暗光增强
low-light enhancement(暗光增强)
1. End2End
旨在于通过深度学习,对原图进行直接增强。 输入低光照图像,输出正常图像。 代表的方案有 LLCNN、SID、LLNet。
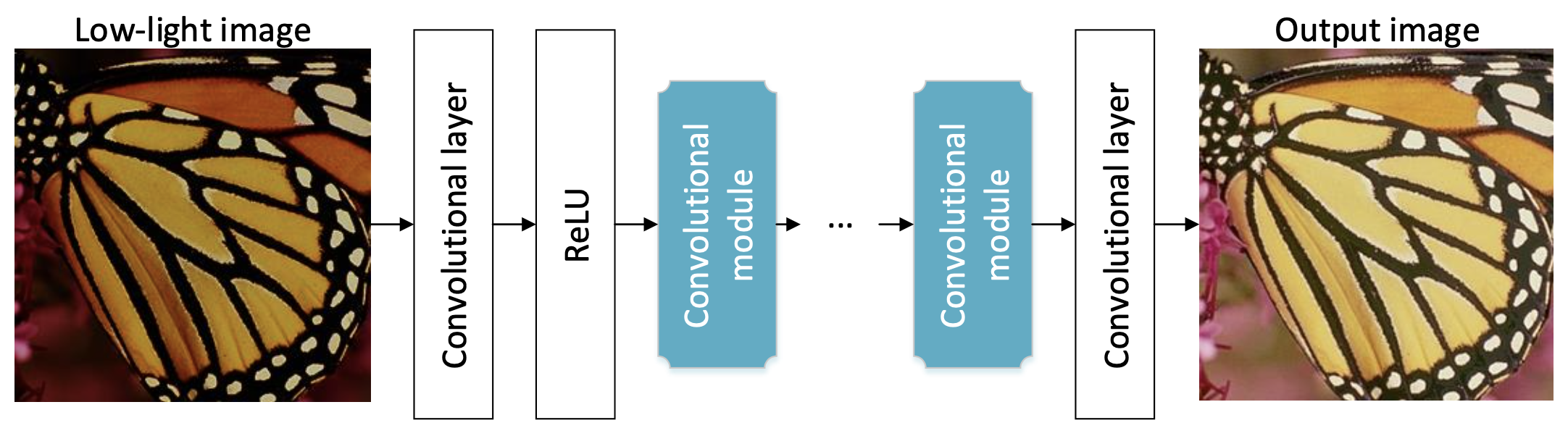
(1) LLCNN
Paper:《LLCNN: A Convolutional Neural Network for Low-light Image Enhancement》
code:https://github.com/BestJuly/LLCNN
主要贡献
作者提出采用 CNN 进行低光图像增强。作者设计了一种特殊的模块处理多尺度特征同时避免了梯度小时问题。为尽可能保留图像的纹理信息,作者采用 SSIM 损失进行模型训练。基于该方法,低光图像的对比度可以自适应增强。作者通过实验验证了所提方法的有效性。
(2) LLnet
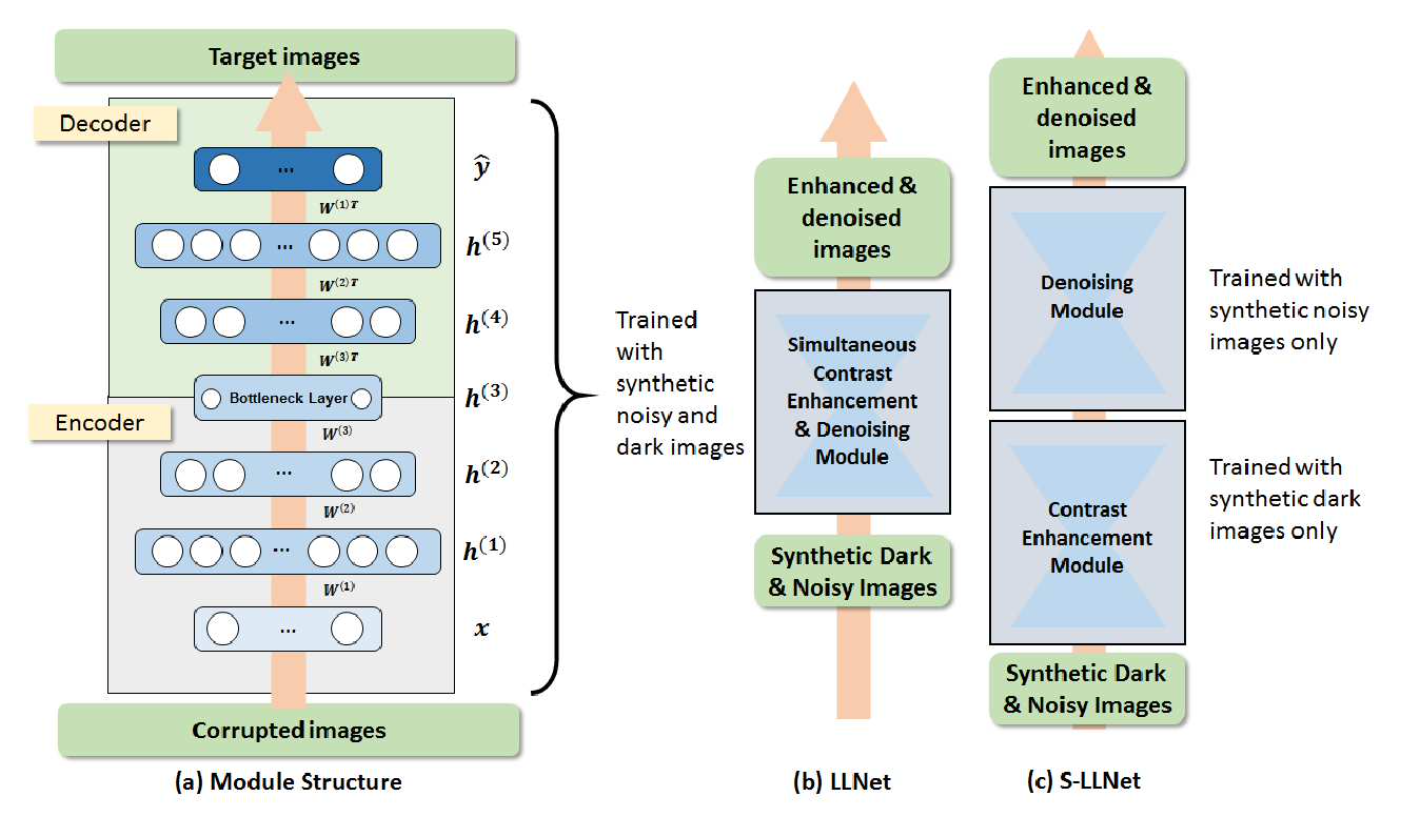
比较早的用深度学习方法完成低光照增强任务的文章,它证明了基于合成数据训练的堆叠稀疏去噪自编码器能够对的低光照有噪声图像进行增强和去噪。模型训练基于图像块(patch),采用 sparsity regularized reconstruction loss 作为损失函数。主要贡献如下:
我们提出了一种训练数据生成方法(即伽马校正和添加高斯噪声)来模拟低光环境。
探索了两种类型的网络结构:(a) LLNet,同时学习对比度增强和去噪;(b) S-LLNet,使用两个模块分阶段执行对比度增强和去噪。
在真实拍摄到的低光照图像上进行了实验,证明了用合成数据训练的模型的有效性。
可视化了网络权值,提供了关于学习到的特征的 insights。
(3) SID
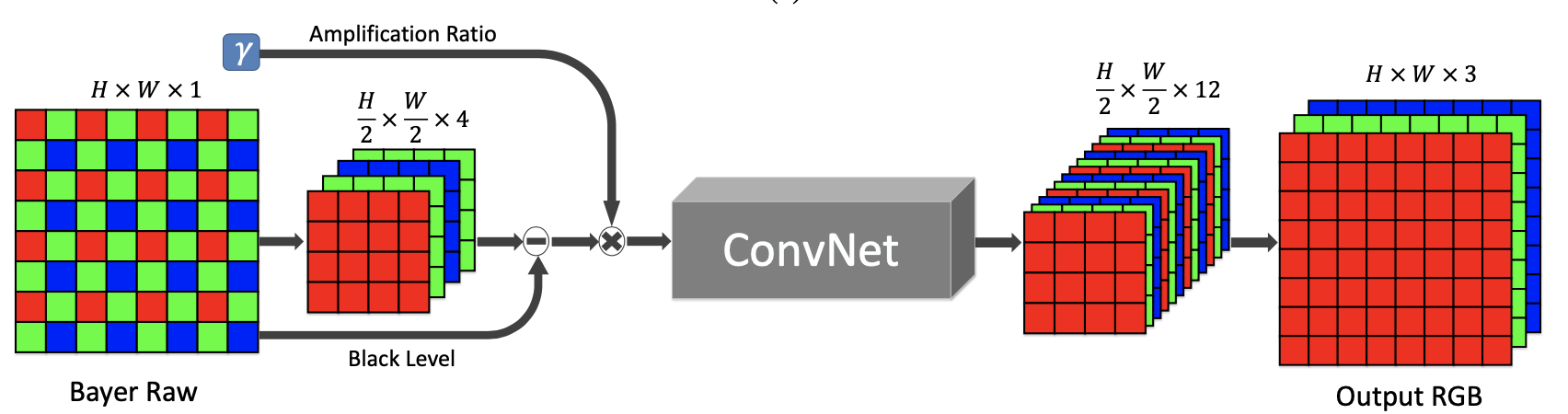
