quantizing
量化, 也被称为定点化、离散化,是指用低精度整数来近似表示浮点数(权重和偏置)的方法。 在量化之后,可以在特定的硬件平台上使用特定的指令集对其加速, 另外,由于存储位宽的减小,模型的体积也会显著减小。常见的量化方案可以分为二值量化、三值量化、低比特量化(介于2-8bit之间) 和 int8 量化。
1. 二值量化
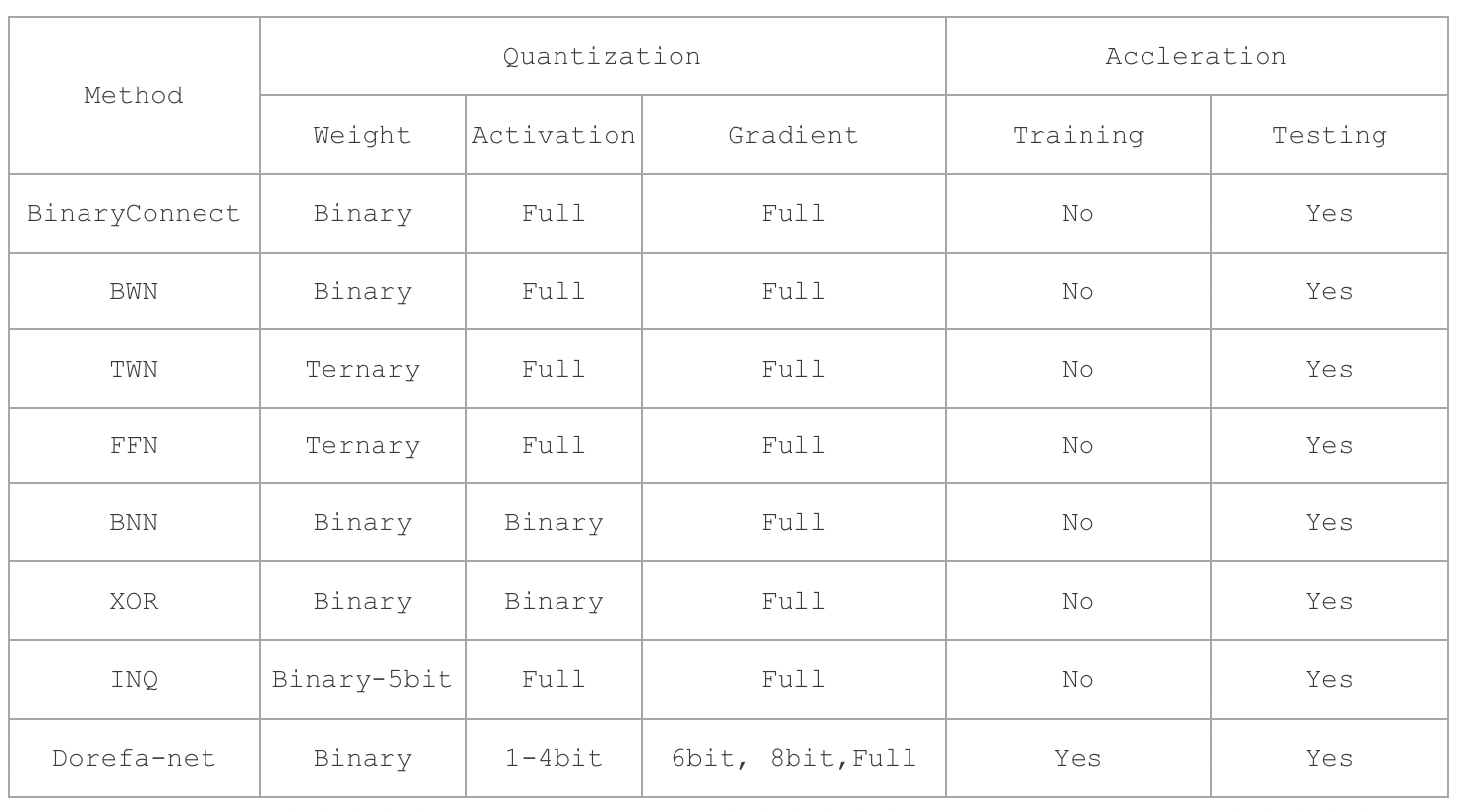
Binary Weight (只对权重进行二值化)
🌟 [BinaryConnect] BinaryConnect: Training Deep Neural Networks with binary weights during propagations
🌟 [BWN] Binary-Weights-Networks
Binary Weight & activation (对权重和激活都进行二值化)
🌟 [XNOR Net] XNOR-Net: ImageNet Classification Using Binary Convolutional Neural Networks
[ABCNet] Towards Accurate Binary Convolutional Neural Network by Xiaofan Lin, Cong Zhao, and Wei Pan.
