recent convolutions
octave conv(octconv)、hetconv、res2net
1. octave conv
Paper:
Drop an Octave: Reducing Spatial Redundancy in Convolutional Neural Networks with Octave Convolution
Motivation:
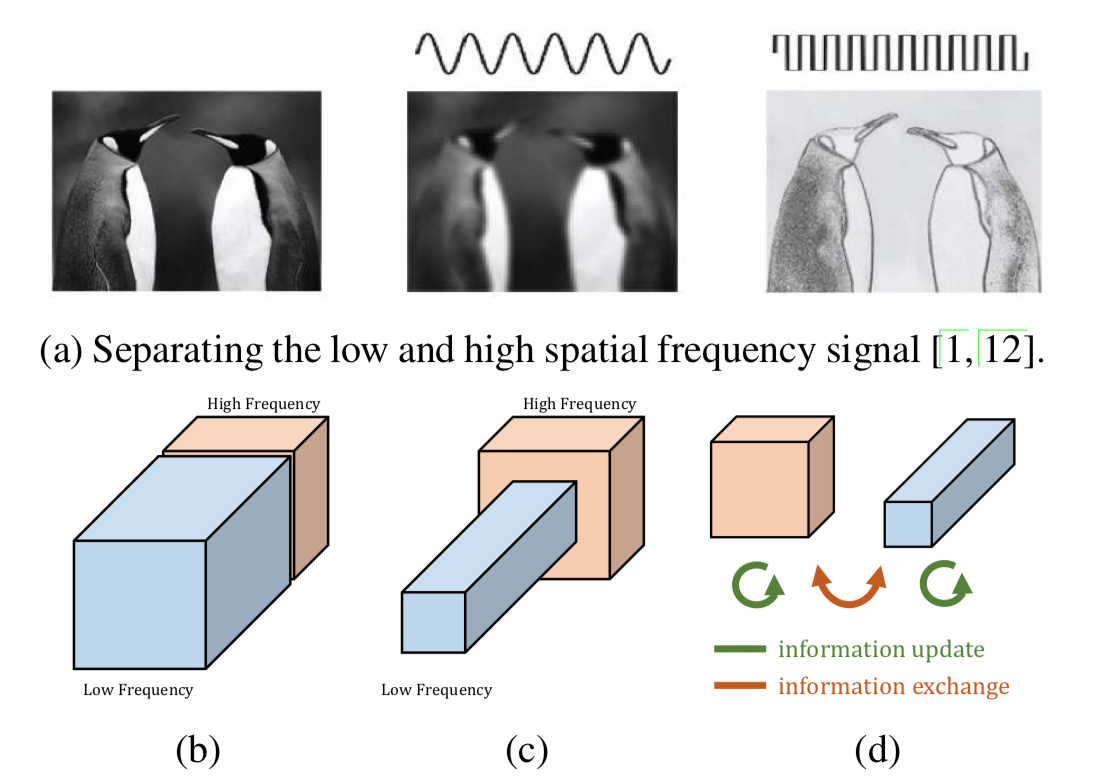
如下图所示:(a)自然图像可以被分解为高频部分和低频部分。高频分量表达细节,低频分量表达整体。很显然,低频分量是存在冗余的,在编码过程中可以节省。(b) 卷积层的输出通道也是如此,可以被分解为低频分量和高频分量并进行重组。(c)作者将低频分量的通道大小设置为高频分量通道大小的一半,用来减少冗余。(d) 低频部分和高频部分可以各自更新,并进行通道之间的交流。
mothods
作者提出了 conv 的改进版 OctConv 用来降低低频部分的冗余度。 Octconv 的结构如下所示:
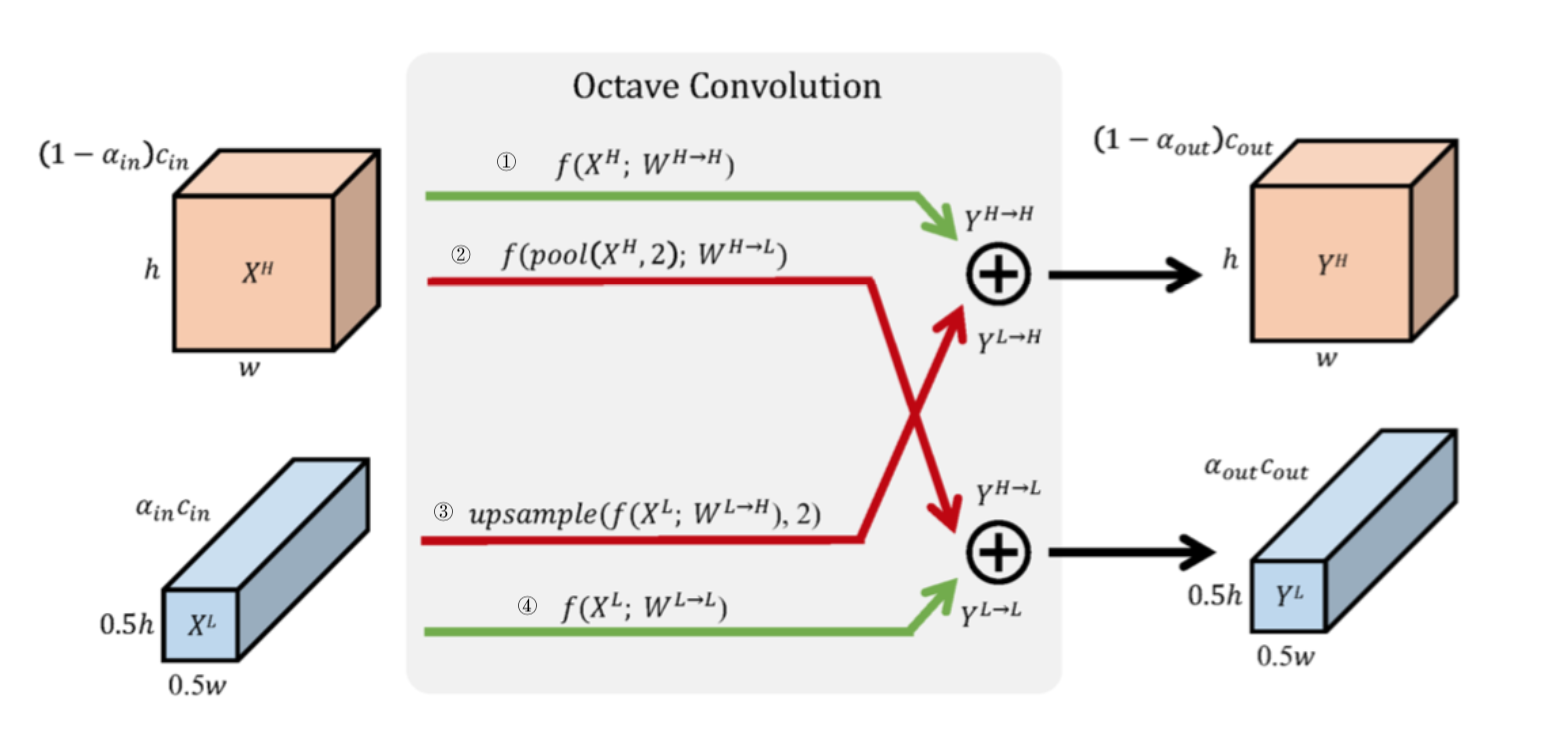
当在第一个 OctConv 是 $\alpha_{in} = 0$,此时执行 ①② 两个操作。
if self.type == 'first':
return self.H2H(x), self.H2L(self.avg_pool(x))
# H2H、L2H 均为传统卷积当在最后一个 OctConv 中 $\alpha_{out} = 0$, 此时执行 ①③ 两个操作。
if self.type == 'last':
hf, lf = x
return self.H2H(hf) + self.L2H(self.upsample(lf))
# H2H、L2H 均为传统卷积当其他情况时,执行 ①②③④四个操作
else:
hf, lf = x
return self.H2H(hf) + self.upsample(self.L2H(lf)),
self.L2L(lf) + self.H2L(self.avg_pool(hf))
# L2H、L2L、H2H、H2L 均为传统卷积octconv 整体的实现代码如下所示:
class OctConv(nn.Module):
def __init__(self, in_channels, out_channels, kernel_size, stride=1, padding=0,
alpha_in=0.25, alpha_out=0.25, type='normal'):
super(OctConv, self).__init__()
self.kernel_size = kernel_size
self.stride = stride
self.type = type
hf_in = int(in_channels * (1 - alpha_in))
hf_out = int(out_channels * (1 - alpha_out))
lf_in = in_channels - hf_in
