knowledge-distillation
知识蒸馏
1. 基本思想
知识蒸馏通过采用预先训练好的教师模型( teacher model) 的输出作为监督信号去训练另外一个轻量化的网络( student model ) 。从而实现将复杂网络(老师模型)的知识迁移到小网络(学生模型) 中, 提高小网络的精度。蒸馏的目的是让学生模型学习到教师模型的泛化能力,而不是去过拟合训练数据。
知识蒸馏首先由 Hinton 在 Distilling the Knowledge in a Neural Network 定义,使用 teacher 模型去指导一个参数量和运算量更少的 student 模型。student 模型的训练有两个目标:一个是 student 模型输出的类别概率和 label 的交叉熵,另一个是 student 模型输出的类别概率和 teacher 模型输出的类别概率的交叉熵,记为 soft target,这两个 loss 加权后得到最终的训练 loss,共同指导 student 模型的训练。 实际操作的时候,会将原来的 softmax 除以 T, 变为:
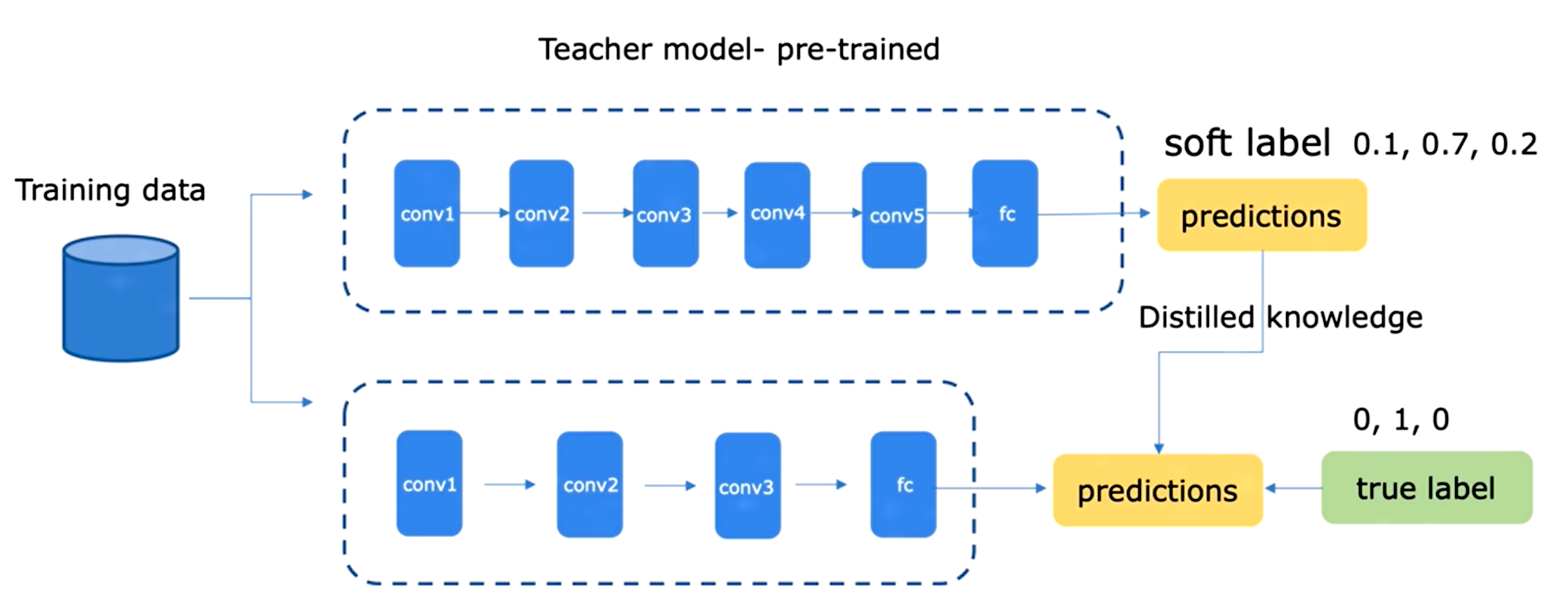
如果 T 越大,则输出的结果的分布越平缓,相当于平滑的一个作用,起到保留相似信息的作用。如果 T 等于无穷,就是一个均匀分布。
几个问题:
(1) T 的选择?T 通常设置为 1,在 paper 中,T 的范围为 1-20。根据经验,student model 和 teacher model 差距越大, T 应该设置的越小。
(2)蒸馏时的损失函数为
其中 CE 是交叉熵(Cross-Entropy),y是真实 label,p 是学生模型的预测结果, q 是教师模型的预测结果。$\alpha$ 和 $\beta$ 是 两个 CE 的加权值, 默认 $\alpha + \beta = 1$。这里要注意的是,因为学生模型要拟合教师模型的分布,所以在求 p 时的也要使用一样的参数 T。另外,因为在求梯度时新的目标函数会导致梯度是以前的 $\frac{1}{T^2}$ ,所以要再乘上 $T^2$。
(3)如果可以拟合 prob,那直接拟合 logits 可以吗? 可以,Hinton 在论文中进行了证明,如果 T 很大,且 logits 分布的均值为0 时,优化概率交叉熵和 logits 的平方差是等价的。
(4) kd loss 和 ce 的 可以使用 mse 作为 loss 吗 ?
mse 的 label 往往是一个任意值而不是概率。知识蒸馏旨在让 student model 学习 teacher model 的概率分布,衡量两个分布的差异,使用 CE 或者 KL 散度更加合适。
参考链接:https://www.zhihu.com/question/436604824/answer/1647365123
(5)为什么 KD 有效?
KD 促使 DNN 更容易从数据中学习更多的视觉概念。prod 具有更大的熵, 包含类间关系等更加丰富的信息。
KD 可确保 DNN 更容易同时学习到各种视觉概念,在没有 KD 的情况下,DNN 在多个阶段分阶段学习不同的视觉概念。
KD 使得学习产生了更稳定的优化方向。
2. 优缺点
2.1 优点
- 知识蒸馏不局限于特定的网络, 可以实现任何网络的蒸馏。
2.2 缺点
- 知识蒸馏的过程也是训练的过程, 同样需要足够多的数据并耗费大量的时间
- 需要精心设计学生网络
2.3 相关改进
使用 GAN 来生成相应的数据
Data-free Learning of Student Networks
Data-Free Adversarial Distillation
利用反向传播来更新数据
Data-Free knowledge distillation for Deep Neural Networks
Dreaming to Distill: Data-free Knowledge Transfer via DeepInversion
让教师模型和学生模型的FSP矩阵(特征的内积)尽量一致,降低了蒸馏的难度
A Gift from Knowledge Distillation: Fast Optimization, Network Minimization and Transfer Learning
使用深层模型来指导浅层模型的学习,可以实现学生模型和教师模型的联合训练
Be Your Own Teacher: Improve the Performance of Convolutional Neural Networks via Self Distillation
FastBERT: a Self-distilling BERT with Adaptive Inference Time
参考资料:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!