[Bi-Real Net] Enhancing the Performance of 1bit CNNs with Improved Representational Capacity and Advanced Training Algorithm
[HORQ]Performance Guaranteed Network Acceleration via High-Order Residual Quantization
2. 三值量化
🌟 [TWN] Ternary weight networks
[TNN] Ternary Neural Networks for Resource-Efficient AI Applications
[TTQ] Trained Ternary Quantization
3. 2bit - 8bit
🌟 [DOREFA-NET] DoReFa-Net: Training Low Bitwidth Convolutional Neural Networks with Low Bitwidth Gradient
实现了权重, 激活 值、梯度的量化, 其中权重、激活和梯度分别使用 1bit、2bit 和 4bit 进行表示, 可以实现在特殊硬件上并行训练。
🌟 [ACIQ]:4bit
🌟 [AdaRound]: 4bit
上述方案的对比
4. int8 量化
int8 方案按照量化的时机可以分为感知量化 (Quantization Aware Training, QAT) 和训练后量化 (Post Training Quantization,PTQ)。 在此的重点关注于训练后量化, 因为其不需要重新 fine-tune, 方便在工业界进行落地使用。
- 感知量化, 是在训练过程中对量化进行建模以确定量化参数, 它能够保持较高精度。 该解决方案由 google 提出并将其应用于 tensorflow, 见于论文 Quantizing deep convolutional networks for efficient inference: A whitepaper。
- 对于训练后量化, 则是使用对训练生成的模型直接进行映射。该方法精度损失稍大但是不需要重新训练可以快速得到量化模型。常见的解决方案有四种:max-max(max-min)、KL、admm、easyquant。 其中 KL 方案由 nvidia 提出,是现在主流的 int8 量化方案。