lf_out = out_channels - hf_out
if stride == 2:
self.downsample = nn.AvgPool2d(kernel_size=2, stride=stride)
if type == 'first':
self.H2H = nn.Conv2d(in_channels, hf_out, kernel_size=kernel_size, stride=1, padding=padding)
self.H2L = nn.Conv2d(in_channels, lf_out, kernel_size=kernel_size, stride=1, padding=padding)
self.avg_pool = nn.AvgPool2d(kernel_size=2, stride=2)
elif type == 'last':
self.H2H = nn.Conv2d(hf_in, out_channels, kernel_size=kernel_size, padding=padding)
self.L2H = nn.Conv2d(lf_in, out_channels, kernel_size=kernel_size, padding=padding)
self.upsample = partial(F.interpolate, scale_factor=2, mode="nearest")
else:
self.L2L = nn.Conv2d(lf_in, lf_out, kernel_size=kernel_size, stride=1, padding=padding)
self.L2H = nn.Conv2d(lf_in, hf_out, kernel_size=kernel_size, stride=1, padding=padding)
self.H2L = nn.Conv2d(hf_in, lf_out, kernel_size=kernel_size, stride=1, padding=padding)
self.H2H = nn.Conv2d(hf_in, hf_out, kernel_size=kernel_size, stride=1, padding=padding)
self.upsample = partial(F.interpolate, scale_factor=2, mode="nearest")
self.avg_pool = partial(F.avg_pool2d, kernel_size=2, stride=2)
def forward(self, x):
if self.type == 'first':
if self.stride == 2:
x = self.downsample(x)
return self.H2H(x), self.H2L(self.avg_pool(x))
elif self.type == 'last':
hf, lf = x
if self.stride == 2:
hf = self.downsample(hf)
