ncnn源码分析_4
ncnn源码分析-4 模型量化源码
ncnn量化分析代码对应的文件主要有两个:ncnn/tools/quantize/ncnn2table.cpp 和 ncnn/tools/quantize/ncnn2int8.cpp。
- ncnn2table.cpp 主要是分析生成相应的量化表, 其中存储了每个层的 scale 值。
- ncnn2int8.cpp 则是对网络进行 int8量化
1. ncnn2int8
我们首先对 ncnn2int8.cpp 这个文件进行分析。 该文件完成的主要功能是将 float32 类型转化为 int8 类型。主要分为四个步骤:
(1) 读取生成的 table 文件,里面存储了对应的 scale。这本质上就是一个文本文件的读取和解析。
readint8_scale_table 负责读取 table 文件, 将 scale 分别存储在 weight_int8scale_table (带 _param\) 和 blobint8scale_table(不带_param\)。 这里只是一个读取文件并解析的过程。
weight( 带_param_)格式示例: scale 个数和通道数相同,是主通道进行量化

blob (不带_param_) 格式示例:

(2) 载入原始的参数和模型文件。net 中的 .param 和 .bin 载入方式。
(3) 对卷积层、深度可分离卷积层和全连接层进行量化。quantize_convolution、quantize_convolutiondepthwise、quantize_innerproduct 分别对卷积层、可分离卷积层和全连接层进行量化。 这里其实是构建了一个量化层,然后将原始的fp32类型的权重和scale作为输入, 进行一次forward运算,将结果替换原来的fp32权重
(4) 保存量化后的权重文件
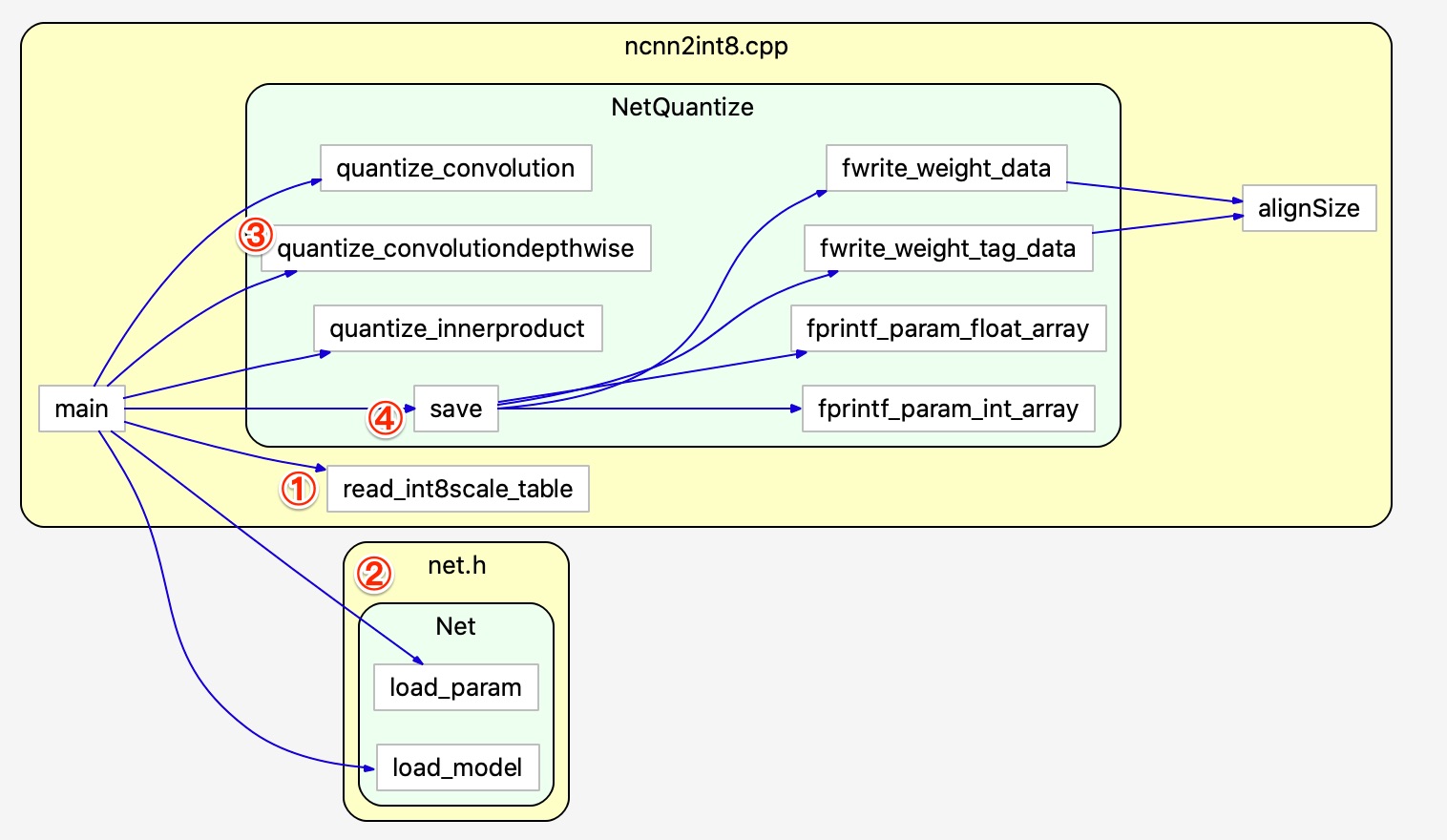
从主函数入手: 分别读取了5个参数, 分别是输入模型文件、参数文件、输出模型文件、输出参数文件和量化表的路径。 然后执行如上所示的四个步骤。
int main(int argc, char** argv)
{
// 读取相应的参数
if (argc != 6)
{
fprintf(stderr, "usage: %s [inparam] [inbin] [outparam] [outbin] [calibration table]\n", argv[0]);
return -1;
}
const char* inparam = argv[1]; // 输入模型文件
const char* inbin = argv[2]; // 输入参数文件
const char* outparam = argv[3]; // 输出模型文件
const char* outbin = argv[4]; // 输出参数文件
const char* int8scale_table_path = argv[5]; // 量化表的路径
NetQuantize quantizer; // 主要的量化类
// (1) 读取并解析 scale table 文件
if (int8scale_table_path)
{
bool s2 = read_int8scale_table(int8scale_table_path, quantizer.blob_int8scale_table, quantizer.weight_int8scale_table);
if (!s2)
{
fprintf(stderr, "read_int8scale_table failed\n");
return -1;
}
}
// (2) 载入模型文件和参数
quantizer.load_param(inparam);
quantizer.load_model(inbin);
// (3) 量化: 主要量化三层: conv、convdw 和 fc