4.1 max-abs
首先求出一个 layer 的激活值范围, 将绝对值的最大值作为阈值, 把这个范围按照比例映射到 -127 到 128 的范围内, 如下左图所示。 其 fp32 和 int8 的转换公式为:
FP32 Tensor (T) = scale_factor(sf) * 8-bit Tensor(t) + FP32_bias (b)通过实验得知,bias值去掉对精度的影响不是很大,因此我们直接去掉, 所以该公式可以简化为:
T = sf * t该方案存在一个问题:不饱和, 即通常在正负上会有一些量化值未被利用, 且会产生较大的精度损失。
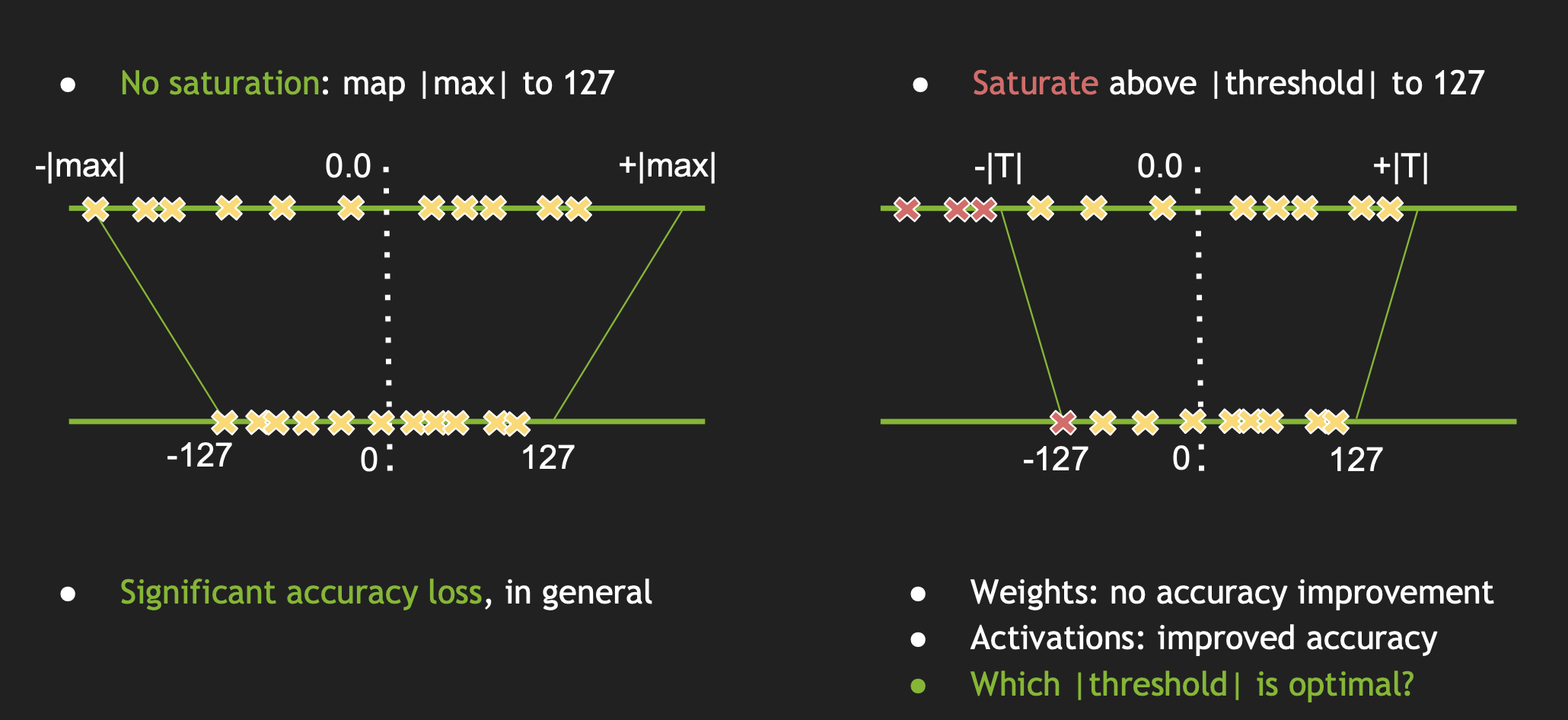
! 注意区分一下 min-max 和 max-max。 前者是将最大值和最小值映射到对应区间, 而后者是找到取最大值和最小值的绝对值。 tensorflow lite 的训练后量化过程是采用的 min-max 方式。
4.2 KL`
针对非饱和映射精度损失的问题,TensorRT 提出了非饱和映射, 即选取一个阈值 $T$ ,然后将 $-|T|$ ~ $|T|$ 之间的值映射到 -127 到 128 这个范围内。这样确定了阈值 T 之后,其实也能确定 scale,一个简单的线性公式是: scale = T/127。 量化的核心就是找到这个阈值 T。 那么问题来了,T 应该取何值? 其基本流程如下:
(a) 选取不同的 T 阈值进行量化, 将 P(fp32) 映射到 Q(int8)。
(b) 将 Q(int8) 反量化到 P(fp32) 一样长度,得到分布 Q_expand;
(c) 计算 P 和 Q_expand 的相对熵( KL 散度),然后选择相对熵最少的一个,也就是跟原分布最像的一个, 从而确定Scale。
其中的 KL 散度可以用来描述 P、Q 两个分布的差异。散度越小,两个分布的差异越小,概率密度函数形状和数值越接近。这里的所有分布、计算,都是离散形式的。分布是以统计直方图的方式存在,KL散度公式如下:
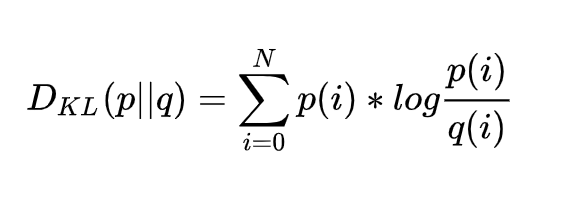
从上式中我们还发现一个问题:KL 散度计算公式要求 P、Q 两个统计直方图长度一样(也就是 bins 的数量一样)。Q 一直都是 -127~127;可是 P 的数量会随着 T 的变化而变化。那这怎么做 KL 散度呢?
