ncnn源码分析_3
ncnn 源码分析 模型量化原理
1. FP32 vs int8
来看一下 FP32、FP16和int8之间的动态范围和精度的对比, 可以看到float32 的取值范围几乎是无穷的, 而int8只有-128~127. 因此需要建立映射关系将float32类型的浮点数映射到指定范围的int8类型。

2. TensorRT int8 量化方案
Nvidia 的 TensorRT提供了一种量化方案,但是它仅仅提供相应的SDK和解决方案, 没有公布对应的源代码, 诸多第三方厂家则根据该解决方案自己造轮子,产生了对应的解决方案。该量化方案的最重要的两份参考资料如下所示:
- TensorRT Develop guide: https://docs.nvidia.com/deeplearning/sdk/tensorrt-developer-guide/index.html#work-with-qat-networks
- PDF 链接: http://on-demand.gputechconf.com/gtc/2017/presentation/s7310-8-bit-inference-with-tensorrt.pdf
(1) max-max 映射: 最简单粗暴的方式如下左图所示
首先求出一个laye 的激活值范围, 然后按照绝对值的最大值作为阈值, 然后把这个范围按照比例映射到-127到128的范围内, 其fp32和int8的转换公式为:
FP32 Tensor (T) = scale_factor(sf) * 8-bit Tensor(t) + FP32_bias (b)
通过实验得知,bias值去掉对精度的影响不是很大,因此我们直接去掉, 所以该公式可以简化为:
T = sf * t
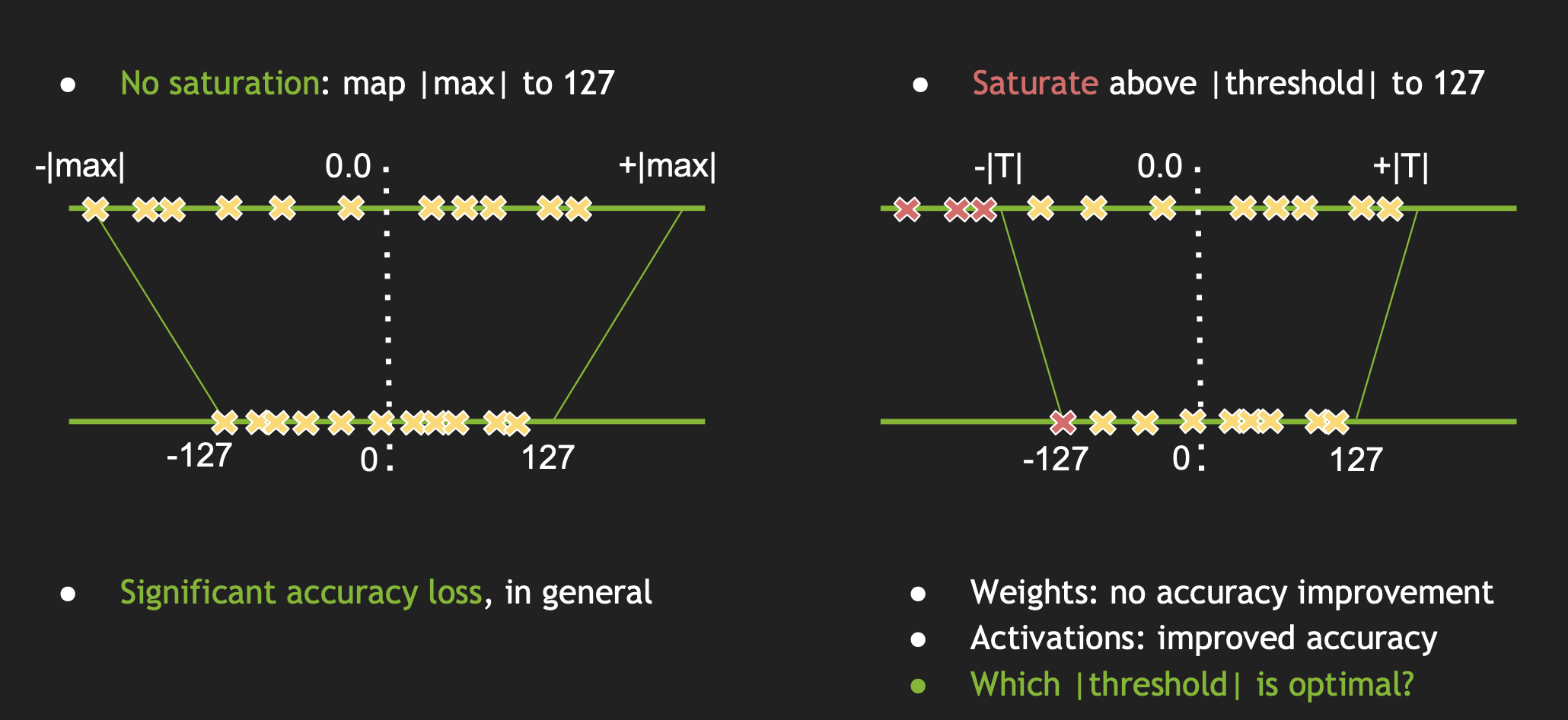
(2) 饱和映射
如上方法会有一个问题:不饱和,即通常在正负上会有一些量化值未被利用,且会产生的精度损失较大。针对 max-max 映射存在的问题, TensorRT提出了如上右图的饱和映射。 选取一个阈值T,然后将 -|T|~|T| 之间的值映射到 -127 到 128 这个范围内。这样确定了阈值T之后,其实也能确定Scale,一个简单的线性公式是: Scale = T/127。 所以要计算Scale,只要找到合适的阈值T就可以了。那么问题来了,T应该取何值? 其基本流程如下:
(a) 选取不同的 T 阈值进行量化, 将 P(fp32) 映射到 Q(int8)。
(b) 将 Q(int8) 反量化到 P(fp32) 一样长度,得到分布 Q_expand;
(c) 计算P和Q_expand 的相对熵(KL散度),然后选择相对熵最少的一个,也就是跟原分布最像的一个, 从而确定Scale**。**
