lightweight-cnn-architecture-design
常见的移动端模型:mobilenet 系列和 shufflenet 系列和 GhostNet。对于 MnasNet、PorxylessNas、FBNet 等轻量级搜索架构则不涉及。
1. Mobilenet v1
MobileNet模型的核心就是将原本标准的卷积操作因式分解成一个depthwise convolution和一个1*1的卷积(文中叫pointwise convolution)操作。简单讲就是将原来一个卷积层分成两个卷积层,其中前面一个卷积层的每个filter 都只跟 input 的每个 channel 进行卷积,然后后面一个卷积层则负责 combining,即将上一层卷积的结果进行合并。
具体实现:
(1) 传统的卷积计算:假设 M 表示 input 的 channel 个数,N 表示 output 的 channel 个数(也是本层的卷积核个数)。因此如果假设卷积核大小是 DK*DK*M*N,输出是 DF*DF*N,那么标准卷积的计算量是 DK*DK*M*N*DF*DF。如下图(a)所示。
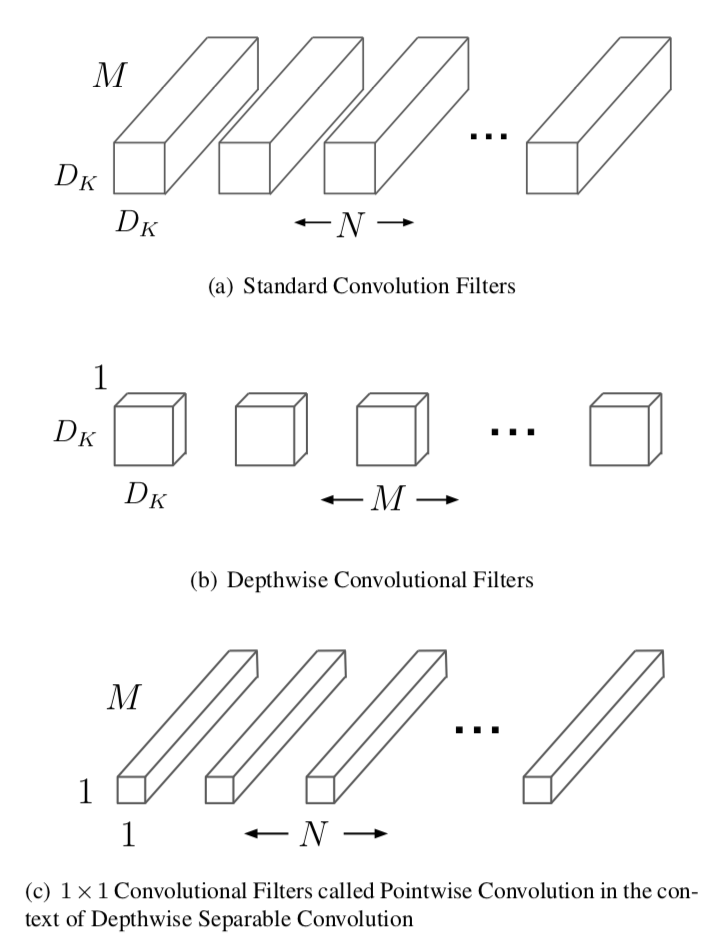
首先使用
M个Dk*Dk的卷积核对输入(M*DF*DF)进行卷积,这里要注意的是每个 filter 只跟输入的一个通道进行卷积(也就是说,卷积核的通道数为 1),将不同卷积核的结果进行组合,可以得到大小为:M*DF*DF的输出。其计算量为M*DK*DK*DF*DF。(这里使用的 3*3 的卷积核,padding 为 1 )。如上图 (b) 所示。第二步是对之前的
M*DF*DF的输出进行卷积,卷积核为N个1*1*M的卷积,这样可以得到大小N*DF*DF的输出。其计算量为1*1*N*M*DF*DF。如上图 (c) 所示。
所以其总的计算量相比传统的卷积计算减少了:
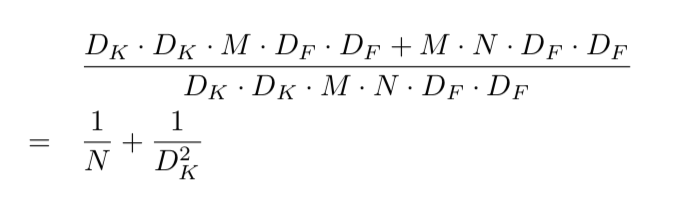
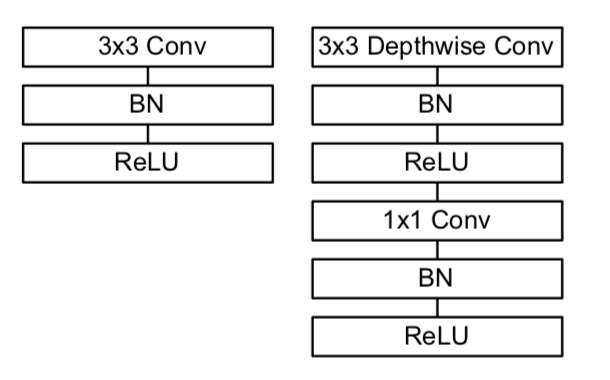
(2)标准卷积(左边)和因式分解后的卷积(右边)的差别如下所示。注意到卷积操作后都会跟一个Batchnorm和ReLU操作。
总的来说,由于采用 depth-wise convolution 会有一个问题,就是导致「信息流通不畅」,即 输出的 feature map 仅包含输入的 feature map 的一部分,MobileNet 用 point-wise convolution 解决这个问题。在后来,ShuffleNet 采用同样的思想对网络进行改进,只不过把 point-wise convolution 换成了 channel shuffle。
2. Shufflenet v1
