YOLO
YOLO series: YOLO v1. YOLO v2 and. YOLO v3
1. YOLO v1
核心思想
直接在输出层回归 bounding box 的位置和 bounding box所属的类别(整张图作为网络的输入,把 Object Detection 的问题转化成一个 Regression 问题)
YOLO v1 流程

将图片Resize成448x448,分成7x7个网格(grid cell),某个物体的中心落在这个网格中此网格就负责预测这个物体。
提取特征和预测,卷积部分负责提取特征。全连接部分负责预测:
- 两个 【bounding box(bbox) + confidence】 (2x5)
- 20个物体的概率(20)
总的输出为 (7X7)X30 的维度。
过滤bbox(通过nms)
2. YOLO v2
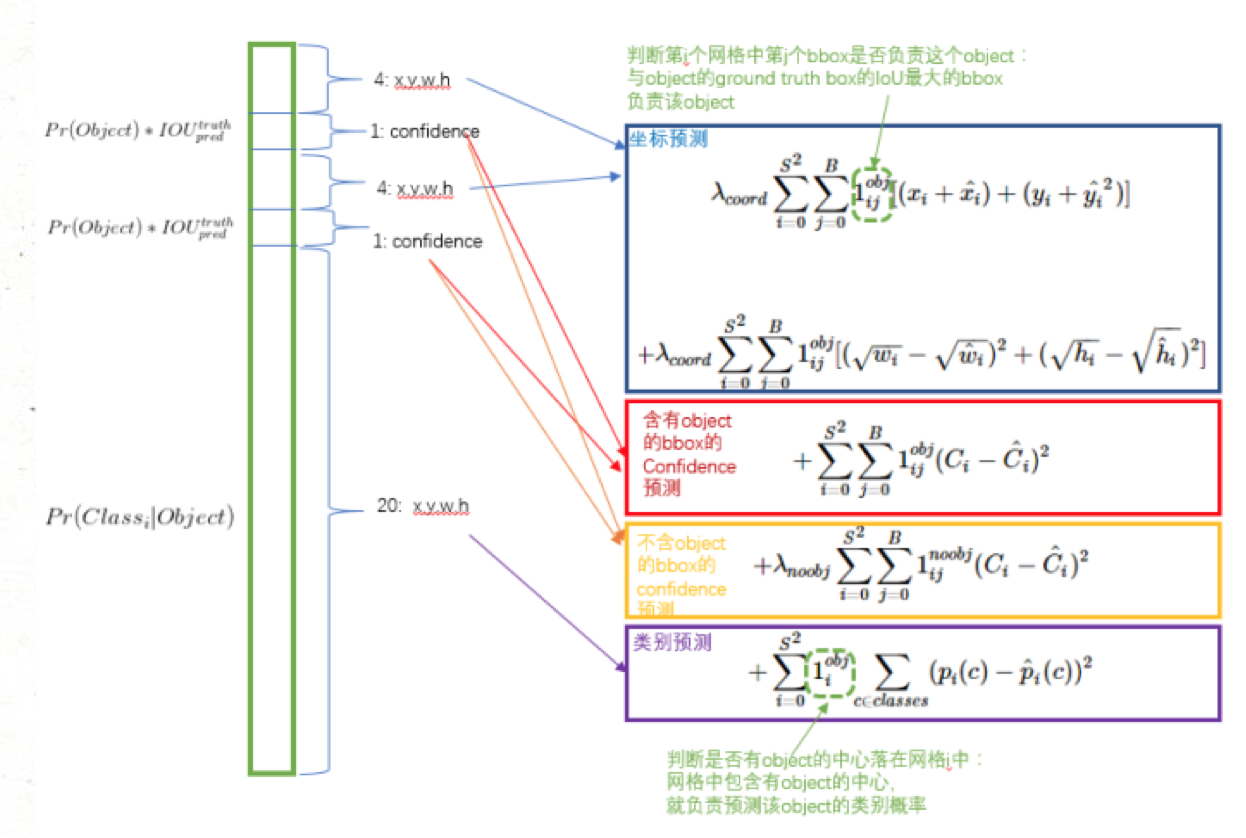
class-specific confidence score:
class-specific confidence score 是三项的成绩。第一项是 bbox每个网格预测的类别信息即20个物体的概率, 第二项是每个 bbox 的置信度, 第三项是 ground truth 和 预测框的 IOU。得到每个bbox的class-specific confidence score以后,设置阈值,滤掉得分低的boxes,对保留的boxes进行NMS处理,就得到最终的检测结果
损失函数的设计:
3. YOLOv3
论文改进点
BN + leaky ReLU + res connection[ 加入了BN层, 激活函数使用了Leaky ReLU, 并且引入了残差连接 ]
backbone(FPN multi scales)[ 仿照FPN网络结构的多尺度检测 ]
loss function [ 除了w、h仍然使用平方均差, 其他均使用交叉熵。然后按权重相加 ]
bbox anchor priors -> softmax [ 聚类获得先验框大小 ]
(1) YOLOv3 结构
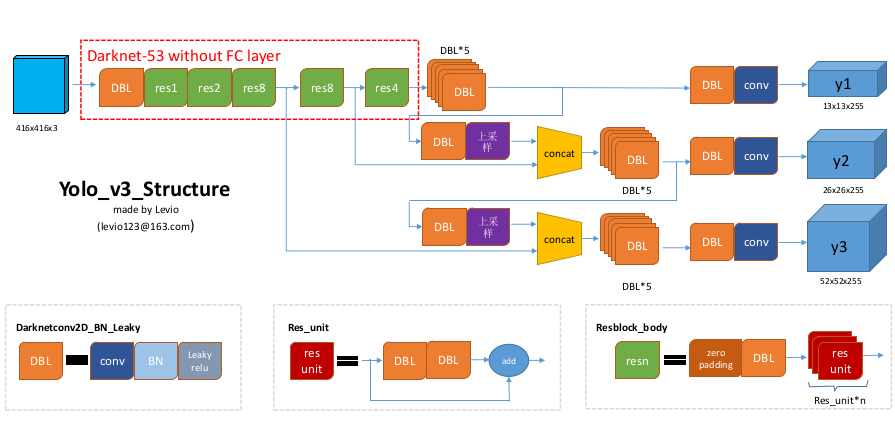
先使用 DBL (conv+bn+leaky_relu) 进行一个简单的滤波处理, 然后接res1, res2, res8 提取特征1, 再接 res8 提取特征2, 再接 res4 提取特征 3, 最后融合三个特征。