关注于极端低光条件和短时间曝光条件下的图像成像系统,它用卷积神经网络去完成 raw 图像到 RGB 图像的处理,实验效果非常惊艳.网络结构基于全卷积网络 FCN,直接通过端到端训练,损失函数采用 L1 loss。此外,文章提出了数据集 see-in-the-dark,由短曝光图像及对应的长曝光参考图像组成。
2. 进阶版本
将低光照重建分为三个部分:光照估计、去噪、增强重建。
对于光照估计:
(1)利用 retinex 理论将其分解为光照分量和反射分量的方案。 诸如:RetinexNet、kinD、KinD++
(2)直接用网络结构(Unet)进行光照估计。 典型的解决方案有:HDRNet、DeepUPE、GLADNet 和 AGLLE。
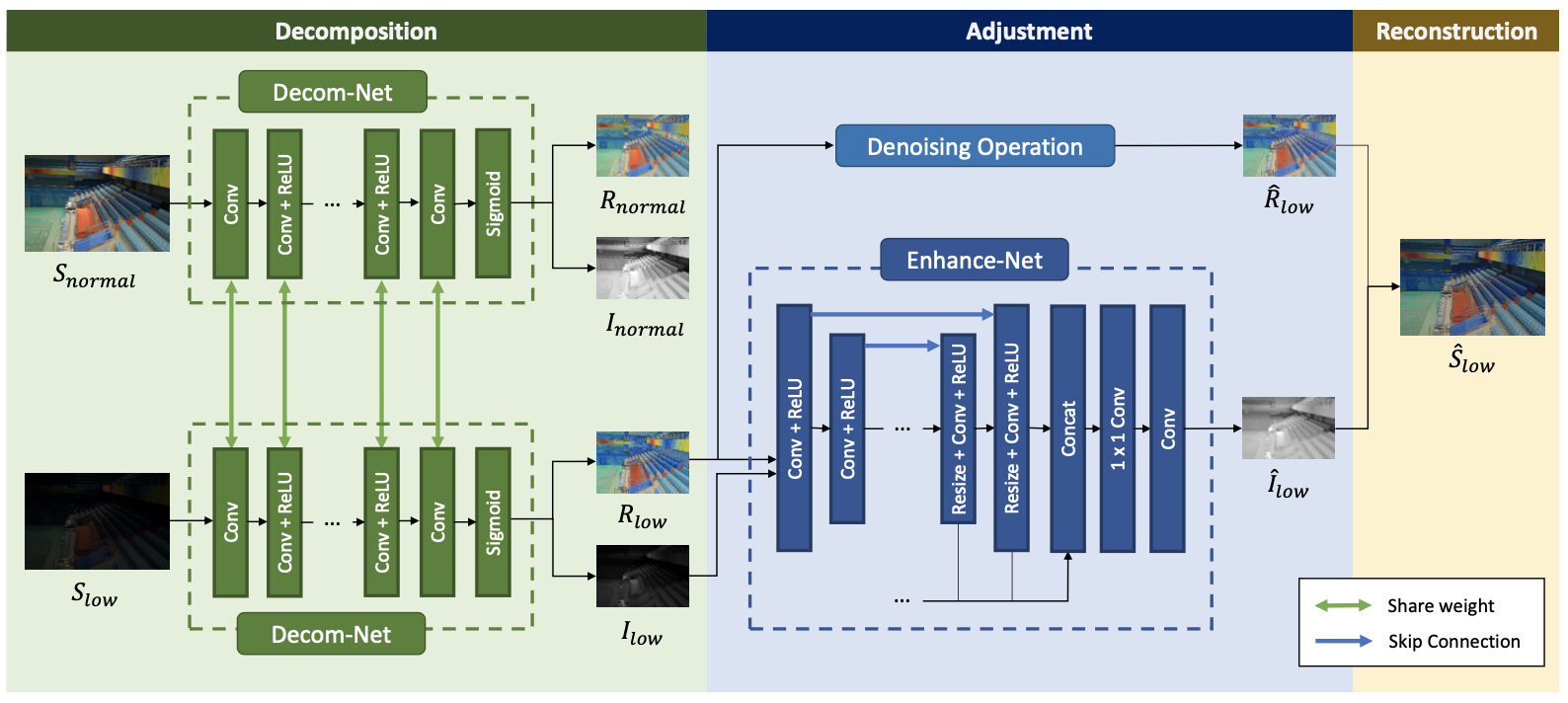
(1) RetinexNet
Paper:《Deep Retinex Decomposition for Low-Light Enhancement》
code:https://github.com/weichen582/RetinexNet
主要贡献:
构建了 paired 的低光照/正常光照数据集LOL dataset,应该也是第一个在真实场景下采集的paired dataset。
提出了RetinexNet,它分为两个子网络:DecomNet 能够对图像进行解耦,得到光照图和反射图;EnhanceNet对前面得到的光照图进行增强,增强后的光照图和原来的反射图相乘就得到了增强结果。另外,考虑到噪声问题,采用一种联合去噪和增强的策略,去噪方法采用 BM3D。
提出一个 structure-aware total variation constraint,就是用 反射图梯度作为权值对 TV loss 进行加权,从而在保证平滑约束的同时不破坏纹理细节和边界信息。
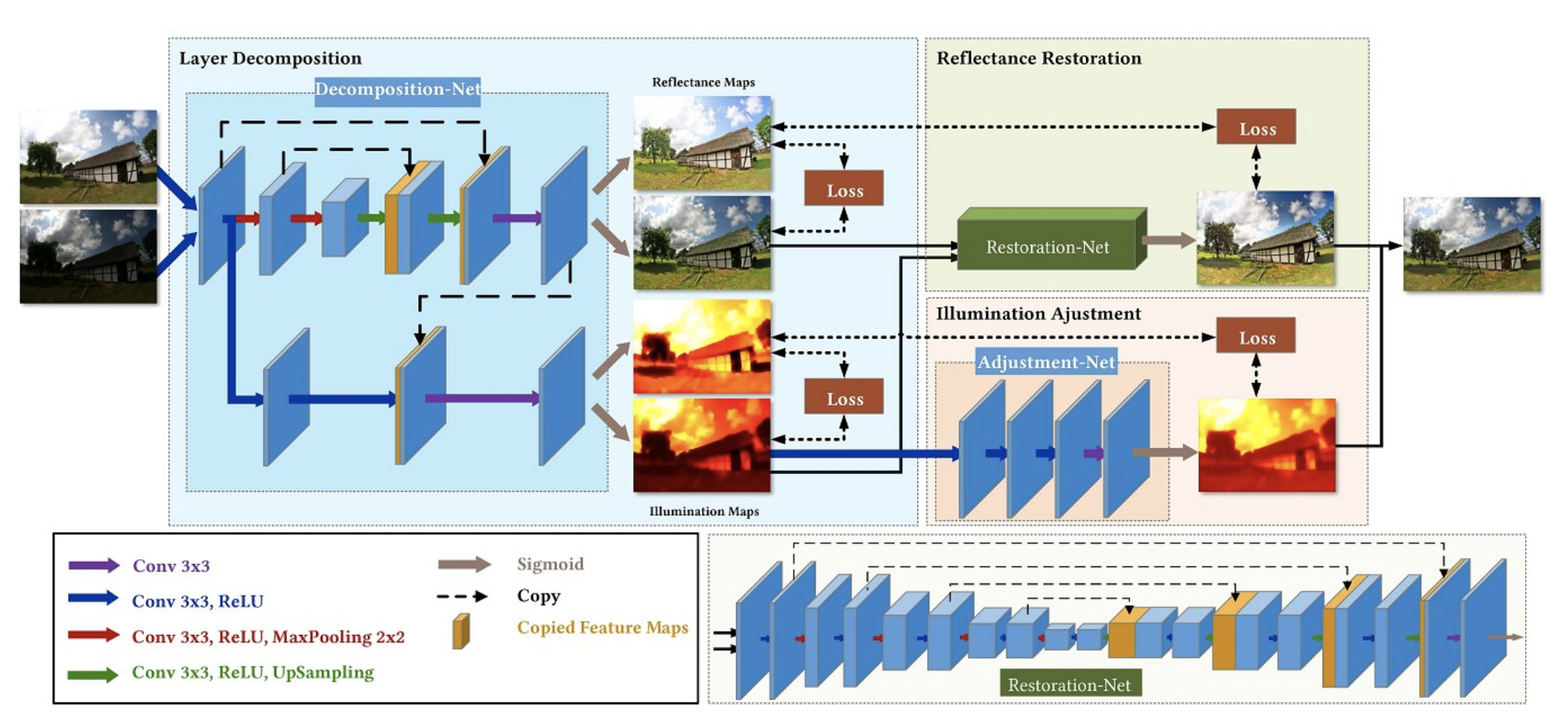
(2) kinD
Paper: 《Kindling the Darkness: A Practical Low-light Image Enhancer》