return self.H2H(hf) + self.L2H(lf)
else:
return self.H2H(hf) + self.L2H(self.upsample(lf))
else:
hf, lf = x
if self.stride == 2:
hf = self.downsample(hf)
return self.H2H(hf) + self.L2H(lf), self.L2L(self.avg_pool(lf)) + self.H2L(self.avg_pool(hf))
else:
return self.H2H(hf) + self.upsample(self.L2H(lf)), self.L2L(lf) + self.H2L(self.avg_pool(hf))2. res2net
Paper:
Res2Net: A New Multi-scale Backbone Architecture
Methods:
作者提出了一种在更加细粒度(卷积层)的层面提升多尺度表达能力。其基本结构如下图(b) 所示:
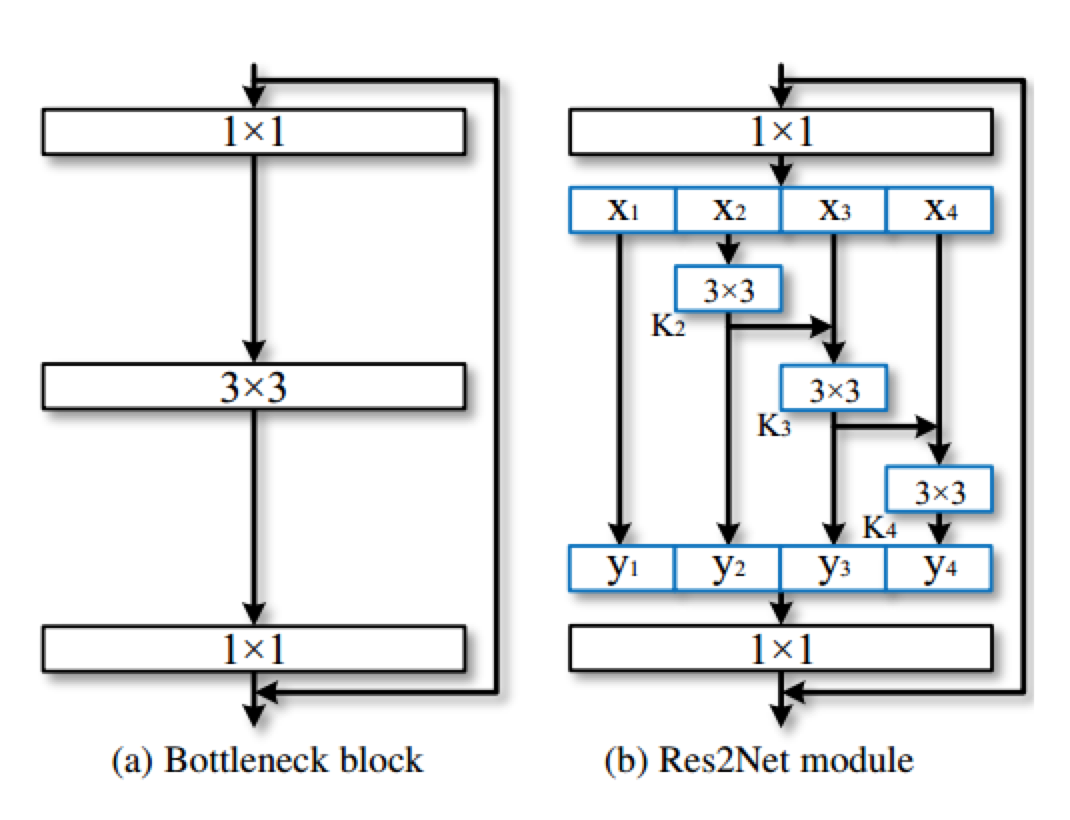
传统的resnet结构如上图所示,作者在其基础上进行改进,在不增加计算量的同时,使其具备更强的多尺度提取能力。如上图(b)所示,作者采用了更小的卷积组来替代 bottleneck block 里面的 3x3 卷积。具体操作为:
- 首先将 1x1 卷积后的特征图均分为 s 个特征图子集。每个特征图子集的大小相同,但是通道数是输入特征图的 1/s。
- 对每一个特征图子集 $Xi$,有一个对应的 3x3 卷积 $K_i$ , 假设 $K_i$的输出是 $y_i$。接下来每个特征图子集 $X_i $会加上 $K{i-1}$ 的输出,然后一起输入进 $K_i$。为了在增大 s 的值时减少参数量,作者省去了 $X_1$ 的 3x3 网络。因此,输出 $y_i$ 可以用如下公式表示:
根据图(b),可以发现每一个 $X_j (j<=i)$ 下的 3x3 卷积可以利用之前所有的特性信息,它的输出会有比 $X_j$ 更大的感受野。因此这样的组合可以使 Res2Net 的输出有更多样的感受野信息。为了更好的融合不同尺度的信息,作者将它们的输出拼接起来,然后再送入 1x1 卷积,如上图(b)所示。
res2Net module 的实现代码如下所示:
class Res2NetBottleneck(nn.Module):
expansion = 4
def __init__(self, in_channels, out_channels, downsample=None, stride=1, scales=4, groups=1, se=False, norm_layer=None):
super(Res2NetBottleneck, self).__init__()
if out_channels % scales != 0:
raise ValueError('Planes must be divisible by scales')
