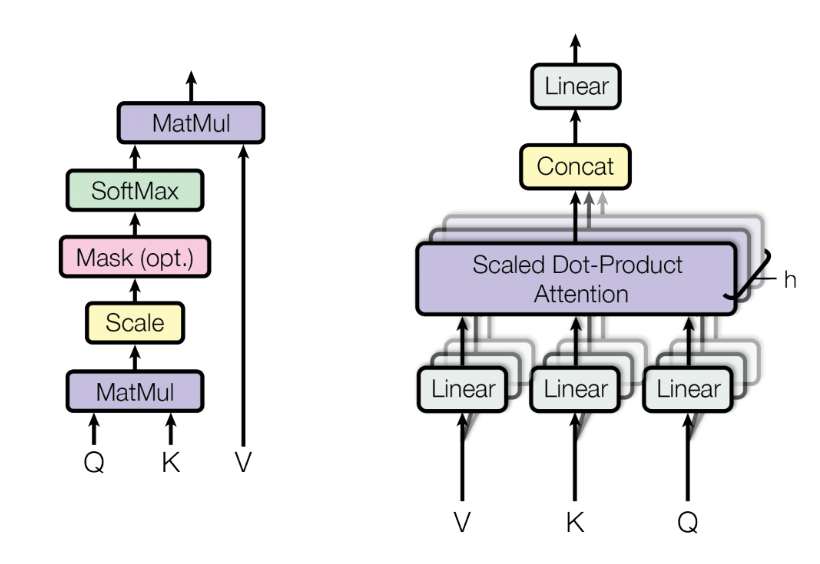
在具体实现上, 通过线性函数将单个的 key, query 和 value 分裂为多个, 然后对应的 key, value 和 query 分别进行处理即可。最后将分裂的多个节点 concat, 并通过线性函数进行结合节课。
class MultiHeadedAttention(nn.Module):
def __init__(self, h, d_model, dropout=0.1):
"Take in model size and number of heads."
super(MultiHeadedAttention, self).__init__()
assert d_model % h == 0
# We assume d_v always equals d_k
self.d_k = d_model // h
self.h = h
self.linears = clones(nn.Linear(d_model, d_model), 4)
self.attn = None
self.dropout = nn.Dropout(p=dropout)
def forward(self, query, key, value, mask=None):
"Implements Figure 2"
if mask is not None:
# Same mask applied to all h heads.
mask = mask.unsqueeze(1)
nbatches = query.size(0)
# 1) Do all the linear projections in batch from d_model => h x d_k
query, key, value = \
[l(x).view(nbatches, -1, self.h, self.d_k).transpose(1, 2)
for l, x in zip(self.linears, (query, key, value))]
# 2) Apply attention on all the projected vectors in batch.
x, self.attn = attention(query, key, value, mask=mask,