(3) KL 散度
KL散度可以用来描述P、Q两个分布的差异。散度越小,两个分布的差异越小,概率密度函数形状和数值越接近。这里的所有分布、计算,都是离散形式的。分布是以统计直方图的方式存在,KL散度公式也是离散公式:
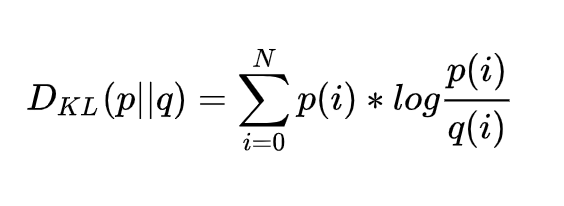
从上式中我们还发现一个问题:KL散度计算公式要求P、Q两个统计直方图长度一样(也就是bins的数量一样)。Q一直都是-127~127;可是P的数量会随着T的变化而变化。那这怎么做KL散度呢?
ncnn 的做法是将 Q扩展到和P一样的长度,下面举个例子(NVIDIA PPT中的例子):
P = [1 0 2 3 5 3 1 7] // fp32的统计直方图,T=8
// 假设只量化到两个bins,即量化后的值只有-1/0/+1三种
Q=[1+0+2+3, 5+3+1+7] = [6, 16]
// P和Q现在没法做KL散度,所以要将Q扩展到和P一样的长度
Q_expand = [6/3, 0, 6/3, 6/3, 16/4, 16/4, 16/4, 16/4] = [2 0 2 2 4 4 4 4] // P中有0时,不算在内
D = KL(P||Q_expand) // 这样就可以做KL散度计算了 这个扩展的操作,就像图像的上采样一样,将低精度的统计直方图(Q),上采样的高精度的统计直方图上去(Q_expand)。由于Q中一个bin对应P中的4个bin,因此在Q上采样的Q_expand的过程中,所有的数据要除以4。另外,在计算fp32的分布P时,被T截断的数据,是要算在最后一个bin里面的。
3. ncnn的conv量化计算流程
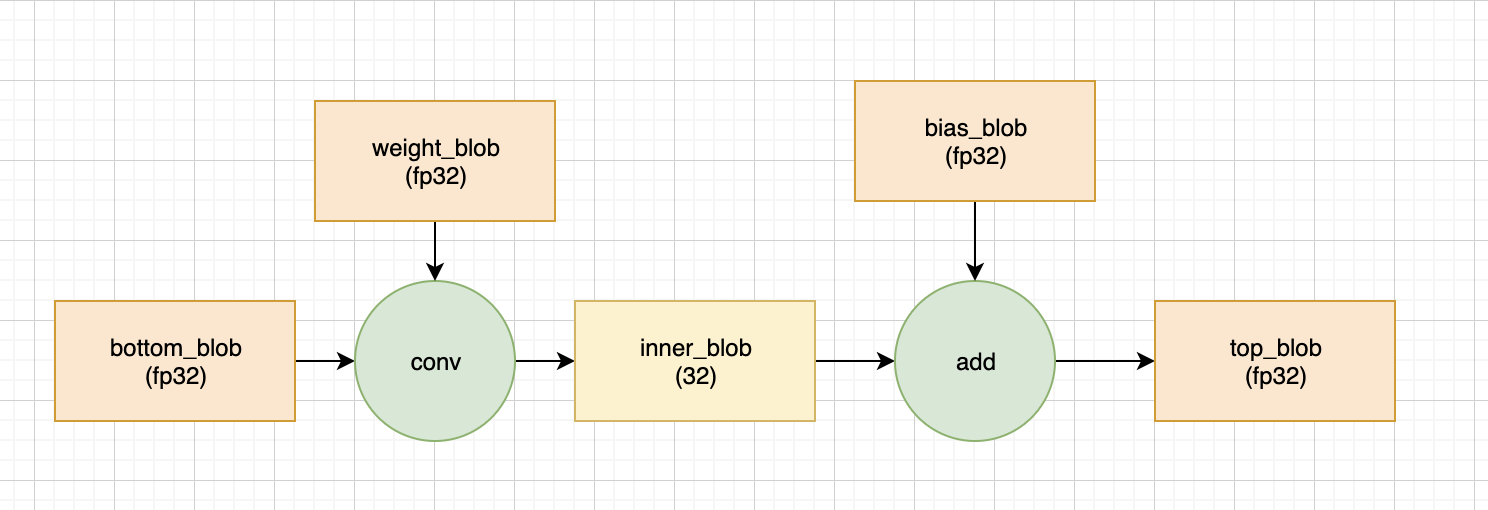
正常的 fp32 计算中, 一个conv 的计算流程如下所示, 所有的数据均是 fp32, 没什么特殊的
在 ncnn conv 进行Int8计算时, 计算流程如下所示,ncnn首先将输入(bottom_blob)和权重量化成Int8,在Int8下计算卷积,然后反量化到 fp32,再和未量化的bias相加,得到输出 top_blob(ncnn并没有对bias做量化)
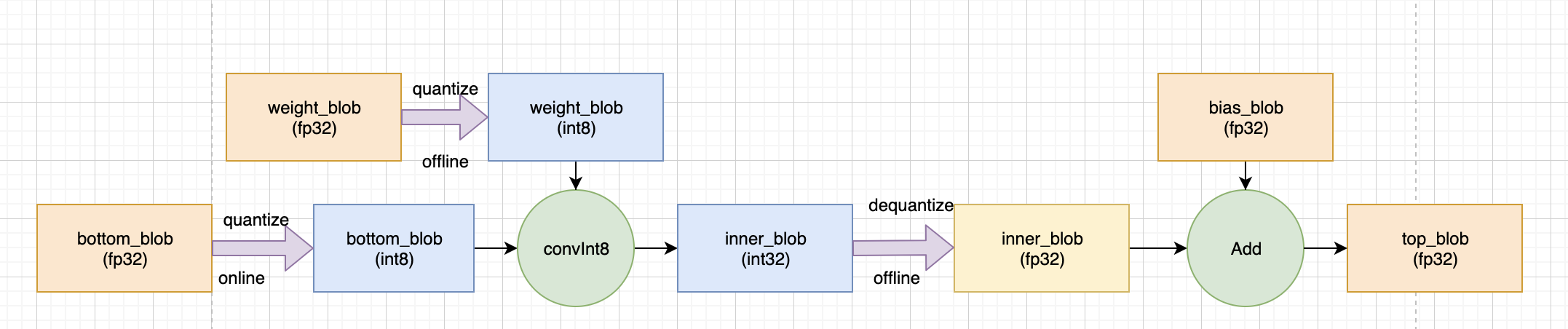
输入和权重的量化公式为:
bottom_blob(int8) = bottom_blob_in8t_scale * bottom(fp32)
weight_blob(int8) = weight_data_int8_scale * weight(fp32)反量化的目的是将int8映射回到原来的fp32,范围保持要一致, 由于 weight_blob(int8) 和 bottom_blob(int8) 相乘, 所以此处的量化反量化的 scale 应该为:
dequantize_scale = 1/(bottom_blob_int8_scale * weight_data_int8_scale)
innner_blob(fp32) = dequantize_scale * inner_blob! 值得注意的是, 权重是在网络初始化时候就进行量化了, 而输入则是在前向推导时进行量化。
4. ncnn 量化工具的使用
(1) Optimization graphic 图优化: 最明显的变化是将conv层和bn层进行合并
./ncnnoptimize mobilenet-fp32.param mobilenet-fp32.bin mobilenet-nobn-fp32.param mobilenet-nobn-fp32.bin(2) Create the calibration table file(建议使用超过5000张图片的验证集进行对齐): 计算产生对应的 scale
./ncnn2table --param mobilenet-nobn-fp32.param --bin mobilenet-nobn-fp32.bin --images images/ --output mobilenet-nobn.table --mean 104,117,123 --norm 0.017,0.017,0.017 --size 224,224 --thread 2(3) Quantization:量化
./ncnn2int8 mobilenet-nobn-fp32.param mobilenet-nobn-fp32.bin mobilenet-int8.param mobilenet-int8.bin mobilenet-nobn.table5. 参考资料
[1] https://me.csdn.net/sinat_31425585
[2] https://zhuanlan.zhihu.com/c_1064124187198705664
[3] https://github.com/BUG1989/caffe-int8-convert-tools
[4] Tencent/ncnn
[5] QNNPACK
[6] Nvidia solution: Szymon Migacz. 8-bit Inference with TensorRT
[7] Google solution:Quantizing deep convolutional networks for efficient inference: A whitepaper
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!