quantizer.quantize_convolution();
quantizer.quantize_convolutiondepthwise();
quantizer.quantize_innerproduct();
// (4) 存储模型和参数文件
quantizer.save(outparam, outbin);
return 0;
} 代码的最核心的三个函数: quantize_convolution、quantize_convolutiondepthwise、quantize_innerproduct 分别对卷积层、可分离卷积层和全连接层进行量化,
我们在此以 quantize_convolution 为例:
int NetQuantize::quantize_convolution()
{
const int layer_count = static_cast<int>(layers.size());
for (int i = 0; i < layer_count; i++)
{
// 查找所有的卷积层
if (layers[i]->type != "Convolution")
continue;
// 获取卷积层的名称
char key[256];
sprintf(key, "%s_param_0", layers[i]->name.c_str());
// 在 blob_int8scale_table 找到该层 /* 其实这里的 blob_int8scale_table 下文并没有用到 */
std::map<std::string, std::vector<float> >::iterator iter_data = blob_int8scale_table.find(layers[i]->name);
if (iter_data == blob_int8scale_table.end())
continue;
// 在 weight_int8scale_table 找到该层
std::map<std::string, std::vector<float> >::iterator iter = weight_int8scale_table.find(key);
if (iter == weight_int8scale_table.end())
{
fprintf(stderr, "this layer need to be quantized, but no scale param!\n");
return -1;
}
// 卷积层量化 -> fp32 到 int8
ncnn::Convolution* convolution = (ncnn::Convolution*)layers[i]; // (1) 获取该卷积层
fprintf(stderr, "quantize_convolution %s\n", convolution->name.c_str());
std::vector<float> weight_data_int8_scales = iter->second; // (2) 获取weight_data_int8_scales
{
ncnn::Mat int8_weight_data(convolution->weight_data_size, (size_t)1u); // (3) 结果,和weight的大小一致
if (int8_weight_data.empty())
return -100;
// 这里所谓的量化,即进行了一次简单的前向传播,将原来的float32类型的权重替换为int类型结果
// 在此之前我们准备的东西有
// (1) 卷积层的 fp32 的数据 (2) scale 数据 (3) 声明了一个 int8_weight_data的数据
// 我们的目标就是 (1) + (2) -> (3)
const int weight_data_size_output = convolution->weight_data_size / convolution->num_output;