Shufflenet v1 主要采用 channel shuffle、pointwise group convolutions 和 depthwise convolution来修改原来的ResNet单元。从而大幅度降低深度网络计算量。
- channel shuffle:不同group的通道进行组合。
- pointwise group convolutions:带有 group 的 1 * 1 卷积。
- depthwise convolutions:group 等于通道数的组卷积。
具体实现:
(1)a 图是一个带有 depthwise convolution 的resnet 结果,所谓的 depthwise convolution 可以参见
(2)a 图 —> b 图,用带group的 1 1卷积(2个)代替原来的1 1卷积,同时添加一个channel shuffle 操作。
(3)b 图 —> c 图,添加了一个步长为2的 Average pooling,将Resnet最后的Add操作c改为concat操作,也就是按channel合并,类似googleNet的Inception操作。
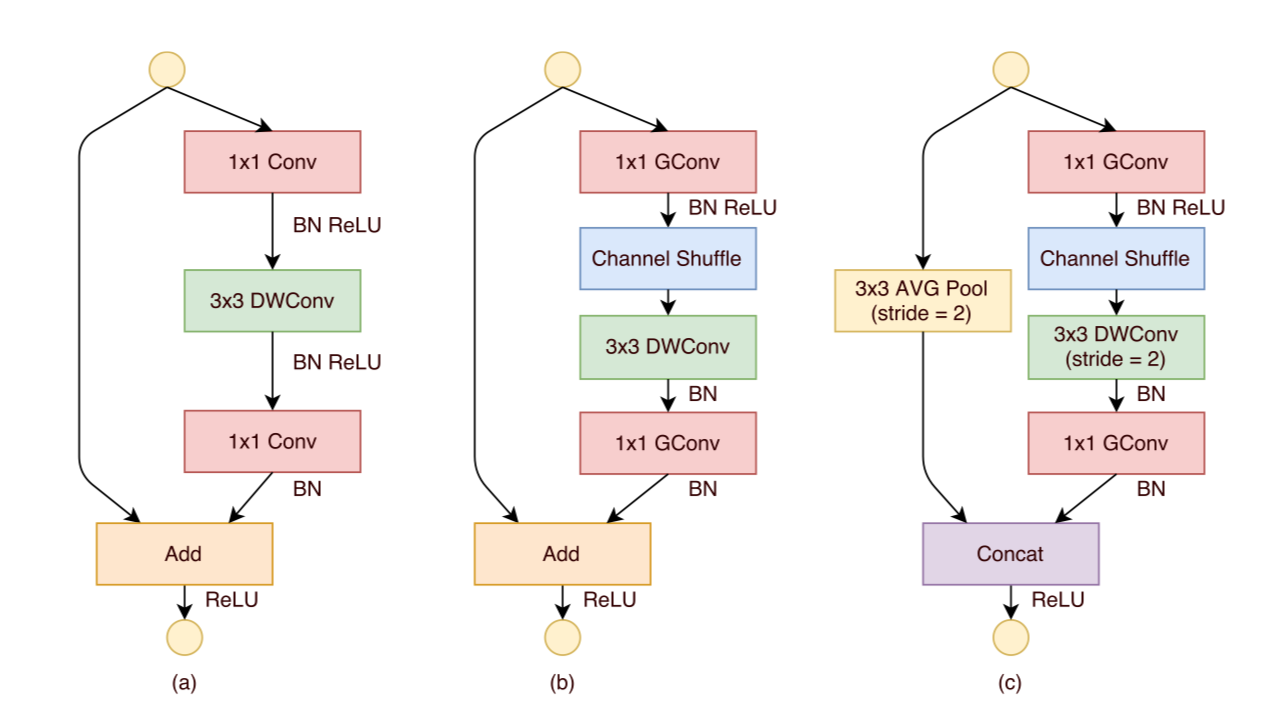
shuffle 具体来说是 channel shuffle,将各部分的 feature map 的 channel 进行有序的打乱,构成新的 feature map,以解决 group convolution 带来的「信息流通不畅」问题。(MobileNet 用 pointwise convolution 解决)因此可知道 shuffle 不是什么网络都需要用的,有一个前提,就是采用了 group convolution。采用 shuffle 替换掉 11 卷积,可以减少权值参数,而且是大量减少。*文中提到两次,对于小型网络,多多使用通道会比较好。所以,以后若涉及小型网络,可考虑如何提升通道使用效率。
ShuffleNet V1 与 Mobilenet V1的区别:
- 与 MobileNet 一样采用了 depth-wise convolution,但是针对 depth-wise convolution 带来的副作用——「信息流通不畅」,ShuffleNet 用 channel shuffle 来解决,MobileNet 用 point-wise convolution 解决。
- 在网络拓扑方面,ShuffleNet 采用的是 resnet 的思想,而 mobielnet 采用的是 VGG 的堆叠思想(SqueezeNet 也是采用 VGG 思想)。
3. Mobilenet V2
MobileNet v2的主要贡献:Inverted Residual 和 Linear Bottleneck。具体实现:
(1) 添加 residual connection。
(2) 通过 1x1 卷积先提升通道数,再通过 depthwise 的 3x3 空间卷积,再用 1x1 卷积降低维度。作者称之为Inverted residual block,两边窄中间宽,像柳叶,仅用较小的计算量就能得到较好的性能。
(3) 使用ReLU6替换传统的ReLU, 并将最后输出的 ReLU6 去掉,直接线性输出。
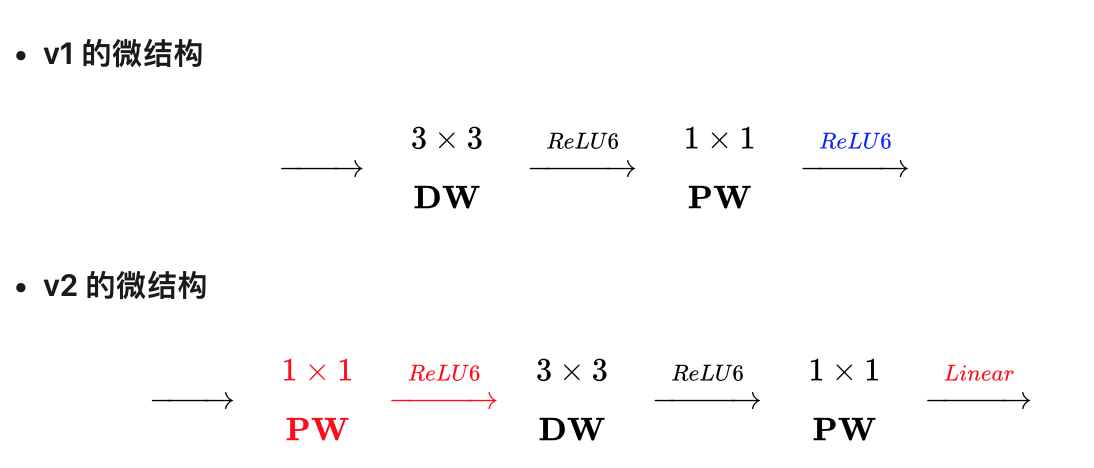
如下图是 mobilenet v1与 mobilenet v2 的对比图。两者的区别在于:
- v2在原有的 dw 之前加了一个 pw 专门用来升维。这么做是因为不能改变通道数量,先加 pw 升维后,dw就能在高维提特征了。
- v2 把原本 dw 之后用来降维的 pw 后的激活函数给去掉了。这么做是因为他认为非线性在高维有益处,但在低维(例如pw降维后的空间)不如线性好。ReLU 会对 channel 数低的张量造成较大的信息损耗。ReLU 会使负值置零,channel 数较低时会有相对高的概率使某一维度的张量值全为 0,即张量的维度减小了,而且这一过程无法恢复。
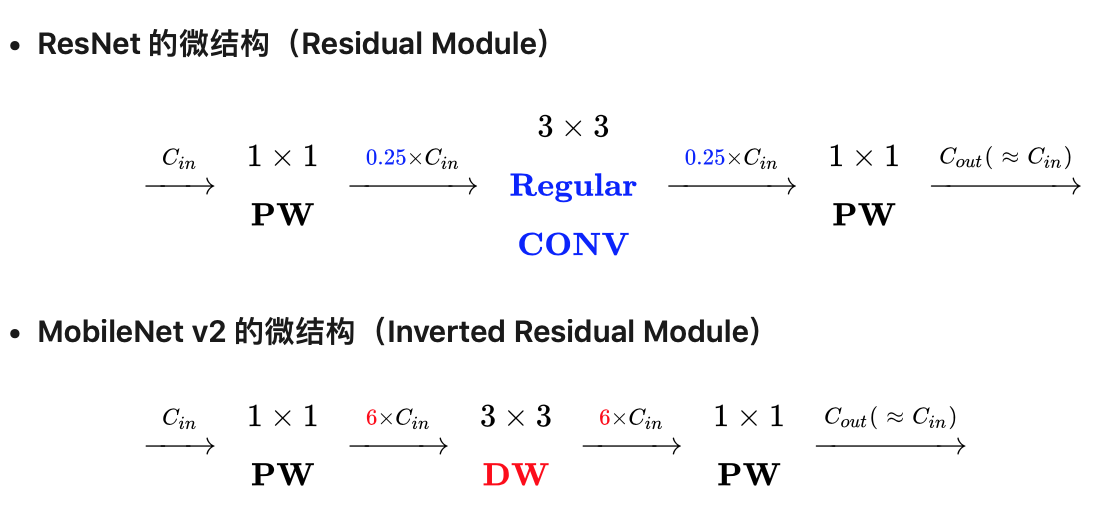
如下图是 Resnet 与 mobilenet v2 的对比图。可以看到两者的结果很相似。不过ResNet是先降维(0.25倍)、提特征、再升维。而v2则是先升维(6倍)、提特征、再降维。另外 v2 也用 DW 代替了标准卷积来做特征提取。why ? 原始的 ResNet block 之所以 1x1 卷积降通道,是为了减少计算量,不然中间的 3x3 卷积计算量太大。所以是两边宽中间窄的沙漏形。但现在中间的 3x3 卷积为 Depthwise 的,计算量很少了,所以通道多一点效果更好,所以通过 1x1 卷积先提升通道数。两端的通道数都很小,所以 1x1 卷积升通道或降通道计算量都不大,而中间通道数虽然多,但 Depthwise 的卷积计算量也不大。是两边窄中间宽的柳叶形。
注:示意表达式省略了Shortcut。
4. shufflenet V2
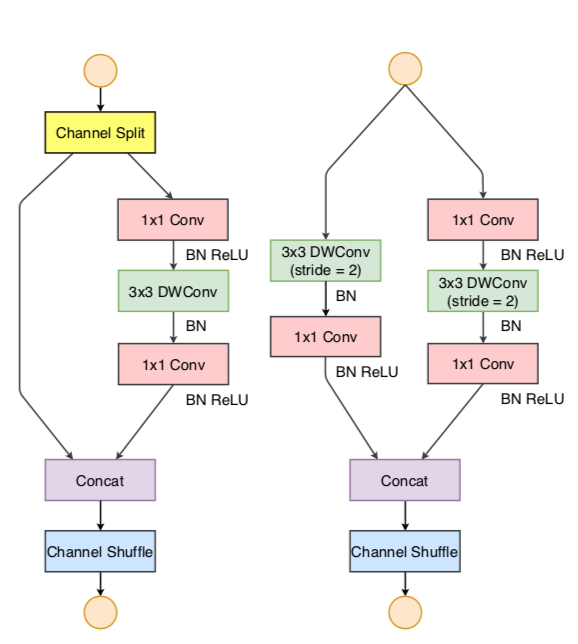
shufflenetV2 提出了一种channel split操作, (1) 将输入channels分为两部分, (2) 一部分保持不变,另一部分由三个卷积组成 (3) 卷积之后,将两部分拼接起来 (4) 最后在通过channel shuffle操作来保持两个分支间的信息交流。
具体实现:
(1) 基本单元
如下左图所示
(1) 在每个单元的开始,c 特征通道的输入被分为两支,分别带有 c−c' 和 c'个通道。