dropout=self.dropout)
# 3) "Concat" using a view and apply a final linear.
x = x.transpose(1, 2).contiguous() \
.view(nbatches, -1, self.h * self.d_k)
return self.linears[-1](x)1.3 position encoding
需要注意的是,上述过程与每个词的位置无关,因此自注意力层缺乏捕捉句子中词的位置信息的能力。为了解决这个问题,在原始输入嵌入的基础上,增加一个维度为 $d_{model}$ 的位置编码,以得到单词的最终输入向量。具体来说,位置编码的公式如下:
这里的 $pos$ 表示单词在句子中的位置, $i$ 则表示当前编码的维度。
1.4 Other Parts in Transformer
论文 《attentionis all your need》 的 encoder-decoder 模型如下所示, 接下来介绍一下其他的组成部分:
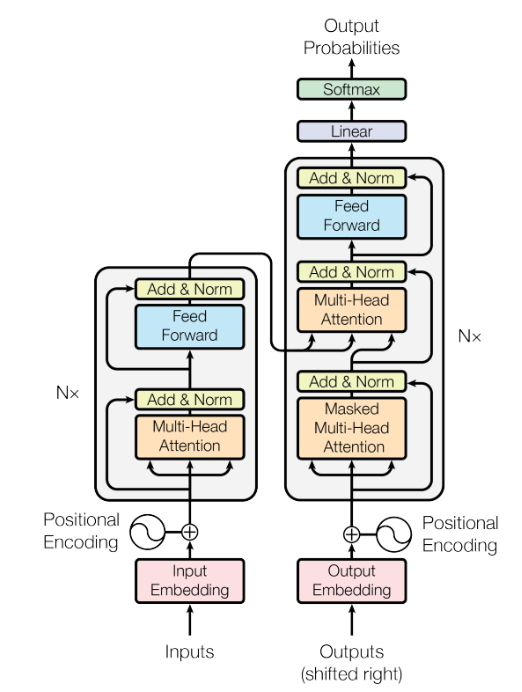
Residual in the encoder and decoder: 如上图所示, 在编码器和解码器的每个子层中都增加了一个残差连接,以加强信息的流动,获得更好的性能。之后再进行 layer normalization。上述运算可以描述为:
需要注意的是,这里用 $X$ 作为自关注层的输入,因为 query、key 和 value 矩阵 Q、K 和 V 都是由同一个输入矩阵 $X$ 导出的。
Feed-forward neural network:feed-forward NN 是由两个线性变换层和它们内部的 ReLU 激活函数组成的,该运算可以描述为:
其中 $W1$和 $W2$ 是两个线性变换层的两个参数矩阵,$\sigma$ 代表 ReLU激活函数。
Final layer in decoder:decoder 的最后一层旨在将输出的向量重新编码为一个字。它是由一个线性层和一个softmax 层实现的。线性层将向量投射成一个 $d{word}$ 维度的 logits 向量,其中 $d{word}$ 是词汇中的单词数。然后,用 softmax 层将 logits 向量转化为概率。