code:https://github.com/zhangyhuaee/KinD
主要贡献:
文章沿用了 Retinex-Net 的 decomposition->enhance 的两阶段方式,网络总共分为三个模块:decomposition-net、restoration-net和 adjustment-Net,分别执行图像分解、反射图恢复、光照图调整。一些创新点如下:
- 对于Decomposition-Net,其损失函数除了沿用Retinex-Net的重构损失和反射图一致损失外,针对光照图的区域平滑性和相互一致性,还增加了两个新的损失函数。
- 对于Restoration-Net,考虑到了低光照情况下反射图往往存在着退化效应,因此使用了良好光照情况下的反射图作为参考。反射图中的退化效应的分布很复杂,高度依赖于光照分布,因此引入光照图信息。
- 对于Adjustment-Net,实现了一个能够连续调节光照强度的机制(将增强比率作为特征图和光照图合并后作为输入)。通过和伽马校正进行对比,证明它们的调节方法更符合实际情况。
(3) KinD++
(4) MBLLEN (Low-light Image/Video Enhancement Using CNNs)
针对网络中不同层次的特征的提取和融合。提出了针对视频的低光照增强网络,和一帧一帧处理的直接做法不同,它们使用 3D 卷积对网络进行了改进,有效提升了性能。补充说明一下,视频的低光照增强会存在的一种负面情况,闪烁(flickering),即帧与帧之间可能存在不符合预期的亮度跳变。这一问题可以用 AB(avr) 指标 (即平均亮度方差) 来度量。
- 网络结构:包括特征提取模块 FEM、增强模块 EM和融合模块 FM。FEM 是有 10 层卷积的单流向网络,每层的输出都会被输入到各个 EM 子模块中分别提取层次特征。最终这些层次特征被拼接到一起并通过 1x1 卷积融合得到最终结果。为了用于视频增强,还需要对网络进行修改,具体可参考原文。
