receptive_size_and_anchor_design
octave conv(octconv)、hetconv、res2net
1. 感受野的计算:
# [kernel_size, stride, padding]
convnet = [[11,4,0], [3,2,0], [5,1,2], [3,2,0], [3,1,1], [3,1,1], [3,1,1], [3,2,0]]
layer_names = ['conv1','pool1','conv2','pool2','conv3','conv4','conv5','pool5']
input image: receptive size: 1
conv1: receptive size: 11
pool1: receptive size: 19
conv2: receptive size: 51
pool2: receptive size: 67
conv3: receptive size: 99
conv4: receptive size: 131
conv5: receptive size: 163
pool5: receptive size: 195(1) 反向推导:
- 初始(最后) $feature map$ 层的感受野是1。
- 每经过一层 kernelsize为 k, 步长为 s的卷积/池化层,感受野 $r{l} = r \times s + (k-s) = (r_{l+1} -1) \times s + k$ 。
- 经过多分支的路径,按照感受野最大支路计算。
- 不会改变感受野的情况: conv1x1 s1、ReLU、BN、dropout、shotcut等元素级操作。
- 经过FC层和Gobal Ave Pooling 层,感受野就是整个输入图像。
以 pool5 为例:
Pool5: (1-1)*2 + 3 = 3
Conv5: (3-1)*1 + 3 = 5
Conv4: (5-1)*1 + 3 = 7
Conv3:(7-1)*1 + 3 = 9
pool2: (9-1)*2 + 3 = 19
Conv2: (19-1)*1 + 5 = 23
Pool1: (23-1)*2 + 3 = 47
Conv1: (47-1)*4 + 11 = 195(2) 正向推导
和反向推导相似, $s_0 = 1$, $feature_map$ 的感受野为1。
以 pool5 为例:
Conv1: 1 + (11-1)*1 = 11, s1=1*4=4 # [11,4,0]
Pool1: 11 + (3-1)*4 = 19, s2=4*2=8 # [3,2,0]
Conv2: 19 + (5-1)*8 = 51, s3=8*1=8 # [5,1,2]
pool2: 51 + (3-1)*8 = 67, s4=8*2=16 # [3,2,0]
Conv3: 67 + (3-1)*16 = 99, s5=16*1=16 # [3,1,1]
Conv4: 99 + (3-1)*16 = 131, s6=16*1=16 # [3,1,1]
Conv5: 131 + (3-1)*16 = 163, s7=16*1=16 # [3, 1, 1]
Pool5: 163 + (3-1)*16 = 195, s8=16*2=32 # [3, 2, 0][https://fomoro.com/projects/project/receptive-field-calculator]
2. 卷积的有效感受野