ncnn 的做法是将 Q 扩展到和 P 一样的长度,下面举个例子( NVIDIA PPT 中的例子):
P = [1 0 2 3 5 3 1 7] // fp32 的统计直方图,T = 8
// 假设只量化到两个 bins,即量化后的值只有 -1/0/+1 三种
Q = [6, 16] // P 和 Q 现在没法做 KL 散度,所以要将 Q 扩展到和 P 一样的长度
Q_expand=[6/3, 0, 6/3, 6/3, 16/4, 16/4, 16/4, 16/4]=[2 0 2 2 4 4 4 4] // P 中有 0 时不算在内
D = KL(P||Q_expand) // 这样就可以做 KL 散度计算了 这个扩展的操作,就像图像的上采样一样,将低精度的统计直方图(Q),上采样的高精度的统计直方图上去(Q_expand)。由于 Q 中一个 bin 对应P中的 4 个bin,因此在 Q 上采样的 Q_expand 的过程中,所有的数据要除以4。另外,在计算 fp32 的分布 P 时,被 T 截断的数据,是要算在最后一个 bin 里面的。
TNN int8 量化方案代码位置 https://github.com/Tencent/TNN/tree/master/tools/quantization
4.3 admm
admm 算法由 阿里巴巴提出, 应用在 MNN之中。 ADMM 算法是从优化的角度出发,来保证编码前后数据尽可能相似的方法。
首先我们定义一个分段函数 $E(x)$ 如下所示, 则 int8 的求解过程可以表示为 $E(\frac{X}{s})$
可以定义一个目标函数来衡量反量化之后的数据和原数据的“距离”。 这里选择度量 D 为 L2 度量, 则目标函数可以记为:
对其进行求导, 可得:
得到目标函数关于 $s$ 的导数公式以后, 该问题转化为求解 $L$ 关于 $s$ 的导数为 0 的数学问题。 论文采用了 admm 的思想:首先固定 E 中的变量 s,进行 s 值的求解;再通过求解后的 s 去估计 E 的值,如此反复直到 s 值收敛到最优。于是上述的式子要弱化为如下公式:
所以, 迭代的过程也就变成了交替求解如下两个公式的过程:
MNN 中 admm 算法的实现: https://github.com/alibaba/MNN/blob/master/tools/quantization/quantizeWeight.cpp
4.4 easyquant
github 主页: https://github.com/deepglint/EasyQuant
原始的卷积输出结果可以表示为:
其中,A 表示网络层的输入, W 表示网络层的参数。
如果用 $Q$ 表示量化操作,量化层输出再反量化的结果可以表示如下, 其中 $S$ 表示 scale 值。
easyquant 将其看做一个优化问题, 优化目标为量化前的输出和反量化之后的输出的余弦距离。数学表达式为:
4.5 GDFQ 和 ZeroQ
结合 GAN 网络实现生成数据,实现 data-free。 然后结合知识蒸馏(teacher model 为高精度网络, student model 为量化网络)来实现网络的量化。
·
5. int8 实际应用
关于量化之后,如何使用的问题,有两种解决方案:
混合 fp32/int8 推理: 该解决方案引入 Quantize 和 Dequantize 两个操作。在进行卷积操作前,将权重和输入进行 Quantize 为 int8,然后使用 int8 进行卷积,最后将结果 Dequantize 为 float32。这种方案并不需要所有的算子(operator) 都支持量化,但是由于需要数据的 Quantize 和 Dequantize,降低了网络的推理速度。一般而言, 对于权重量化采用 kl量化 或者 easyquant 量化,而对于激活(输入和输出) 的量化可以采用 max-max 量化 。

纯 int8 推理:将网络整体转换为 int8 格式,因此在推理期间没有高低精度数据的转换,因此推理速度更快。但是该解决方案要求算子(Operator) 都支持量化,因为运算符之间的数据流是 int8。对于尚未支持的那些,降级到混合 fp32/int8 推理。

6. ncnn 量化工具的使用
(1) Optimization graphic
./ncnnoptimize mobilenet-fp32.param mobilenet-fp32.bin mobilenet-nobn-fp32.param mobilenet-nobn-fp32.bin(2) Create the calibration table file
./ncnn2table --param mobilenet-nobn-fp32.param --bin mobilenet-nobn-fp32.bin --images images/ --output mobilenet-nobn.table --mean 104,117,123 --norm 0.017,0.017,0.017 --size 224,224 --thread 2(3) Quantization
./ncnn2int8 mobilenet-nobn-fp32.param mobilenet-nobn-fp32.bin mobilenet-int8.param mobilenet-int8.bin mobilenet-nobn.table7. 参考资料
[1] https://me.csdn.net/sinat_31425585
[2] https://zhuanlan.zhihu.com/c_1064124187198705664
[3] https://github.com/BUG1989/caffe-int8-convert-tools
[4] Tencent/ncnn
[5] Nvidia solution: Szymon Migacz. 8-bit Inference with TensorRT
[6] Google solution:Quantizing deep convolutional networks for efficient inference: A whitepaper
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!