for (int n = 0; n < convolution->num_output; n++) // 逐卷积核进行量化
{
// (4) 创建一个quantize op
ncnn::Layer* op = ncnn::create_layer(ncnn::LayerType::Quantize);
// (5) 把量化表中的scale设置进op里去
ncnn::ParamDict pd;
pd.set(0, weight_data_int8_scales[n]);
op->load_param(pd);
// (6) blob_allocator
ncnn::Option opt;
opt.blob_allocator = int8_weight_data.allocator;
// (7) weight_data <-> weight_data_n , int8_weight_data <-> int8_weight_data_n
const ncnn::Mat weight_data_n = convolution->weight_data.range(weight_data_size_output * n, weight_data_size_output);
ncnn::Mat int8_weight_data_n = int8_weight_data.range(weight_data_size_output * n, weight_data_size_output);
// (8) quantitze op前传,计算量化权值 weight_data_n -> int8_weight_data_n
op->forward(weight_data_n, int8_weight_data_n, opt);
delete op;
}
convolution->weight_data = int8_weight_data; // (9) 用量化后的权值替换原来的权值
}
convolution->int8_scale_term = 2;
}
return 0;
}可以来简单的看一下 quantize 层:
static inline signed char float2int8(float v){
int int32 = static_cast<int>(round(v)); // 取整数, 然后转化为 int32类型
if (int32 > 127) return 127; // 如果大于127, 返回127
if (int32 < -127) return -127; // 如果小于 -127, 返回 -127
return (signed char)int32; // 返回 int32 -> int8
}
int Quantize::forward(const Mat& bottom_blob, Mat& top_blob, const Option& opt) const{
int dims = bottom_blob.dims;
if (dims == 1){
int w = bottom_blob.w;
top_blob.create(w, (size_t)1u, opt.blob_allocator);
if (top_blob.empty())
return -100;
const float* ptr = bottom_blob;
signed char* outptr = top_blob;
#pragma omp parallel for num_threads(opt.num_threads)
for (int i=0; i<w; i++)
{
// ! 这一句是最核心的,也是整个量化部分代码的核心
// 将 float32 乘以 scale, 然后将其转化为 int8 类型
outptr[i] = float2int8(ptr[i] * scale);
}
}
if (dims == 2){
...
}
if (dims == 3){
...