(2) 一个分支仍然保持不变。另一个分支由三个卷积组成,令输入和输出通道相同。与 ShuffleNet V1 不同的是,两个 1×1 卷积不再是组卷积。是因为分割操作已经产生了两个组。
(3) 卷积之后,把两个分支拼接起来,从而通道数量保持不变。
(4) 然后进行与 ShuffleNet V1 相同的「Channel Shuffle」操作来保证两个分支间能进行信息交流。「Shuffle」之后,下一个单元开始运算。
注意,! ShuffleNet V1 [15] 中的「加法」操作不再存在。! 像 ReLU 和深度卷积这样的操作只存在一个分支中。另外,! 三个连续的操作「拼接」、「Channel Shuffle」和「通道分割」合并成一个操作。
空间下采样单元:
对于空间下采样,该单元经过稍微修改,详见下图右, 通道分割运算被移除。因此,输出通道数量翻了一倍。
ShuffleNet V2 对高效的网络架构设计得出了 4 个实用的指导原则:
- 卷积的输入通道 c1 和输出通道 c2 相同时,有最小的内存访问成本 (MAC)
- 过多的分组卷积增加 MAC,MAC 随着组数 g 的增长而增加
- 降低网络结构的破碎程度(减少分支以及所包含的基本单元)。”multi-path“结构使用许多碎片操作符,虽然有利于提高精度,但它降低了并行度
- 减少 element-wise 操作。包括 ReLU、AddTensor、AddBias等。它们的 FLOPs 较小,但 MAC 相对较大
ShuffleNet V2 的设计原则基于以上四点:pointwise group 卷积和瓶颈结构都增加了 MAC (1和2)。这一成本是不可忽视的,特别是对轻量的模型。此外,使用太多组违反了 3。 快捷连接中的 element-wise Add”操作也是不可取的 (4)。因此,为了达到高的模型容量和效率,关键问题是保持同样宽的通道,既不密集卷积,也不过多组。
5. MobileNet V3
用神经结构搜索(NAS)来完成 V3。参考了三种模型:MobileNe tV1 的深度可分离卷积、MobileNet V2 的具有线性瓶颈的反向残差结构、MnasNe+SE 的自动搜索模型。
相关技术:
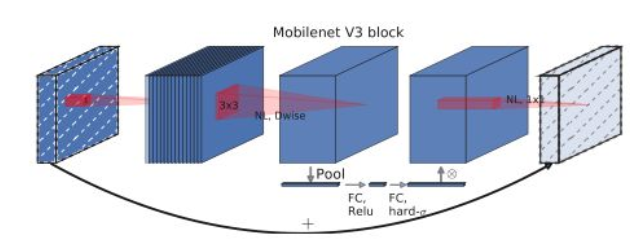
- 网络的架构为基于 NAS 实现的 MnasNet(效果比 MobileNet V2 好)。借鉴与 Mnasnet, 相对于 mobilenet V2, V3 启用 5×5 的 deepwise 卷积。
- 网络结构搜索中,结合两种技术:资源受限的 NAS(platform-aware NAS)与 NetAdapt。
- 引入 MobileNet V1 的深度可分离卷积、MobileNet V2 的具有线性瓶颈的倒残差结构、SENet 的 squeeze and excitation 结构、新的激活函数 h-swish。