- 相比于 YOLO V2 的 darknet19 采用 maxpool 进行下采样, YOLO V3 提出的 Darknet53 则使用 stride 为 2 的卷积核来实现下采样。在 YOLO v3 中, 要经历五次下采样, 特征图尺寸缩小为原来的 1/32, 即输入为 416 x 416, 输出为 13x13。
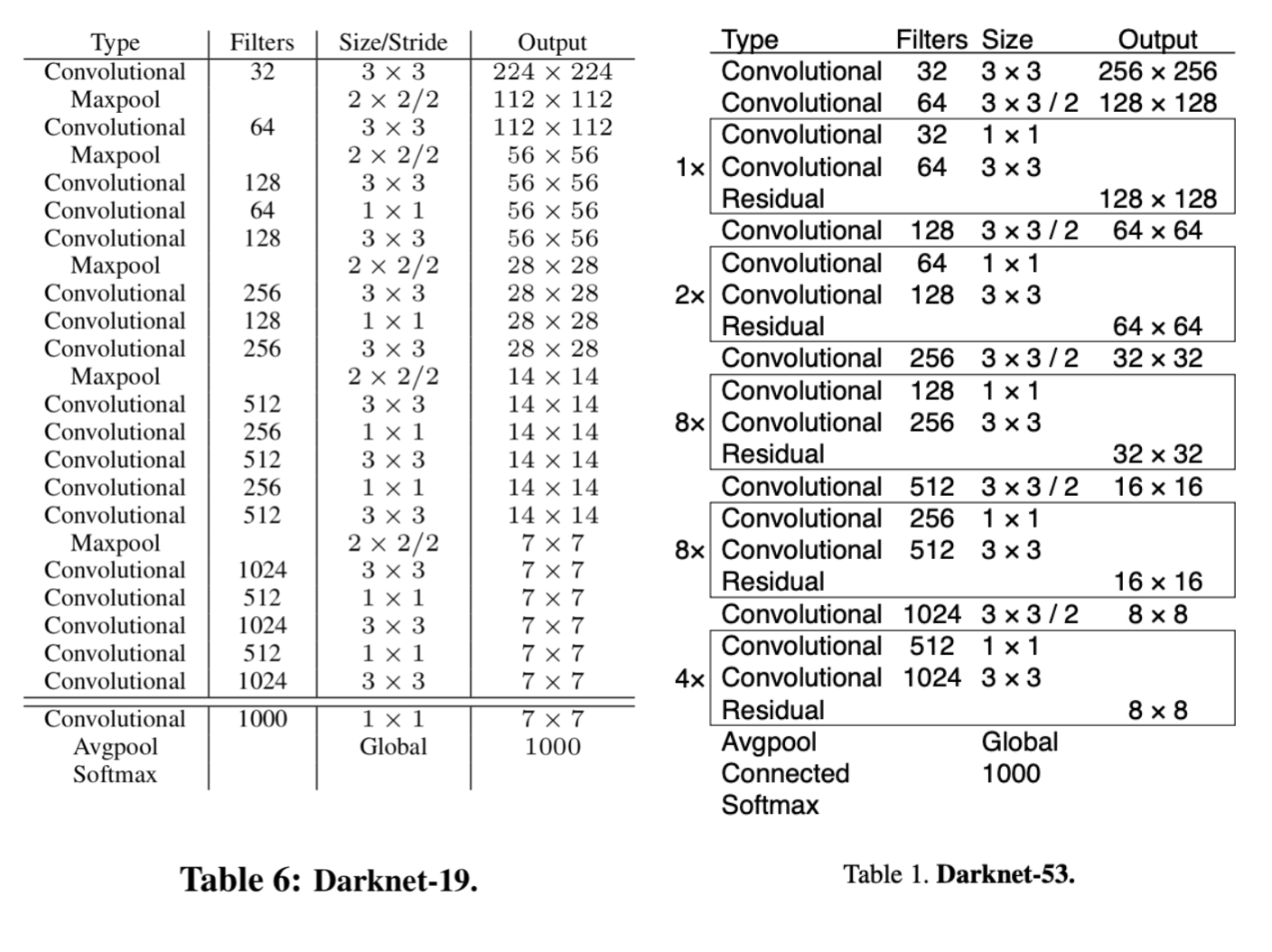
具体的细节实现上, darknet 19 的 conv + bn + relu 被替换为 conv + bn + leaky_relu。并在此基础上添加了残差结构。
三个输出分别是 13x13x255、26x26x255、52x52x255。yolo v3 输出了3个不同尺度的 feature map,YOLO v3 借鉴了 FPN(feature pyramid networks),采用多尺度来对不同 size 的目标进行检测,越精细的 grid cell 就可以检测出越精细的物体。
255的来源 ? COCO 的类别数为 80, 加上位置信息 x, y, w, h 和 confidence 为 85。每个网格单元预测 3 个 box。 总共为 3 *( 80 + 5) = 255。
(2) 损失函数
在 YOLO v3除了w、h 仍然使用平方均差, 其他 (x, y)、 class, confidence 均使用交叉熵,然后按权重相加,损失函数应该由各自特点确定。最后加到一起就可以组成最终的 loss_function 了,也就是一个loss_function搞定端到端的训练。
xy_loss = object_mask * box_loss_scale * K.binary_crossentropy(raw_true_xy, raw_pred[..., 0:2], from_logits=True)
wh_loss = object_mask * box_loss_scale * 0.5 * K.square(raw_true_wh - raw_pred[..., 2:4])
confidence_loss = object_mask * K.binary_crossentropy(object_mask, raw_pred[..., 4:5], from_logits=True) + \