}
return 0;
}2. ncnn2table.cpp
ncnn2table.cpp 主要用于量化表的计算,说白了就是使用我们之前说的算法来计算各个参数的 scale,在ncnn2table.cpp下,顶层代码核心就一句话:
/* ncnn2table.cpp */
// filenames: 用来calibration的图片list
// parampath: 参数文件路径
// binpath: bin 二进制文件路径
// tablepath: 生成的量化表的路径
// pre_param: 参数
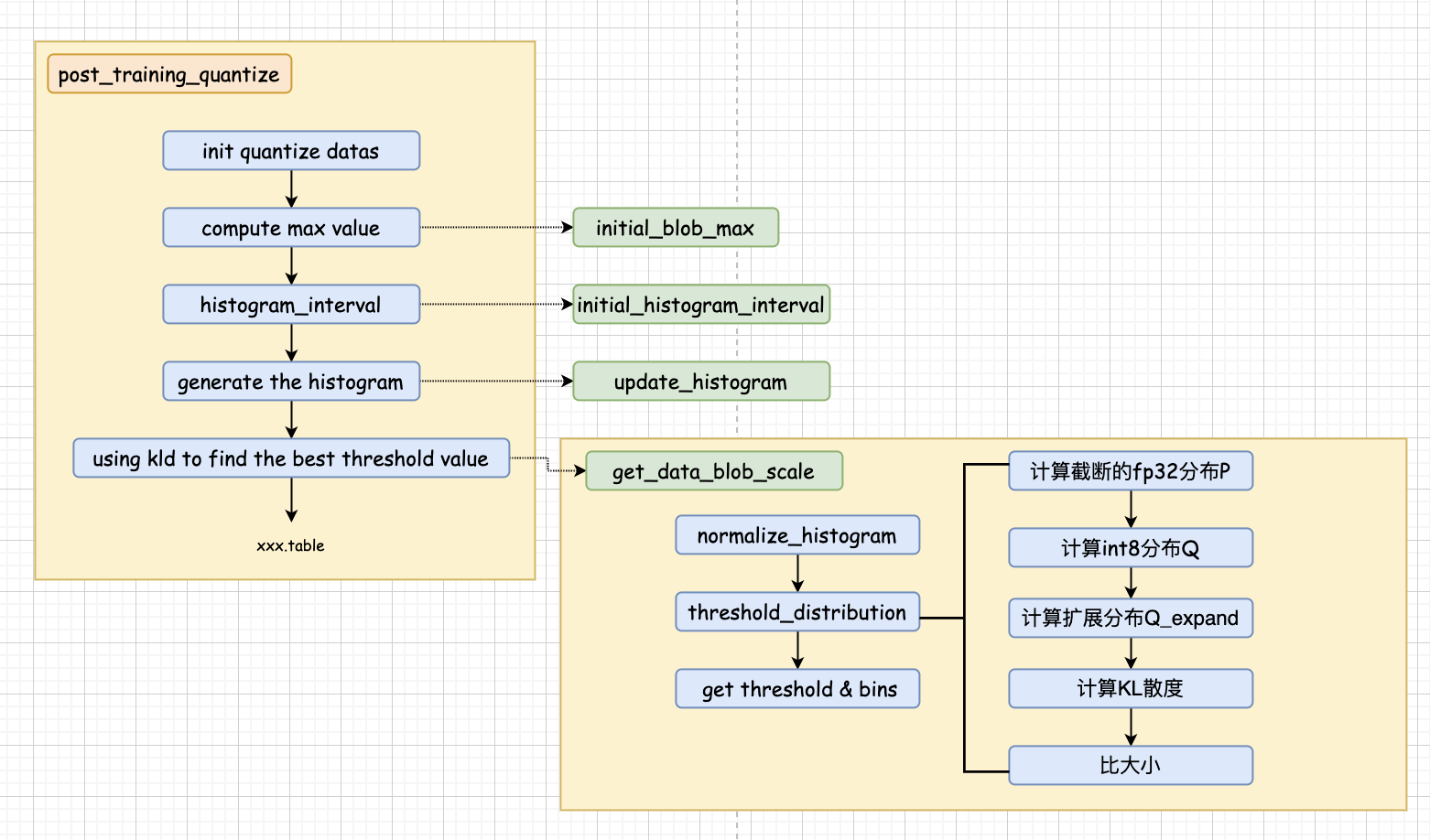
post_training_quantize(filenames, parampath, binpath, tablepath, pre_param);我们接下来重点看post_training_quantize这个函数,该函数做了如下几件事:
>>>> (1) 初始化quantitize_datas (2) 计算最大值 (3) 初始化直方图的间隔 (4) 计算直方图 (5) 计算Scale
(1) 初始化quantitize_datas
没什么好说的,每一个层有一个QuantizeData对象,初始化 num_bins=2048,也就是原始的fp32分布Po,其统计直方图一共有2048个bins
std::vector<QuantizeData> quantize_datas;
for (size_t i = 0; i < net.conv_names.size(); i++)
{
std::string layer_name = net.conv_names[i];
QuantizeData quantize_data(layer_name, 2048);
quantize_datas.push_back(quantize_data);
}(2) 计算最大值
遍历所有图片,计算每个blob的最大激活值,这里找的是绝对值最大的那个
for (size_t i = 0; i < image_list.size(); i++) // 遍历calibration数据
{
std::string img_name = image_list[i];
if ((i + 1) % 100 == 0)
{
fprintf(stderr, " %d/%d\n", static_cast<int>(i + 1), static_cast<int>(size));
}
cv::Mat bgr = cv::imread(img_name, cv::IMREAD_COLOR);
if (bgr.empty())
{
fprintf(stderr, "cv::imread %s failed\n", img_name.c_str());
return -1;
}
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, swapRB ? ncnn::Mat::PIXEL_BGR2RGB : ncnn::Mat::PIXEL_BGR, bgr.cols, bgr.rows, width, height);
in.substract_mean_normalize(mean_vals, norm_vals);
ncnn::Extractor ex = net.create_extractor();
ex.input(net.input_names[0].c_str(), in);
for (size_t j = 0; j < net.conv_names.size(); j++)
{
std::string layer_name = net.conv_names[j];
std::string blob_name = net.conv_bottom_blob_names[layer_name];
ncnn::Mat out;
ex.extract(blob_name.c_str(), out); // 前传网络,相当于caffe的forwardTo,拿到blob数据
for (size_t k = 0; k < quantize_datas.size(); k++)
{
if (quantize_datas[k].name == layer_name)
{
quantize_datas[k].initial_blob_max(out); // 统计最大值
break;
}
}
}
}
// 被调函数:
int QuantizeData::initial_blob_max(ncnn::Mat data)
{
const int channel_num = data.c;
const int size = data.w * data.h;
for (int q = 0; q < channel_num; q++)
{
const float *data_n = data.channel(q);
for (int i = 0; i < size; i++)
{
max_value = std::max(max_value, std::fabs(data_n[i]));
}
}
return 0;
}(3) 初始化直方图间隔
也很简单,遍历每个层,初始化直方图间隔=最大激活值/2048
// step 2 histogram_interval
printf(" ====> step 2 : generate the histogram_interval.\n");
for (size_t i = 0; i < net.conv_names.size(); i++)
{
std::string layer_name = net.conv_names[i];
for (size_t k = 0; k < quantize_datas.size(); k++)
{
if (quantize_datas[k].name == layer_name)
{
quantize_datas[k].initial_histogram_interval();
fprintf(stderr, "%-20s : max = %-15f interval = %-10f\n", quantize_datas[k].name.c_str(), quantize_datas[k].max_value, quantize_datas[k].histogram_interval);
break;
}
}
}
// 被调函数
int QuantizeData::initial_histogram_interval()
{
histogram_interval = max_value / static_cast<float>(num_bins);
return 0;
}(4) 计算直方图
再前传一次,遍历每个blob,向每个bin中投票,计算出直方图,得到原始fp32分布
// step 3 histogram
printf(" ====> step 3 : generate the histogram.\n");
for (size_t i = 0; i < image_list.size(); i++)
{
std::string img_name = image_list[i];
if ((i + 1) % 100 == 0)
fprintf(stderr, " %d/%d\n", (int)(i + 1), (int)size);
cv::Mat bgr = cv::imread(img_name, cv::IMREAD_COLOR);
if (bgr.empty())
{
fprintf(stderr, "cv::imread %s failed\n", img_name.c_str());
return -1;
}
ncnn::Mat in = ncnn::Mat::from_pixels_resize(bgr.data, swapRB ? ncnn::Mat::PIXEL_BGR2RGB : ncnn::Mat::PIXEL_BGR, bgr.cols, bgr.rows, width, height);
in.substract_mean_normalize(mean_vals, norm_vals);
ncnn::Extractor ex = net.create_extractor();
ex.input(net.input_names[0].c_str(), in);
for (size_t j = 0; j < net.conv_names.size(); j++)
{
std::string layer_name = net.conv_names[j];
std::string blob_name = net.conv_bottom_blob_names[layer_name];
ncnn::Mat out;
ex.extract(blob_name.c_str(), out);
for (size_t k = 0; k < quantize_datas.size(); k++)
