推理引擎设计技巧
1. 基于C/C++的基本优化
编译器很牛逼,GCC/CLANG 都有运行速度的优化选项,打开这些选项能帮助程序显著提升速度,虽然这还远远不够,但聊胜于无吧。
下面是 ncnn 示例项目中的一段代码:
# ncnn/examples/squeezencnn/jni/Android.mk LOCAL_CFLAGS := -O2 -fvisibility=hidden -fomit-frame-pointer -fstrict-aliasing -ffunction-sections -fdata-sections -ffast-math LOCAL_CPPFLAGS := -O2 -fvisibility=hidden -fvisibility-inlines-hidden -fomit-frame-pointer -fstrict-aliasing -ffunction-sections -fdata-sections -ffast-math LOCAL_LDFLAGS += -Wl,--gc-sections以前工作时候写的CMakeLists 中的代码:
# set(CMAKE_BUILD_TYPE Release) if (CMAKE_BUILD_TYPE STREQUAL "Debug") set(CMAKE_CXX_FLAGS_DEBUG "$ENV{CXXFLAGS} -O0 -Wall -g2 -ggdb") message(STATUS "CMAKE_BUILD_TYPE = Debug") else() set(CMAKE_CXX_FLAGS_RELEASE "$ENV{CXXFLAGS} -O3 -Wall") message(STATUS "CMAKE_BUILD_TYPE = Release") endif()书写高效的C代码。循环展开、内联、分支优化,避免除法,查表等优化小技巧要滚瓜烂熟,信手拈来。
必须看得懂汇编,即使你不写,也要知道编译器编译出来的汇编代码效率如何。这样你可以通过调整C/C++代码,让编译器生成你需要的代码。
2. 缓存友好
(1)少用内存
(2)连续访问、对齐访问、合并访问、显示对齐数据加载、缓存预取
3. 多线程
1. OpenMP
OpenMP会自动为循环分配线程,使用OpenMP加速只需要在串行代码中添加编译指令以及少量API即可。理想情况下,加速比大约能达到0.75*cores。
// ncnn/src/layer/relu.cpp
int ReLU::forward_inplace(Mat& bottom_top_blob, const Option& opt) const
{
if (bottom_top_blob.elemsize == 1u)
return ReLU::forward_inplace_int8(bottom_top_blob, opt);
int w = bottom_top_blob.w;
int h = bottom_top_blob.h;
int channels = bottom_top_blob.c;
int size = w * h;
if (slope == 0.f)
{
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
for (int i=0; i<size; i++)
{
if (ptr[i] < 0)
ptr[i] = 0;
}
}
}
else
{
#pragma omp parallel for num_threads(opt.num_threads)
for (int q=0; q<channels; q++)
{
float* ptr = bottom_top_blob.channel(q);
for (int i=0; i<size; i++)
{
if (ptr[i] < 0)
ptr[i] *= slope;
}
}
}
return 0;
} 但并非所有循环都适合做多线程优化,如果每次循环只做了非常少的事情,那么使用多线程会得不偿失。实际运用中,可以通过 #pragma omp parallel for if (cond) 语句来判断runtime过程中是否要启用多线程。
动态调度
稀疏化
定点化
NEON 汇编
4. 内存精简
每个layer都会产生blob,除了最后的结果和多分支中间结果,大部分blob都可以不保留,开启ncnn的轻模式可以在运算后自动回收,省下内存。 如下图所示:
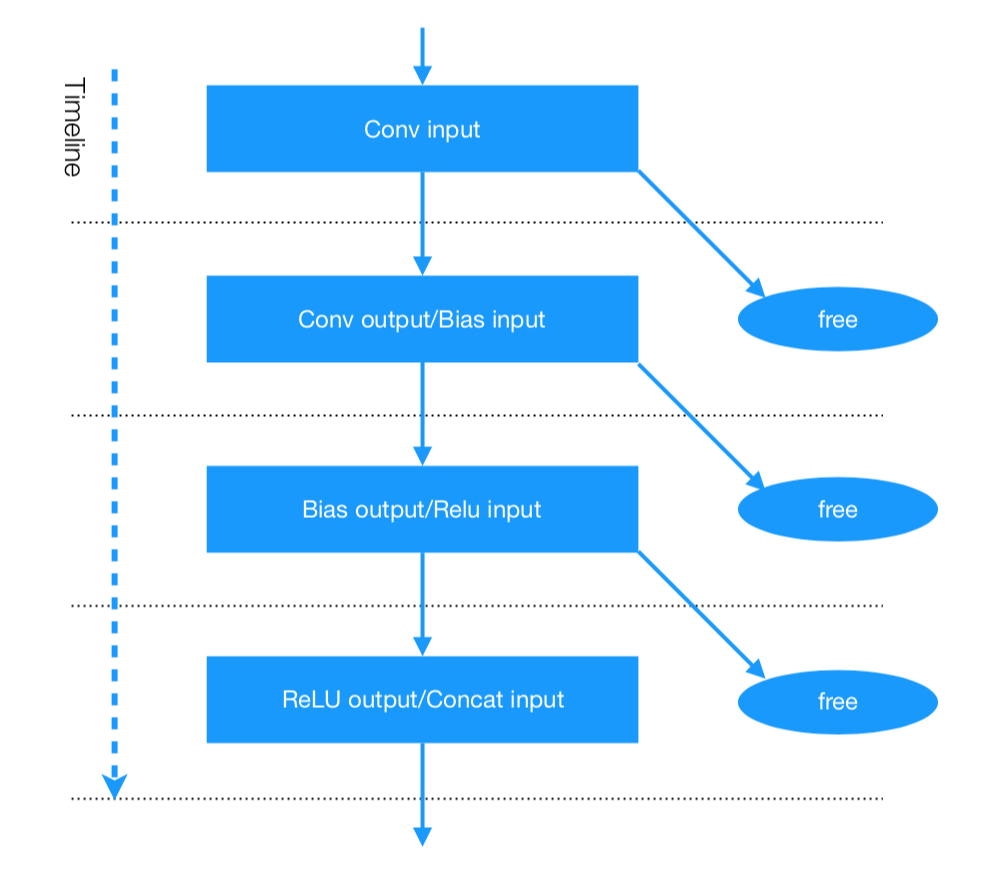 某网络结构为
某网络结构为 Conv -> Bias -> ReLU -> Concat,在轻模式下,向ncnn索要Concat结果时,Conv结果会在运算Bias时自动回收,而Bais结果会在运算ReLU时自动回收,而ReLU结果会在运算Concat时自动回收, 最后只保留Concat结果,后面再需要C结果会直接获得,满足绝大部分深度网络的使用方式。ncnn 开启轻模式仅需要一行代码:
set_light_mode(true)相关参考资料:
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!