(1 - object_mask) * K.binary_crossentropy(object_mask, raw_pred[..., 4:5],
from_logits=True) * ignore_mask
class_loss = object_mask * K.binary_crossentropy(true_class_probs, raw_pred[..., 5:], from_logits=True)
xy_loss = K.sum(xy_loss) / mf
wh_loss = K.sum(wh_loss) / mf
confidence_loss = K.sum(confidence_loss) / mf
class_loss = K.sum(class_loss) / mf
loss += xy_loss + wh_loss + confidence_loss + class_loss以上是一段 keras 框架描述的 yolo v3 的 loss_function 代码。忽略恒定系数不看,可以从上述代码看出:除了 w, h 的损失函数依然采用均方误差之外,其他部分的损失函数用的是交叉熵。最后加到一起。
(3) Bounding Box Prediction
对于YOLO v3 而言,在 prior 这里的处理有明确解释:选用的 bbox priors 的 k=9,对于 tiny-yolo 的话,k = 6。priors 都是在数据集上聚类得来的,有确定的数值,如下:
10,13, 16,30, 33,23, 30,61, 62,45, 59,119, 116,90, 156,198, 373,326 每个 anchor prior 就是两个数字组成的,一个代表高度另一个代表宽度。 v3对b-box进行预测的时候,采用了logistic regression。输出和v2一样都是 (t_x, t_y, t_w, t_h, t_o),然后通过公式1计算出绝对的 (x, y, w, h, c) 。
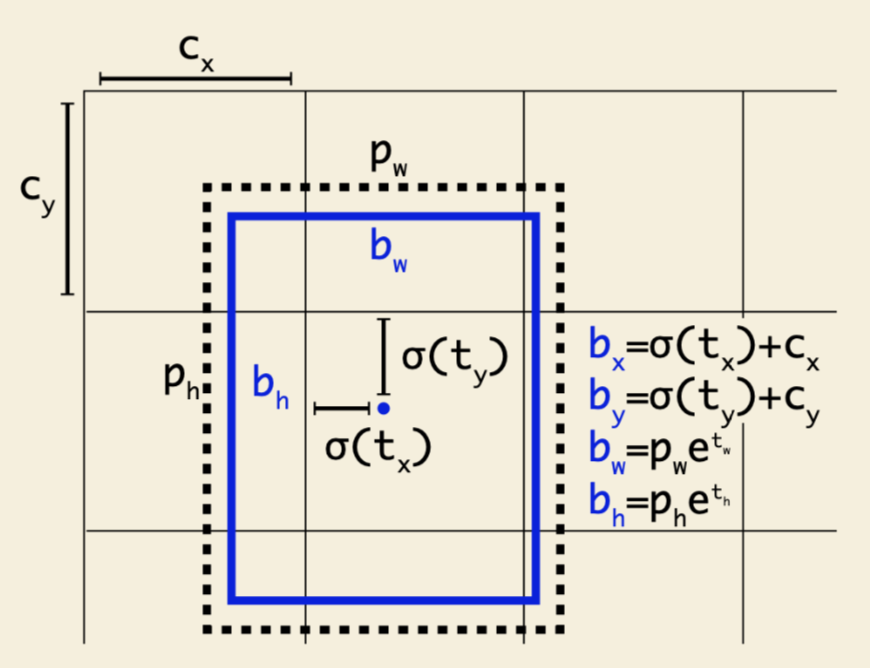
logistic回归用于对anchor包围的部分进行一个目标性评分(objectness score),即这块位置是目标的可能性有多大。这一步是在predict之前进行的,可以去掉不必要anchor,可以减少计算量。