2. Computer Vision 中的 transformer
计算机视觉任务中使用的大多数 transformer 都利用了 transformer 的 encoder 模块。简而言之,它可以被视为一种新的特征选择器,它与卷积神经网络(CNNs)和递归神经网络(RNNs)是不同的。
- 与 CNN只关注局部特征相比,transformer 能够捕捉长距离特征,这意味着全局信息可以很容易地通过 transformer 得到。
- 与 RNN 的隐藏状态必须依次计算相比,transformer 的效率更高,因为自注意层和全连接层的输出可以并行计算,容易加速。
相比于 NLP 输入的一维序列来说, CV 领域的数据则是二维的图像矩阵。 这是两者的区别所在, 所以在最初的研究中, 主要的手段就是考虑怎么将图像转换为训练输入 transformer, 得到输出。接下来,我们从分类、检测、超分三个领域分别选取一到两个模型,对计算机视觉领域的 transformer 进行讲解。
(1) ViT for classification
着眼于分类任务, 将图片切分为贴片序列, 将纯 transformer 直接应用于 贴片 序列
这篇论文是比较早的将 transformer 机制应用到 classification 领域的文章。首先,对原始图片进行分块,展平成为序列,然后将其输入进原始的 Transformer 模型的编码器 Encoder 部分,最后连接一个全连接层对图片进行分类。
github: https://github.com/lucidrains/vit-pytorch
Paper: An Image is worth 16X16 words: transformers for image recognition at scale
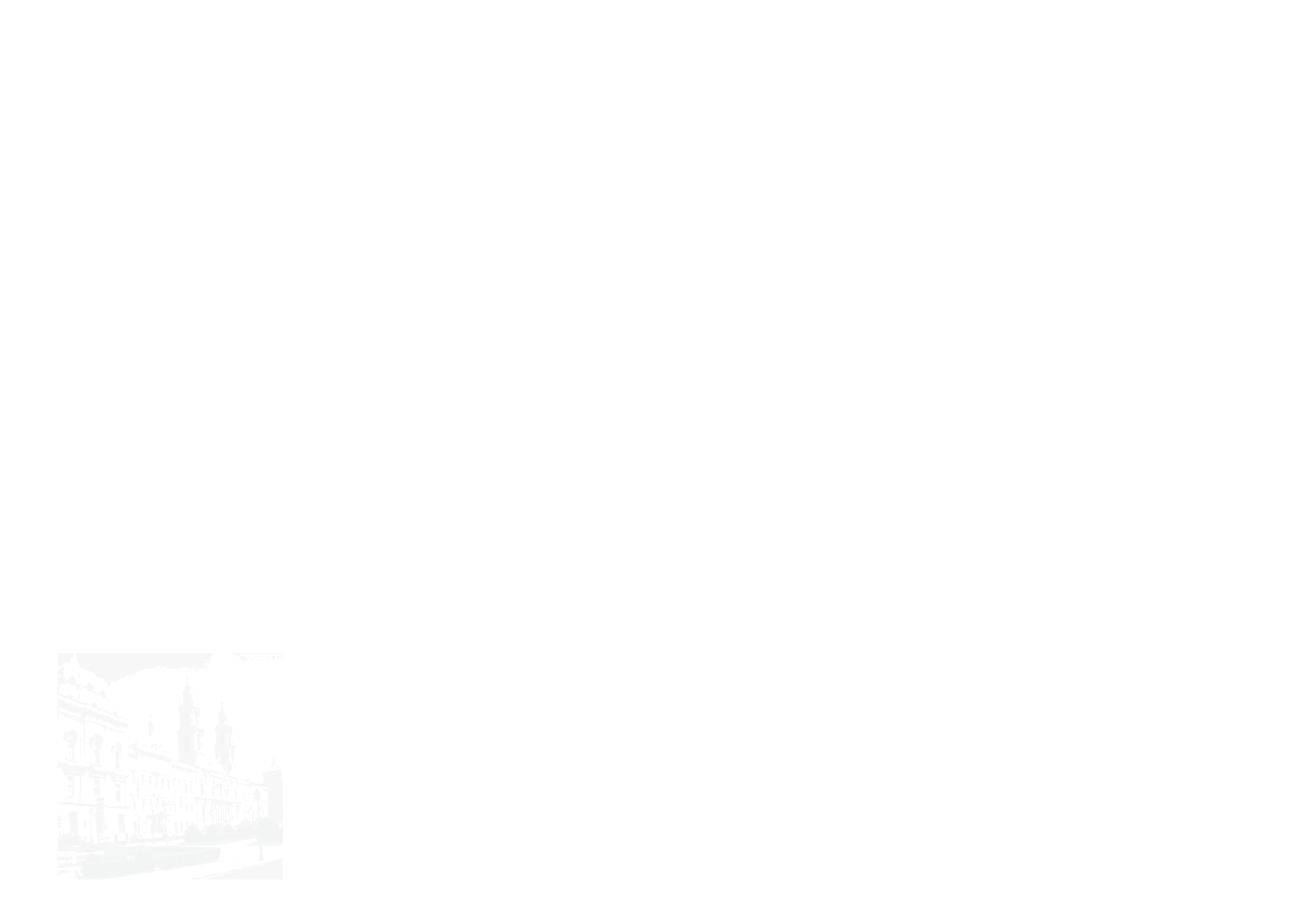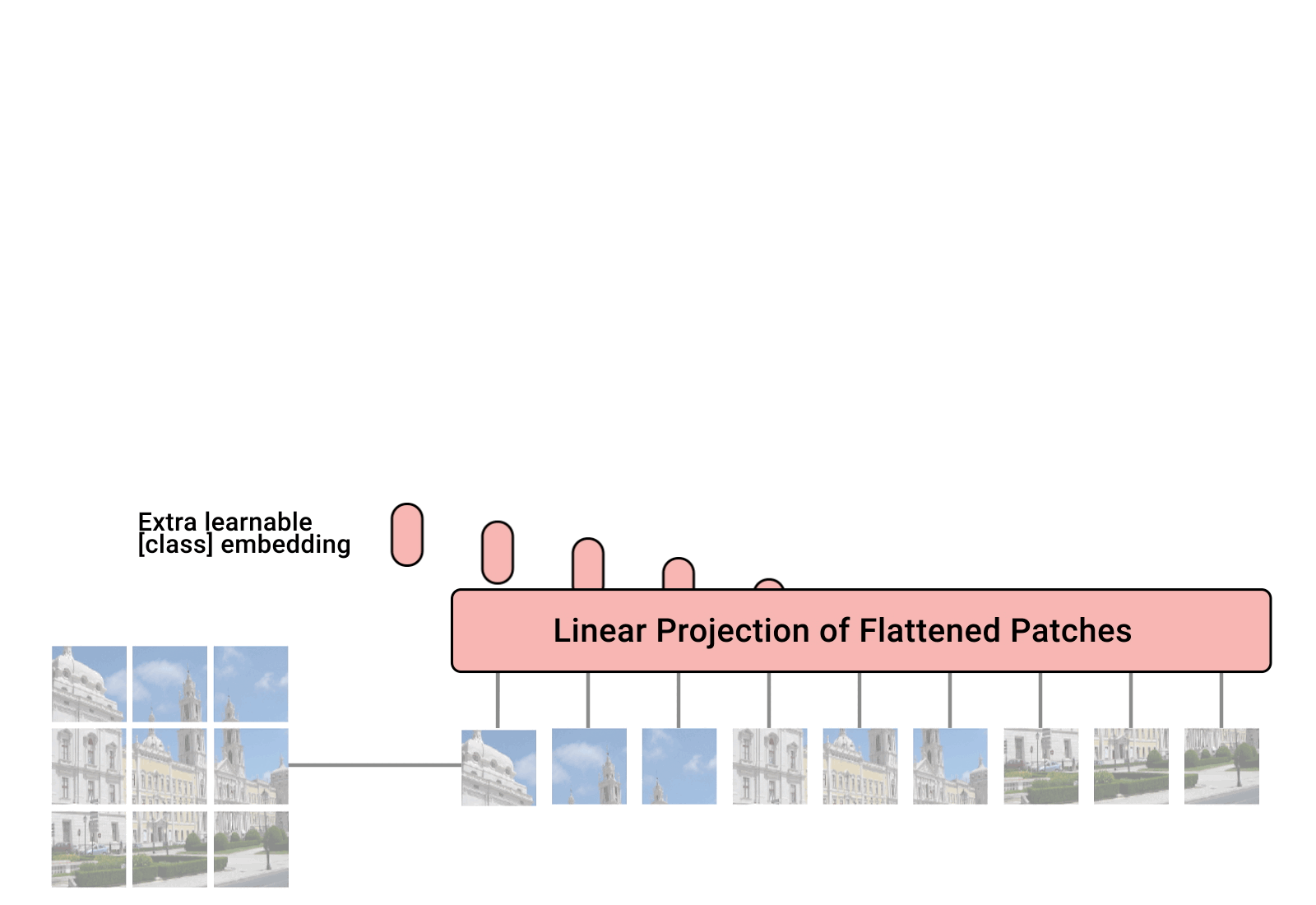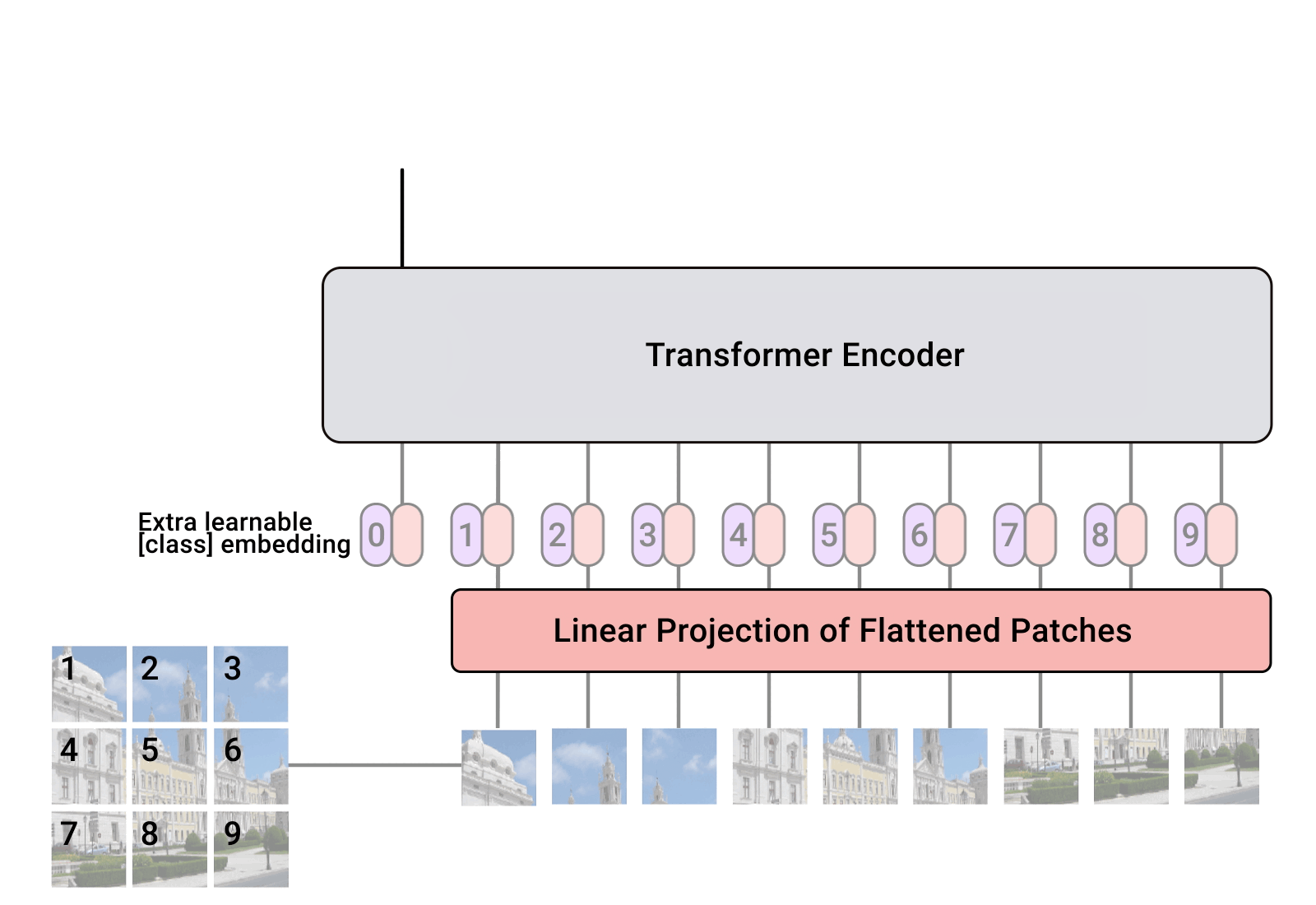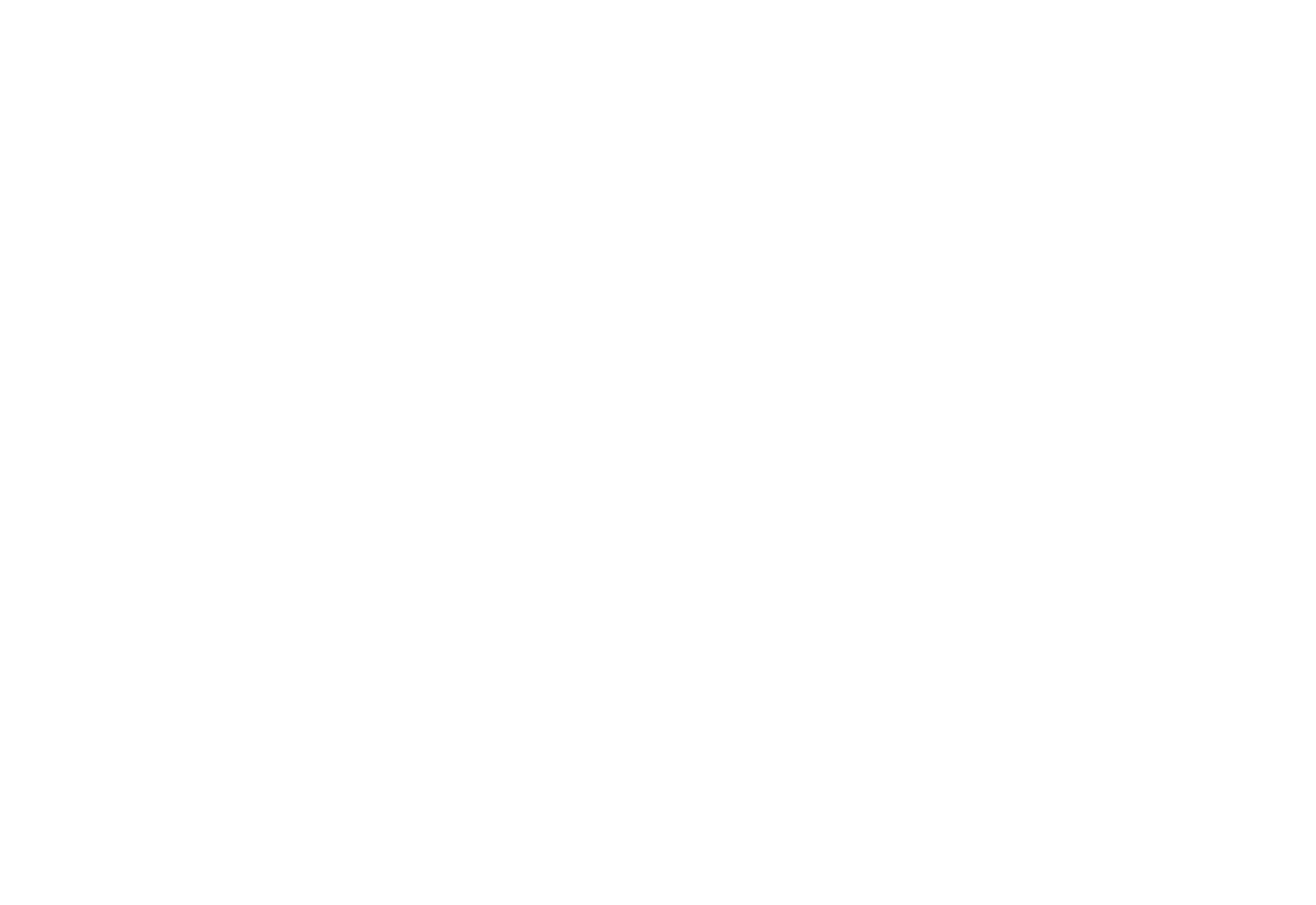