{
if (quantize_datas[k].name == layer_name)
{
quantize_datas[k].update_histogram(out);
break;
}
}
}
}
// 被调函数
int QuantizeData::update_histogram(ncnn::Mat data)
{
const int channel_num = data.c;
const int size = data.w * data.h;
for (int q = 0; q < channel_num; q++)
{
const float *data_n = data.channel(q);
for (int i = 0; i < size; i++)
{
if (data_n[i] == 0)
continue;
const int index = std::min(static_cast<int>(std::abs(data_n[i]) / histogram_interval), 2047);
histogram[index]++;
}
}
return 0;
}
(5) 计算Scale
// step4 kld
printf(" ====> step 4 : using kld to find the best threshold value.\n");
for (size_t i = 0; i < net.conv_names.size(); i++)
{
std::string layer_name = net.conv_names[i];
std::string blob_name = net.conv_bottom_blob_names[layer_name];
fprintf(stderr, "%-20s ", layer_name.c_str());
for (size_t k = 0; k < quantize_datas.size(); k++)
{
if (quantize_datas[k].name == layer_name)
{
quantize_datas[k].get_data_blob_scale();
fprintf(stderr, "bin : %-8d threshold : %-15f interval : %-10f scale : %-10f\n",
quantize_datas[k].threshold_bin,
quantize_datas[k].threshold,
quantize_datas[k].histogram_interval,
quantize_datas[k].scale);
fprintf(fp, "%s %f\n", layer_name.c_str(), quantize_datas[k].scale);
break;
}
}
}
// 被调函数
float QuantizeData::get_data_blob_scale()
{
normalize_histogram(); // 直方图归一化
threshold_bin = threshold_distribution(histogram); // 计算最后有多少个bins
threshold = (threshold_bin + 0.5) * histogram_interval; // 之后很容易就能找到Threshold
scale = 127 / threshold; // Scale也很简单就能z好到
return scale;
}其实说了半天,最核心的就在get_data_blob_scale这个函数里,函数分为3步:
a. 直方图归一化
int QuantizeData::normalize_histogram()
{
const size_t length = histogram.size();
float sum = 0;
for (size_t i = 0; i < length; i++)
sum += histogram[i];
for (size_t i = 0; i < length; i++)
histogram[i] /= sum;
return 0;
}b. 使用KL散度计算最后用多少个bins比较合适
int QuantizeData::threshold_distribution(const std::vector<float> &distribution, const int target_bin = 128)
{
...