4. YOLOv4
5. YOLOv5
6. PP-YOLO
7. Bag of Freebies
论文《Bag of Freebies for Training Object Detection Neural Networks》提炼了目标检测算法通用训练 tricks,论文说是 Bag of Freebies,并且更倾向于对 One-stage 系列优化,one-stage 计算量更小,在落地上更为普遍。
二、目标检测训练Tricks
论文[1]总共提到了六种通用的训练Tricks,其中有几种在yolov3原始算法中都有用到,所以说不得不承认yolo系列是非常优秀的目标检测算法。具体为
1、Visually Coherent Image Mixup for Object Detection (mixup数剧增强,借鉴文[2])
与[2]原始的mixup不同点有两点:
1)文[2]提出的mixup数据增强是一种有特色方法,但是实验对象是分类与对抗生成网络,成对图像的mixup是以resize到相同大小的图像为前提完成的。

目标检测问题中如果resize图像到相同大小则会造成图像畸变,检测任务对于这种变化较为敏感,因此作者采用保图像几何形状的方式对图像进行mixup,我的理解是图像直接mixup成对图像,取最大宽高并填充(constant合成的空白区域),最后计算损失时按照mixup的beta分布产生的权重,对损失进行加权求和,再反向传播loss更新模型权重。

2)文[2]的mixup方法中成对图像求加权和的权重是由Beta分布随机生成(Beta分布如图),Beta的两个参数默认取值1.0(源码),原始mixup论文[2]试验则是从0.2到1.0的几组试验值,论文[1]采用的Beta分布两个参数则是取值大于等于1,在实验中Beta分布的参数值取1.5时效果更好,涨点明显:
 。
。

4. 标签平滑 label smoothing
label smoothing 个人感觉则是对标签放松处理(改变类别的分布),使得目标函数不至于太严格,降低不同类别的置信度,一定程度上使得模型更易于收敛且能避免模型过拟合(over fitting)。对目标类别的 Ground Truth 做如下处理,对原始标签乘上一个小于 1 且接近于 1 的数,再加上一个类似正则项的东东,其实也就是一种对目标函数做的正则化处理。