数据处理部分:原始输入的图片数据时 HWC, 我们先对图片进行分块,再进行展平。 假设每个块的长宽为(P, P), 那么分块的数目为 N = H W / (P P)。 图中的 N = 9, 论文中的 P = 16。对每个图片块展平成一维向量, 每个向量大小为 P P C, 总的输入变换为 N (P^2 C)。
x = rearrange(img, 'b c (h p1) (w p2) -> b (h w) (p1 p2 c)', p1 = p, p2 = p) # use einops的拓展包Patch Embedding:使用全连接层对每一个向量都做一个线性变换, 将向量的维度压缩为D。
self.patch_to_embedding = nn.Linear(patch_dim, dim)cls token + Positional Encoding:
原始的 Transformer 引入了一个 Positional encoding 来加入序列的位置信息,同样在这里也引入了pos_embedding,是用一个可训练的变量替代。
self.pos_embedding = nn.Parameter(torch.randn(1, num_patches + 1, dim)) x += self.pos_embedding[:, :(n + 1)]ViT 在 Transformer 输入序列前增加了一个额外可学习的 [class] 标记位,并且该位置的 Transformer Encoder 输出作为图像特征。
self.cls_token = nn.Parameter(torch.randn(1, 1, dim)) cls_tokens = repeat(self.cls_token, '() n d -> b n d', b = b) x = torch.cat((cls_tokens, x), dim=1) # 添加一个
transformer:
class Transformer(nn.Module): # 堆叠多层的 Attention 模块 和 Feed Fordward def __init__(self, dim, depth, heads, mlp_dim, dropout): super().__init__() self.layers = nn.ModuleList([]) for _ in range(depth): self.layers.append(nn.ModuleList([ Residual(PreNorm(dim, Attention(dim, heads = heads, dropout = dropout))), Residual(PreNorm(dim, FeedForward(dim, mlp_dim, dropout = dropout))) ])) def forward(self, x, mask = None): for attn, ff in self.layers: x = attn(x, mask = mask) x = ff(x) return xmlp_head: 使用 layernorm 和 全连接 实现
self.mlp_head = nn.Sequential( nn.LayerNorm(dim), nn.Linear(dim, num_classes) )
(2) DETR for detection
DETR 的网络结构如下所示:

首先用 CNN 将输入图像 embedding 成一个二维表征。 并将二维表征转换为一维表征并结合 positional encoding 一起送入 transformer 进行 encoder-decoder。然后将 decoder 得到的每个 output embedding 传递到一个共享的前馈网络(FFN)。最后使用 set loss function 作为监督信号来进行端到端训练,然后同时预测所有目标。三个创新点:(1)使用 transformer (2) 使用 set loss 并抛弃了 anchor 的概念和 nms (3) end2end。 虽说论文对标的是 faster rcnn。 但是采用新的方法去探索目标检测, 还是值得肯定的。
1. backbone
CNN backbone 只用于提取特征。CNN backbone 处理 $X_{img} \in R^{N 3H_0W_0}$ 维的图像,把它转换为 $ F \in R^{N C H W}$ 维的feature map(一般来说 N = 2048 或 N = 256, H = H_0 / 32,W = W_0 / 32)。