- 损失函数:本文不采用常规的 MSE 或者 MAE 损失,而是提了一个新的损失函数,包括三个部分,即结构损失、内容损失和区域损失。结构损失采用 SSIM 和 MS-SSIM 度量相结合的形式;内容损失,就是 VGG 提取的特征应该尽可能相似;区域损失令网络更关注于图像中低光照的区域。
(5) HDRNet、DeepUPE -> 使用双边卷积
3. 其他
- 结合热点趋势, 对网络进行补充设计, 典型的结合方案有:transformer、注意力机制、图网络、光场、trsnsformer 模型
- 结合 raw 域到 图像域,真实场景、基于 DSP 的设计、手机端 phone的暗光增强 和 轻量级暗光增强设计方案
- 几篇较新的论文:GLADNet、DPED、Attention-Based 和 Attention-Guided
4. Datasets
| Datasets | Description | Download Link |
|---|---|---|
| LOL | contains 500 low/normal-light image pairs captured in real scenes and 1000 synthetic image pairs | https://daooshee.github.io/BMVC2018website/ |
| SID | contains 5094 raw short-exposure images, each with a corresponding long-exposure reference image. Images were captured using two cameras: Sony α7S II and Fujifilm X-T2 | http://vladlen.info/publications/learning-see-dark/ |
| MIT-FiveK | 5,000 photos in DNG format,an Adobe Lightroom catalog with renditions by 5 experts | https://data.csail.mit.edu/graphics/fivek/ |