// 这里length就是原始分布Po的长度,NCNN默认2048。这里的threshold实际上是num_bins,可以换算成T
for(int threshold = target_bin; threshold < length; threshold++) // target_bin=128,length = 2048
{
// ①. 计算截断的fp32分布P
// ②. 计算int8分布Q
// ③. 计算扩展分布Q_expand
// ④. 计算KL散度
// ⑤. 比大小
}
}①. 计算截断的fp32分布P也很简单:
float threshold_sum = 0;
for (int threshold=target_bin; threshold<length; threshold++)
{
threshold_sum += distribution[threshold]; // 128以上的所有数据和
}
for (int threshold=target_bin; threshold<length; threshold++)
{
std::vector<float> t_distribution(distribution.begin(), distribution.begin()+threshold);
t_distribution[threshold-1] += threshold_sum; // P的最后一个bin加上被截断的所有概率,得到截断的fp32分布P
threshold_sum -= distribution[threshold]; // 是通过减法来保证数值正确性的,很巧秒
...②. 计算int8分布Q,注意Q是从Po得来的,而不是从P得来的,大于T的部分并不会加进最后一个bin内(存疑,不理解);另外,当发生了4舍5入时,会有特殊处理
std::vector<float> quantize_distribution(target_bin); // 量化后分布Q,长度是128
fill(quantize_distribution.begin(), quantize_distribution.end(), 0);
const float num_per_bin = static_cast<float>(threshold) / target_bin; // 其实就是当前T下的Scale
for (int i=0; i<target_bin; i++)
{
const float start = i * num_per_bin;
const float end = start + num_per_bin;
const int left_upper = ceil(start);
if (left_upper > start)
{ // 这里的意思是,如果发生了5入,则需要将舍掉的那个bin按比例加进来
const float left_scale = left_upper - start;
quantize_distribution[i] += left_scale * distribution[left_upper - 1];
}
const int right_lower = floor(end);
if (right_lower < end)
{
const float right_scale = end - right_lower;
quantize_distribution[i] += right_scale * distribution[right_lower];
}
for (int j=left_upper; j<right_lower; j++)
{
quantize_distribution[i] += distribution[j];
}
}③. 计算Q_expand,统计count时0不算在内,注意不管是统计数量还是上采样的过程中,都有4舍5入相关的问题
// get Q
std::vector<float> expand_distribution(threshold, 0);
for (int i=0; i<target_bin; i++)
{
const float start = i * num_per_bin;
const float end = start + num_per_bin;
float count = 0;
const int left_upper = ceil(start);
float left_scale = 0;
if (left_upper > start)
{
left_scale = left_upper - start;
if (distribution[left_upper - 1] != 0)
{
count += left_scale;
}
}
const int right_lower = floor(end);
float right_scale = 0;
if (right_lower < end)
{
right_scale = end - right_lower;
if (distribution[right_lower] != 0)
{
count += right_scale;
}
}
for (int j=left_upper; j<right_lower; j++)
{
if (distribution[j] != 0)
{
count++;
}
}
const float expand_value = quantize_distribution[i] / count;
if (left_upper > start)
{
if (distribution[left_upper - 1] != 0)
{
expand_distribution[left_upper - 1] += expand_value * left_scale; // 上采样过程中一样有四舍五入的问题
}
}
if (right_lower < end)
{
if (distribution[right_lower] != 0)
{
expand_distribution[right_lower] += expand_value * right_scale;
}
}
for (int j=left_upper; j<right_lower; j++)
{
if (distribution[j] != 0)
{
expand_distribution[j] += expand_value;
}
}
}④. 计算KL散度,注意当Q为0时,KL散度只加一(存疑,不理解)
float kl_divergence = compute_kl_divergence(t_distribution, expand_distribution);
float QuantizeData::compute_kl_divergence(const std::vector<float> &dist_a, const std::vector<float> &dist_b)
{
const int length = dist_a.size();
assert(dist_b.size() == length);
float result = 0;
for (int i=0; i<length; i++)
{
if (dist_a[i] != 0)
{
if (dist_b[i] == 0)
{
result += 1; // Q为0时,KL散度只加一
}
else
{
result += dist_a[i] * log(dist_a[i] / dist_b[i]);
}
}
}
return result;
}⑤. 轻松愉悦的找最大值
if (kl_divergence < min_kl_divergence)
{
min_kl_divergence = kl_divergence;
target_threshold = threshold; // 实际上是num_bins
}c. 计算 Threshold 和 bins
至此,我们得到了KL散度最小的桶数num_bins,可以通过下述公式得到T和Scale,就三行:
threshold = (static_cast<float>(threshold_bin) + 0.5f) * histogram_interval;
scale = 127 / threshold;
return scale;最后就是将Scale数据存下来,得到量化表了。
总结一下以上的代码逻辑:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!