- 修改 MobileNet V2 网络端部最后阶段为 1x1 卷积,减小计算。作者认为, V2 模型中的倒残差结构使用 1×1 卷积来构建最后层,以扩展到高维特征空间,可以提取更多更丰富的特征,但同时也引入了额外的计算成本与延时。所以,需要在保留高维特征的前提下减小延时。方法是将 1×1 层放到最终的平均池化之后。这样的话最后一组特征由 avgpool 7x7 变为 pool 7x7+conv2d 1x1。
综合以上,V3 的 block 结构如下所示:
6. ShuffleNetV2+
没有相关论文,只是旷视提出的一个简单的 shufflenetv2 的加强版本, 发布在 github 上。主要的操作是替换其中的激活函数为 h-swish, 并且添加了 SE 模块。
参考网址:https://github.com/megvii-model/ShuffleNet-Series/tree/master/ShuffleNetV2%2B
7. MobileNeXt
本文主要针对MobileNetV2中倒置残差块(inverted residual block)的设计和不足进行了分析,并基于分析结果提出了新颖的sandglass模块,这种轻量级模块有原生残差块和倒置残差块的影子,是一种正向残差设计。
原生残差块组成:1x1卷积(降维降低模型复杂度)、3x3卷积(空间信息变换)、1x1卷积(升维用于和 shortcut 分支相加)
逆残差块组成:1x1卷积(升维提升模型效果)、3x3深度可分卷积(空间信息变换)、1x1卷积(降维)
本文作者认为逆残差模块会削弱梯度跨层传播的能力,将特征从高维空间压缩到低维空间,会造成信息丢失,同时这也容易引起梯度混淆问题(特指梯度消失或梯度爆炸),从而影响训练的收敛和最终模型的性能。本文提出的sandglass模块如下图所示:
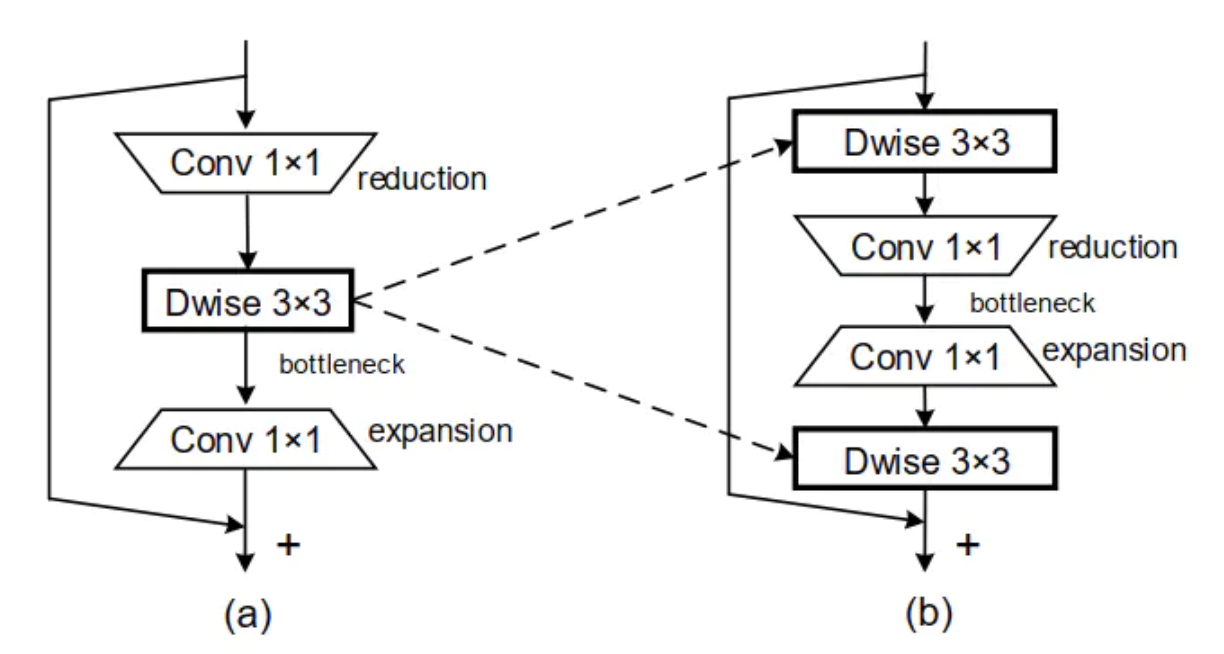
sandglass 模块是在轻量级的残差块上依据逆残差块所存在的问题所改进的,同时这个模块还用到了MobileNetV2中的线性瓶颈设计,即只在第一个 3x3 卷积后边和第二个 1x1 卷积后边使用非线性激活函数 relu6,其他层后边使用线性激活函数(y=x), 这有助于避免零化现象的出现,进而减少信息损失
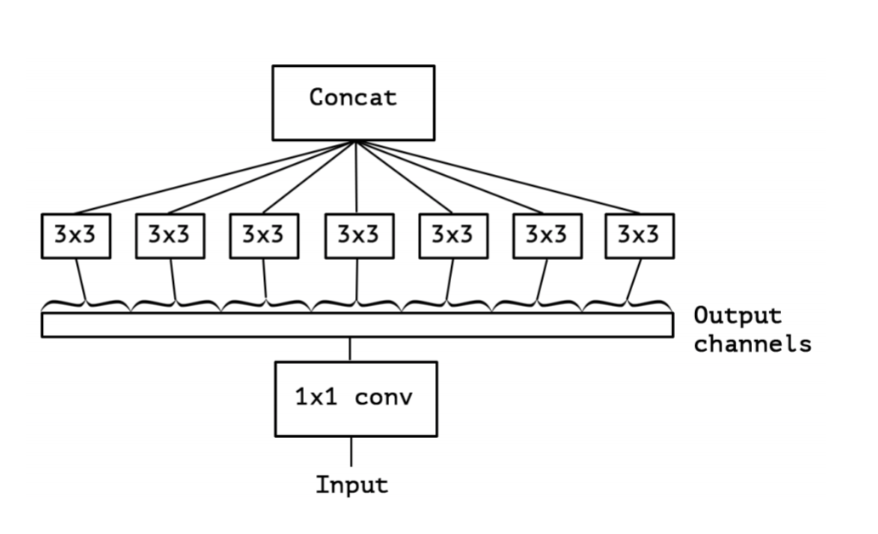
8. xception
Xception 的结构基于 ResNet,但是将其中的卷积层换成了 Separable Convolution(极致的 Inception模块)。 Xception(极致的 Inception): 先进行1x1 卷积操作,再对 1×1 卷积后的每个channel分别进行 3×3 卷积操作,最后将结果 concat:
9. efficinet 原理
原论文: EfficientNet: Rethinking Model Scaling for Convolutional Neural Networks ICML 2019
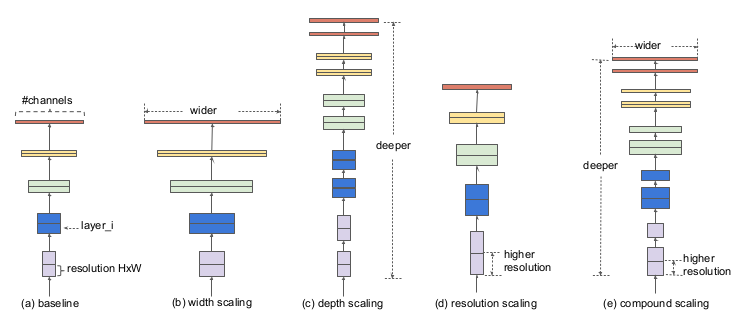
利用复合系数统一缩放模型的所有维度,达到精度最高效率最高,符合系数包括 w, d, r,其中,w表示卷积核大小,决定了感受野大小;d表示神经网络的深度;r表示分辨率大小。
文中总结了我们常用的三种网络调节方式:增大感受野w,增大网络深度d,增大分辨率大小r,三种方式示意图如下:其中,(a)为基线网络,也可以理解为小网络;(b)为增大感受野的方式扩展网络;(c)为增大网络深度d的方式扩展网络;(d)为增大分辨率r的方式扩展网络;(e)为本文所提出的混合参数扩展方式;
复合系数的数学模型
文中给出了一般卷积的数学模型如下:
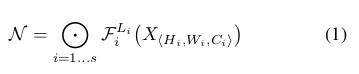
其中 H, W为卷积核大小,C为通道数,X为输入tensor。 则复合系数的确定转为如下的优化问题:

调节 d, w, r 使得满足内存Memory和浮点数量都小于阈值要求; 为了达到这个目标,文中提出了如下的方法:
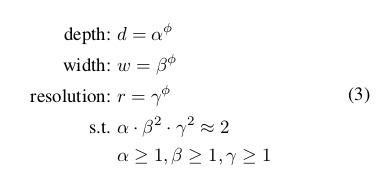
对于这个方法,我们可以通过一下两步来确定d, w, r参数: 第一步是固定Φ=1,然后通过网格搜索找到满足公式3的最优α、β、γ,比如对于EfficientNet-B0网络而言,最佳的参数分别是α=1.2、β=1.1、γ=1.15(此时得到的也就是EfficientNet-B1)。第二步是固定第一步求得的α、β、γ参数,然后用不同的Φ参数得到EfficientNet-B1到EfficientNet-B7网络。
10. GhostNet
(1) 出发点:
通过对比分析 ResNet-50 网络第一个残差组( Residual group )输出的特征图可视化结果,发现一些特征图高度相似。如果按照传统的思考方式,可能认为这些相似的特征图存在冗余,是多余信息,想办法避免产生这些高度相似的特征图。本文的思路是不去刻意的避免产生这种Ghost对,而是尝试利用简单的线性操作来获得更多的Ghost对。
其基本操作如下:
- 使用常规卷积(这里使用的 conv1x1)来获得本征特征层。
- 通过一个线性操作(这里使用的是 depthwise 操作)对本征特征层进行线性变化,获得 ghost 特征层。
- 将 ghost 特征层和 ghost 特征层进行拼接。
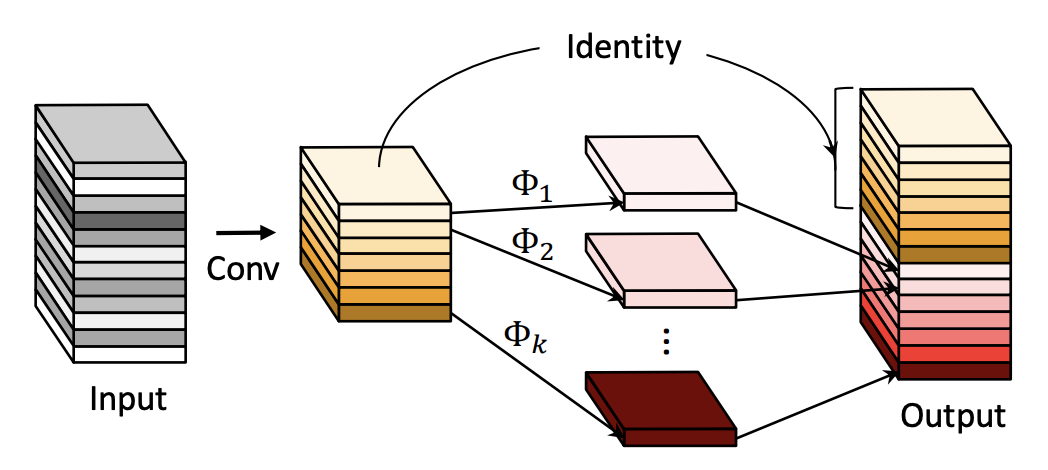
通过将 ResNet 中的 Residual Block 中的卷积操作用 Ghost Module 替换就可以得到 Ghost BottleNeck。图下图所示:
小结
关于网络结构的变迁, 如下图所示(所有 conv 层之后,都使用了 BN 层, 且 BN 层在激活函数之前)
- mobilenet v1 将普通卷积分解为 DepthWise 和 PointWise 两个操作
- shufflenet v1 引入 channel shuffle 操作,初步形成 GConv + shuffle + DW + GConv 的卷积组合
- mobilenet v2 引入了 逆残差模块, 此时的形成了 PW+DW+PW 的组合。 注意这里最后一个 PW 使用线性函数
- shufflent v2 引入了 channels split 操作, 并将 concat + shuffle + split 进行合并

一些小经验
- 使用 DW 和 PW 进行加速是常规操作, 但是对 DW和 PW 的顺序还需要进一步探索。(比如 mobilenext 则使用了 DW + PW + PW+ DW 的组合形式)
- MobileNetV2的倒置残差模块 + SE block + H-swish 是一个屡试不爽的组合,虽然速度会有所损失。
- 激活函数的放置位置还没有定论(虽然 mobilenet v2 进行了探索,提出了线性瓶颈)
- 有一些网络(ghostnet 和 bsconv ) 提出了对卷积核/特征层的冗余进行探索分析,从而降低运算量, 这也算一个方向。
一些对于轻量级检测和分割网络的探索: 轻量级检测的核心问题还是低层特征和高层特征的融合问题,在 backbone 通常选择上面的 轻量级分类网络:
- Pelee: A Real-Time Object Detection System on Mobile Devices
- Tiny-dsod: Lightweight object detection for resource-restricted usages.
- Light-head R-cnn: In defense of two-stage object detector
- ThunderNet: Towards Real-time Generic Object Detection
NanoDet
BiSeNet(分割)
- DFANet(分割)
MIT Han Lab 在模型压缩和加速方向做了很多探索性的工作, 可以重点关注。
nas 在相关领域一度很火,诞生了 MnasNet、PorxylessNas、FBNet 等工作。但是由于需要资源较多等原因,一直未加尝试。
参考论文:
SqueezeNet: AlexNet-level accuracy with 50x fewer parameters and <0.5MB model size.