通道数压缩: 用 1x1 卷积, 将 channels 数量从 C 压缩, 得到一个 $z_0 \in R^{N d H W}$。并将其 reshape 为 $N, HW, d$ 维度的 feature map。
位置编码: 在得到 $z_0 \in R^{N d H * W}$ 之后, 需要进行位置编码。 需要注意一点的是, 原版的 transformer 只考虑了 $x$ 方向的位置编码, 但是 DETR 考虑 $xy$ 两个方向的编码。另一点不同的是, 原版的 transformer 只在 encoder 输入处进行了 位置编码, 但是 DETR 在 encoder 的每一个 Multi-head self-attention 之前都使用了 positional encoding, 且只对 query 和 key 使用了 positional encoding。
2. encoder-decoder
这里直接套用了 NLP 上的 transformer,有些许不同:
位置向量编码要加入到 每个 encoder layer 中。
decoder 的输入添加了 object queries。Object queries是一个维度为 (100, b, 256) 维的张量,数值类型是nn.Embedding,说明这个张量是可以学习的,即:我们的Object queries是可学习的。 Object queries矩阵内部通过学习建模了 100 个物体之间的全局关系,例如房间里面的桌子旁边( A 类)一般是放椅子( B 类),而不会是放一头大象( C 类),那么在推理时候就可以利用该全局注意力更好的进行解码预测输出。
3. prediction heads
prediction 由 3 层 perceptron 和一层 linear projection 组成。FFN 预测出 box 的归一化 xywh 和 classes。DETR 预测的是固定数量的 N 个 box 的集合,并且 N 通常比实际目标数要大的多,所以使用一个额外的空类来表示预测得到的 box 不存在目标。 最终 DETR 输出的张量的维度为 (b, 100, class + 1) 和 (b, 100, 4)。这个 100 是个预先设定的, 远大于图中目标总数的数字。 通过这两个张量,就可以解码出对应的检测框和分类。