| DPED | including 4549 photos from Sony smartphone, 5727 from iPhone and 6015 photos from BlackBerry | http://people.ee.ethz.ch/~ihnatova/ |
| ExDARK | a collection of 7,363 low-light images from very low-light environments to twilight with 12 object classes. | https://github.com/cs-chan/Exclusively-Dark-Image-Dataset |
5. 上采样方式
插值[插值包含双线性插值、三线性插值和最近邻插值]
常用的方法是:插值 + 卷积。 使用双线性插值和最近邻插值两者所得到的效果并没有什么差异, 因此最建议的方案是:最近邻插值 + 卷积
反卷积:使用反卷积会产生棋盘格效应。
什么时候会出现 ?当卷积核大小不能被步长整除的时候,会出现棋盘现象
为什么会出现 ?
通道重组 pixelshuffle
6. 常见的 loss 和评价指标
(1) pixel loss
针对于像素点的损失, 比较常见, 如常见的 l1 loss、l2 loss、charborn loss 等。
(2) retinex 采用了三种损失函数
- 重建损失(首先将增强后的光照图 * 反射图得到我们需要的图像, 然后和正常的图像求 l1损失即可)
- 反射一致性损失(两张分解的反射图求 l1 损失即可)
- 光照平滑损失: 根据一些先验知识, 一张自然的图片的梯度是趋于零的, 一张图片,其变化的部分往往很少。这被叫做区域一致性。
原始的 TV loss 直接定义为如下公式,可以看到使用两个方向上的梯度对其进行卷积,得到的结果取绝对值然后加和。