MobileNets: Efficient Convolutional Neural Networks for Mobile Vision Applications
MobileNetV2: Inverted Residuals and Linear Bottlenecks
Searching for MobileNetV3(nas for efficient conv neural network)
ShuffleNet: An Extremely Efficient Convolutional Neural Network for Mobile Devices
ShuffleNet V2: Practical Guidelines for Ecient CNN Architecture Design
Xception: Deep Learning with Depthwise Separable Convolutions
mobilent 逆残差结构的实现:
# Mobilenet V2
class InvertedResidual(nn.Module):
def __init__(self, inp, oup, stride, expand_ratio):
super(InvertedResidual, self).__init__()
self.stride = stride
self.use_res_connect = self.stride == 1 and inp == oup
self.conv = nn.Sequential(
# pw
nn.Conv2d(inp, inp * expand_ratio, 1, 1, 0, bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU6(inplace=True),
# dw
nn.Conv2d(inp * expand_ratio, inp * expand_ratio, 3, stride, 1, groups=inp * expand_ratio, bias=False),
nn.BatchNorm2d(inp * expand_ratio),
nn.ReLU6(inplace=True),
# pw-linear
nn.Conv2d(inp * expand_ratio, oup, 1, 1, 0, bias=False),
nn.BatchNorm2d(oup),
)
def forward(self, x):
if self.use_res_connect:
return x + self.conv(x)
else:
return self.conv(x)本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!