4. bipartite loss
使用匈牙利算法来寻找 prediction box 和 image object 匹配的总 cost 最小的二分图匹配方案。首先定义每对 prediction box 和 image object 的 cost 损失:
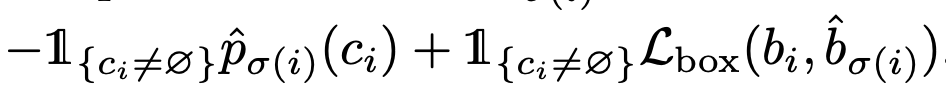
简单解释一下, 如果当 image object 为空 时, 这对 cost 为 零, 当 image object 不为零时, 当(预测相同的)类别概率越大,bbox 的差距越小时, 配对的 cost 越小。 这里的 $L_{box}$ 定义为:
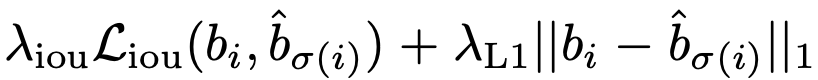
我们就完全定义好了每对 prediction box 和 image object 配对时的cost。再利用匈牙利算法即可得到二分图最优匹配。 基于这个最优匹配,来计算 set prediction loss,即评价 transformer 生成这些 prediction boxes 的效果好坏。Set prediction loss 计算公式如下:
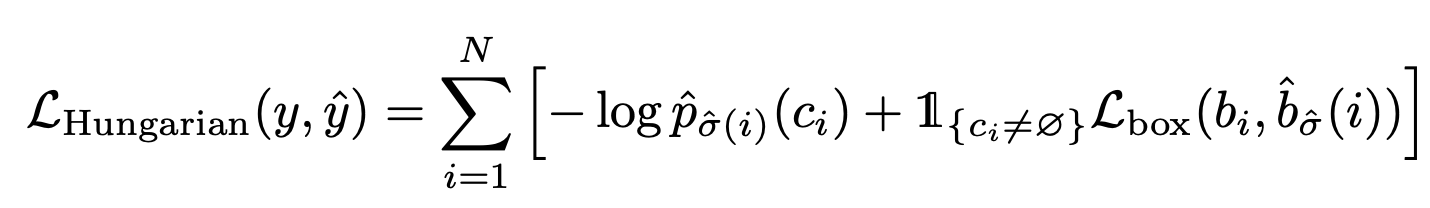
(3) IPT
不同于高层视觉语义任务的目标是进行特征抽取,底层视觉任务的输入和输出均为图像。除超分辨率任务之外,大多数底层视觉任务的输入和输出维度相同。相比于高层视觉任务,输入和输出维度匹配这一特性使底层视觉任务更适合由 Transformer 处理。 具体而言,研究者在特征图处理阶段引入 Transformer 模块,而图像维度匹配则交给了头结构与尾结构,如下图所示:
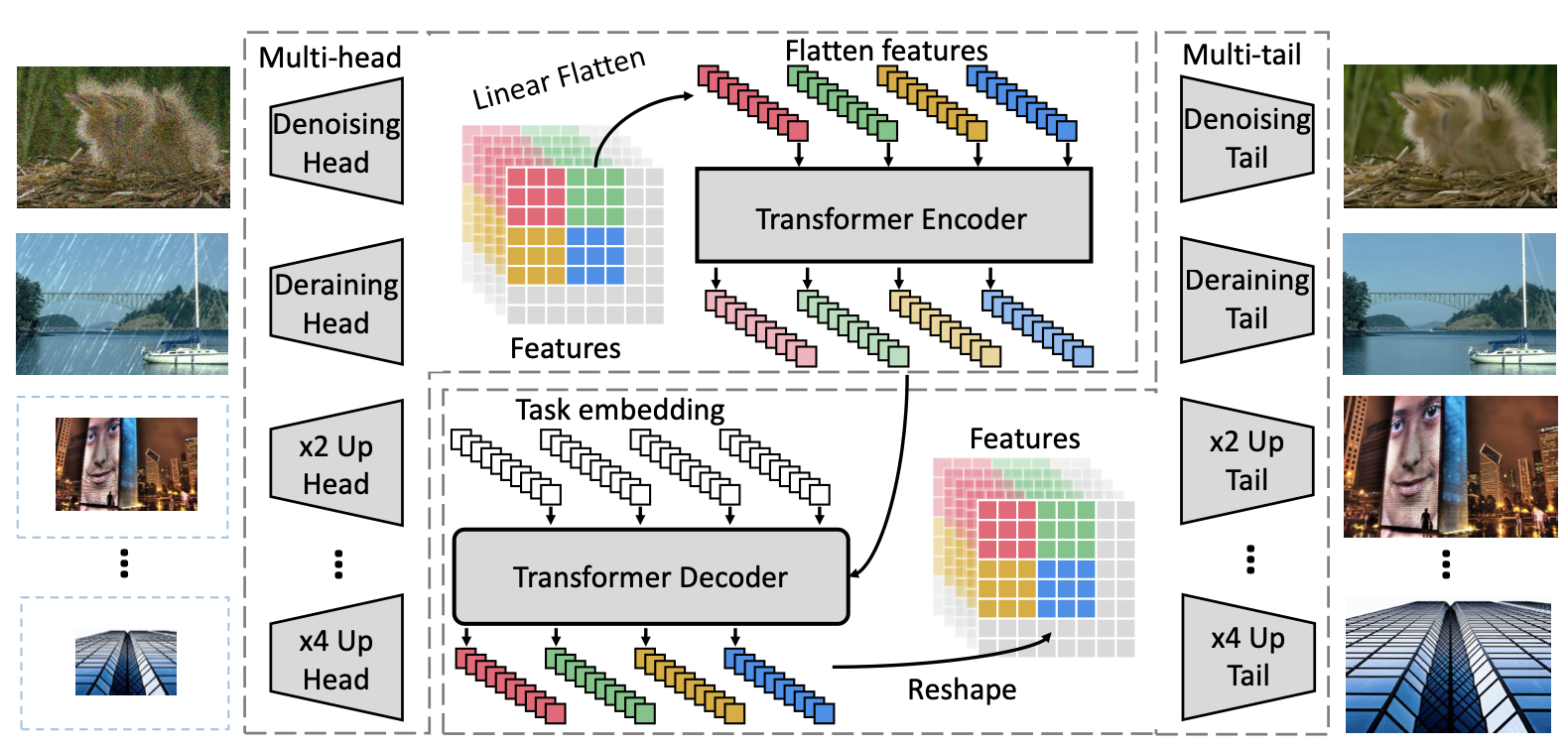
(1) 首先将图片经过一个头结构变换为特征图:
(2) 对特征图进行切块与拉平操作。首先按照 P×P 的大小将特征图切割成 N 块,每一个特征块再被拉平为维度为 $P^2×C$ 的向量,这里的处理类似于 ViT 中的操作。
这样一来,每个特征向量可以等同于一个「单词」,即可送入 Transformer 进行处理,得到维度相同的输出特征:
(3) 这些输出特征再经过整形和拼接操作,还原为与输入相同维度的特征图。如此处理得到的特征图会被送入一个尾结构,被解码为目标图像。
头结构和尾结构负责维度变换,transformer 模块可以专心地做特征处理。这使得多任务的扩展变得简单:对于不同的任务,只需要增加新的头结构与尾结构即可,多种任务之间的 transformer 模块是共享的。为了适应多任务,研究者在 Transformer 的解码模块中加入了一个可学习的任务编码。
transformer 的成功离不开大量数据预训练带来的性能提升。在这篇论文中,针对底层视觉任务,研究者使用 ImageNet 数据集生成多种退化图像,构成多种底层视觉任务训练集。利用这些人工合成的数据,配以对应任务的多头多尾结构,多个任务的训练数据同时进行训练。训练时的损失函数则使用 L1 损失作为监督损失函数, 使用特征块之间的相关性自监督损失函数
3. efficient transformer
高效的 transformer
一些思考和待解决的问题
4. 参考资料
- 综述 A Survey on Visual Transformer https://arxiv.org/abs/2012.12556
- 综述 Transformers in Vision: A Survey https://arxiv.org/pdf/2101.01169.pdf
- The Annotated Transformer:http://nlp.seas.harvard.edu/2018/04/03/attention.html
- https://mp.weixin.qq.com/s/cY0IkHTpxS6x6cqsueXZIg
- hongyi Lee transformer lecture https://www.bilibili.com/video/BV1CK4y1r7AA
- Efficient Transformers: A Survey https://arxiv.org/pdf/2009.06732.pdf
- https://zhuanlan.zhihu.com/p/266069794
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!