network-pruning
模型剪枝的相关工作记录
神经网络剪枝是指裁减掉网络中冗余的节点或参数,减少参数量,从而降低模型复杂度, 加快推理速度。 LeCun 于上世纪 90年代首次提出将剪枝应用于神经网络的压缩, 并论证其有效性。一个典型的网络剪枝过程如下所示, 其中最重要的是对节点或者参数重要性的评估。

剪枝可以分为结构化剪枝和非结构化剪枝。在非结构化剪枝中, 直接将参数置零,并没有进行剪枝, 通常需要搭配特定的硬件。结构化剪枝则是指在 filter 层面,通道层面,或者 shape 层面的剪枝, 直接删除相关参数,可以运行在通用的硬件设备上。 本文主要关注于结构化剪枝的相关工作,较为典型的工作梳理如下:
一. 解决方案
1. 基于度量
(1) 基于权重
Pruning Filters for Efficient ConvNets 🌟
以 Filter 的 L1 norm 作为衡量标准
Filter pruning via geometric median for deep convolutional neural networks acceleration 🌟
以距离卷积核的几何中心的远近作为衡量标准。 对于神经网络中的某一层,计算所有 filter 的几何中心 (geometric median, GM), 该几何中心附近的 filter 可以认为是冗余的, 可以将其移除。
SFP Soft filter pruning
利用卷积核的 l2 norm 作为衡量标准, 进行软剪枝
Learning both Weights and Connections for Efficient Neural Networks —— no structured prune: weight
(2) feature map
APoZ: Network trimming: A data-driven neuron pruning approach towards efficient deep architectures
作者定义了 APoZ(Average Percentage of Zeros) 来衡量每一个 filter 中激活为 0 的值的数量,并以此作为 filter 是否重要的标准
HRank 🌟
以 feature map 的秩作为衡量标准。 对 feature map 求秩并进行排序, 秩越小所含信息量越小,其重要性越低。根据秩的大小移除 feature map 对应的卷积核。 最后进行微调。
(3)loss func
Pruning Convolutional Neural Networks for Resource Efficient Inference ZAS
评测修剪网络参数引起的损失函数的变化
2. 基于重建误差
- Channel pruning for accelerating very deep neural networks
衡量标准: 通过最小化裁剪后特征图和裁剪前特征图之间的误差
ThiNet (Luo et al., 2017) 🌟
衡量标准: 用输入子集代替原来的输入得到输出的相似度
3. 稀疏化
- (SSL) Learning Structured Sparsity in Deep Neural Networks 🌟
使用 group Lasso 给损失函数加入相应的惩罚,进行结构化稀疏
(Network Slimming) l1 norm: bn gamma 🌟
利用 BN 层中的 γ 作为缩放因子,在训练过程当中来衡量 channel 的重要性,将不重要的 channel 进行删减,达到压缩模型大小,提升运算速度的效果。如下图所示,左边为训练当中的模型,中间一列是 scaling factors,也就是 BN 层当中的缩放因子 γ,当 γ 较小时(如图中0.001, 0.003),所对应的 channel 就会被删减,得到右边所示的模型。
4. prune + nas
AMC:AutoML for Model Compression and Acceleration on Mobile Devices 🌟
将强化学习引入剪枝,使用 nas 进行网络压缩和加速
AutoSlim:Towards One-Shot Architecture Search for Channel Numbers
先训练出一个slimmable 模型,然后通过贪心的方式逐步对网络进行裁剪。
Network Pruning via Transformable Architecture Search
融合可微分网络进行剪枝
Approximated Oracle Filter Pruning for Destructive CNN Width Optimization
平行操作网络的所有层,用二分搜索的方式确定每层的剪枝数。
Fine-Grained Neural Architecture Search
把NAS的粒度降到了通道
5. 理论思考和总结
Rethinking the value of network pruning 🌟
参数修剪的实际作用在于得到网络结构而非权值。对于修剪后的模型,微调得到的效果和重新从头训练几乎相同。
The lottery ticket hypothesis: Finding sparse, trainable neural networks 🌟
(未剪枝的)大型网络包含一个(剪枝获得的)小的子网络。 如果从一开始就训练这个子网络,且初始化数值一一对应地取自原网络的初始化数值集合, 则会得到和原始网络相似的准确率。
Pruning from Scratch 🌟
在相同的计算开支下,从随机初始化的权重(scratch)直接进行剪枝,也能获得较高性能的模型。该文抛弃了之前预训练、剪枝、fine-tune 的剪枝流程。降低了对预训练模型的依赖,也促使人们重新思考网络剪枝现有方法的有效性。
What is the state of neural network pruning ? 🌟
对神经网络的相关论文进行对比分析, 并提出了剪枝工作的基准 ShrinkBench 。
6.简单应用
(1) YOLO 剪枝: 主要参考如下两篇论文
Learning Efficient Convolutional Networks through Network Slimming
Rethinking the Smaller-Norm-Less-Informative Assumption in Channel Pruning of Convolution Layers
(2) GAN
GAN Slimming: All-in-One GAN Compression by A Unified Optimization Framework
GAN Compression: Efficient Architectures for Interactive Conditional GANs
二. 注意事项:
- 剪裁一个卷积层的 filter,需要修改后续卷积层的 filter. 即剪掉 $Xi$ 的一个 filter,会导致 $X{i+1}$ 少一个 channel, $X{i+1}$ 对应的 filter 在 input_channel 维度上也要减 1。剪裁完 $X_i$之后,在计算 $X{i+1}$ 的 filters 的 l1_norm (下图中绿色一列)的时候,有两种选择
- 算上被删除的一行:independent pruning
- 减去被删除的一行:greedy pruning
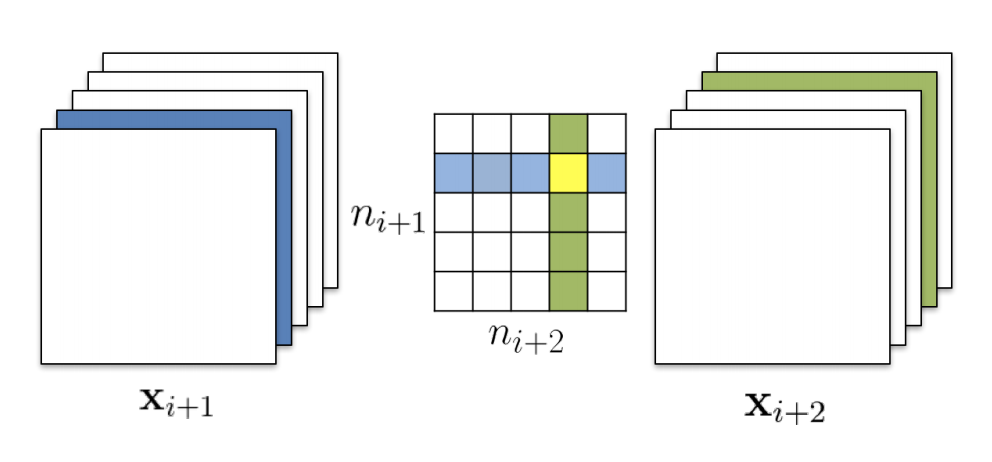
在对 ResNet 等复杂网络剪裁的时候,还要考虑到后当前卷积层的修改对上一层卷积层的影响。在对 residual block 剪裁时,$X{i+1}$ 层如何剪裁取决于 project shortcut 的剪裁结果,因为我们要保证 project shortcut 的 output 和 $X{i+1}$ 的 output 能被正确的 concat.