其中,K 为类别数目,分子为小正数, 一般取 0.1 。具体的描述可以参看论文[3]。
for images, labels in train_loader:
...
N = labels.size(0)
# C is the number of classes.
smoothed_labels = torch.full(size=(N, C), fill_value = 0.1 / (C - 1)).cuda()
smoothed_labels.scatter_(dim=1, index=torch.unsqueeze(labels, dim=1), value=0.9)
...5. 数据预处理 Data Preprocessing
文章着重评估了常见的图像增强方法:
- 几何变换:随机裁剪、随机扩张、随机水平翻转、随机 resize
- 颜色抖动:亮度、色调、曝光度、对比度调整
6. Training Scheduler Revamping(训练策略改进)
这里主要采用的方案是: warmup + cosine schedule
7. Synchronized Batch Normalization
这个策略是针对土豪提的,对于大规模数据集的多卡训练,Batch会被分割成很多小部分(小 Batch)在不同的显卡,这样实际上虽然加速了训练,但是Batch却变小了,可能会限制Batch Normalization的作用,与大Batch训练的初衷向左。对于分类问题可能影响不到,但是对于对Batch敏感的目标检测任务则影响很大。基于此采用Synchronized Batch Normalization。
8、Random shapes training for single-stage object detection networks 多尺度训练
在训练的过程中, 每隔一定的 iterations 就改变训练图片的尺度,这样做可以实现跨尺度特征融合,也能使得模型在多种输入大小下训练以适应不同的图像大小输入。这样做也可以使得模型不容易过拟合以增强泛化性能。
8. YOLO 的轻量级改进型
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!