上文所述的是理论感受野,而特征的有效感受野(实际起作用的感受野)实际上是远小于理论感受野的,如下图所示。具体数学分析比较复杂,不再赘述,感兴趣的话可以参考论文 [Understanding the Effective Receptive Field in Deep Convolutional Neural Networks]。

下面我从直观上解释一下有效感受野背后的原因。以一个两层 
很容易可以发现,
3. anchor 设计原则:
anchor的本质是特征层的map,这和传统cv中的滑动窗口并无二致。我们的目标是生成更好的窗口去匹配bbox。faster rcnn 是通过CNN 来自动生成 anchor,利用了 CNN 自动提取特征的能力。
anchor 设计原则:
(1) anchor 的尺寸、长宽比、位置都应该 match 源数据中的bbox。一种方法是针对特定数据集设计anchor,如YOLOv2中的聚类,和近期有论文CNN训练anchor的设置,这些方法或许更适合某一数据集,但也可能影响模型的泛化能力,换一个库是否依然够用。
(2) anchor 的 size 必须小于感受野
(3) 不同size的anchor应当具有相同的空间密度分布。密度一致的话,要求 anchor/stride 为一个定值。
下面以人脸检测为例,来分析 anchor 的设计:
(1)MSFD 中通过分析 WIDER Face 中人脸的范围,进而将 anchor 的尺寸设定为
16/32/64/128/256/512 这些范围,从而覆盖不同尺寸的人脸。anchors’ aspect ratio 则设定为1: 1.5 。这是考虑到人脸的形状宽高比为 1.5 这一事实。
(2) S3FD 中提出的两条设计原则。我们看到 anchor 小于感受野,大约为感受野的 1/4, stride 则均为 anchor 的 1/4。这保证了anchor 的密度一致。
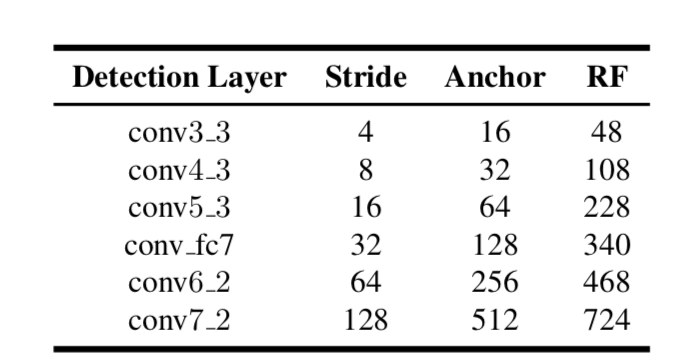
我们来看Faceboxes中的anchor 设计:
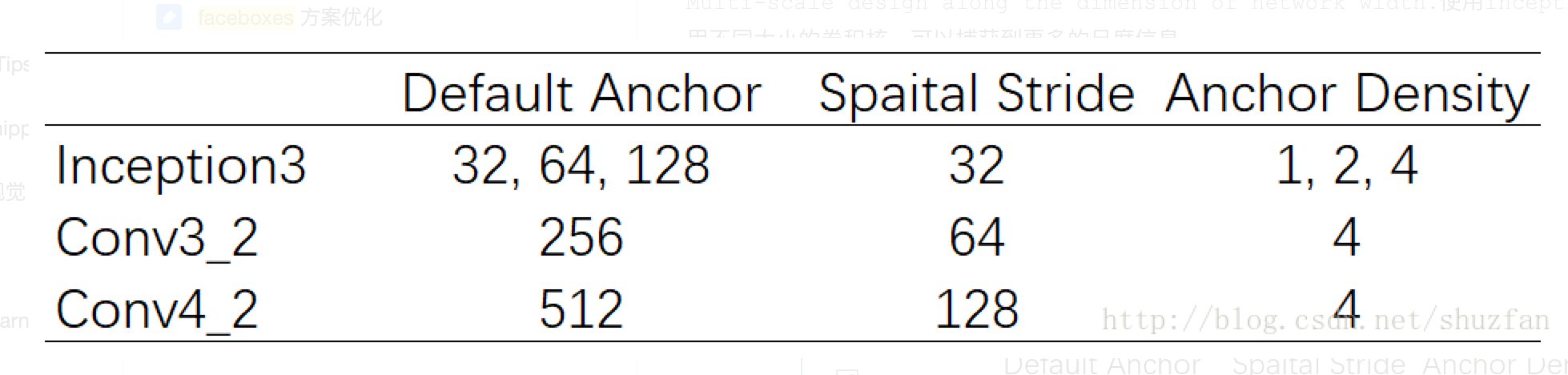
这里 32 和 64 的anchor 密度为1和2,小于其他的密度4,所以通过对 32 复制4次,对64 复制两次来使anchor 密度一致。
[1]SSD:Single Shot MultiBox Detector
[2] YOLOv3: An Incremental Improvement
[3]FPN: feature pyramid networks for object detection
[4] A practical theory for designing very deep convolutional neural networks
[5] S3FD: Single Shot Scale-invariant Face Detector
[6] FaceBoxes: A CPU Real-time Face Detector with High Accuracy
[7] https://medium.com/@andersasac/anchor-boxes-the-key-to-quality-object-detection-ddf9d612d4f9
[8] https://www.reddit.com/r/MachineLearning/comments/7giwk1/d_is_anchor_necessary_for_object_detection/
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!