2. 敏感度的理解和迭代剪枝

如上图所示,横坐标是将 filter 剪裁掉的比例,竖坐标是精度,每条彩色虚线表示的是网络中的一个卷积层。 以不同的剪裁比例单独剪裁一个卷积层,并观察其在验证数据集上的精度损失,并绘出图中的虚线。虚线下降较慢的,对应的卷积层相对不敏感,我们优先修剪不敏感的卷积层的 filter。
考虑到多个卷积层间的相关性,一个卷积层的修改可能会影响其它卷积层的敏感度,我们采取了多次剪裁的策略,步骤如下:
- step1:统计各卷积层的敏感度信息
- step2: 根据当前统计的敏感度信息,对每个卷积层剪掉少量 filter, 并统计 FLOPS,如果 FLOPS 已满足要求,进入 step4,否则进行step3。
- step3: 对网络进行简单的 fine-tune,进入 step1
- step4: fine-tune训练至收敛
三. 参考资料
- https://zhuanlan.zhihu.com/p/153496637
- https://github.com/coldlarry/YOLOv3-complete-pruning
- https://zhuanlan.zhihu.com/p/97198052
- https://blog.csdn.net/jinzhuojun/article/details/100621397
- https://blog.csdn.net/wujianing_110117/article/details/105526241?utm_medium=distribute.pc_relevant.none-task-blog-title-6&spm=1001.2101.3001.4242
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!