为什么使用这个损失函数? 这样可以尽可能的让图片平滑,因为这里让相邻两个像素点的值相近。 这里的光照平滑损失加权了反射图的 $e^{(-\lambda(\bigtriangledown(反射图))}$。主要目的是让反射图比较平滑的地方在光照图上也比较平滑。当说明反射图越平滑,反射图两个像素点的差值越小,对应的 $e^{(-\lambda(\bigtriangledown(反射图))}$ 越大, 对两点的光照图施加的约束越大。光照图才更平滑。
(3) 其他
梯度损失 -> TV(总变分) -> retinex 和 kind 中的光照平滑损失
ssim loss:比较的不单单是单一的像素值的差异,其纹理和质感比较重要 !
给定一张图像, 稍微(加减)像素值, 其结构(strusture) 基本不变, 但是其 psnr 却会发生很大变化,psnr 基于 l2, 所以 l2 损失函数并不适合。对于 暗光增强任务, 其纹理、质感更重要,而亮度应该有所调整。
zero loss 、感知损失(texture、content)、gan 损失
7. 一些思考
暗光增强和 SR / image denoising 有什么不同?
SR / DeNoising 退化的图片的像素值在原图附近,而平均像素值几乎不变。为啥没有使用 全局残差连接? a. 暗光增强(与超分和去噪相比) 退化图像与原图差异大, 因此学习一个残差图非常困难 b. 模块已经存在局部残差连接
光照估计(illumination estimation)和低光照增强(low-light enhancement)的区别?
光照估计是一个专门的底层视觉任务(例如[1,2,6]),它的输出结果可以被用到其它任务中,例如图像增强、图像恢复。而低光照增强是针对照明不足的图像存在的低亮度、低对比度、噪声、伪影等问题进行处理,提升视觉质量。低光照增强方法有两种常见的模式,一种是直接 end-to-end 训练,另一种则包含了光照估计。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!