if norm_layer is None:
norm_layer = nn.BatchNorm2d
# Both self.conv2 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv1x1(in_channels, out_channels, stride)
self.bn1 = norm_layer(out_channels)
self.conv2 = nn.ModuleList([conv3x3(out_channels // scales, out_channels // scales, groups=groups) for _ in range(scales-1)])
self.bn2 = nn.ModuleList([norm_layer(out_channels // scales) for _ in range(scales-1)])
self.conv3 = conv1x1(out_channels, out_channels * self.expansion)
self.bn3 = norm_layer(out_channels * self.expansion)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
self.stride = stride
self.scales = scales
def forward(self, x):
identity = x
out = self.relu(self.bn1(self.conv1(x)))
xs = torch.chunk(out, self.scales, 1)
ys = []
for s in range(self.scales):
if s == 0:
ys.append(xs[s])
elif s == 1:
ys.append(self.relu(self.bn2[s-1](self.conv2[s-1](xs[s]))))
else:
ys.append(self.relu(self.bn2[s-1](self.conv2[s-1](xs[s] + ys[-1]))))
out = torch.cat(ys, 1)
out = self.bn3(self.conv3(out))
if self.downsample is not None:
identity = self.downsample(identity)
return self.relu(out + identity)3. Hetconv
Paper:
HetConv: Heterogeneous Kernel-Based Convolutions for Deep CNNs
Methods:
本文提出了一种高效的异构卷积过滤器(一些核的大小是 3x3, 其余的是1x1),相较于 mobilenet的原始的 depthwise conv,能在不牺牲准确度的同时提升这些架构的效率。实现的方案很简单, 将传统卷积进行改进,对于某一个卷积,只有1/p个通道 使用 3x3 的卷积,其余均使用 1x1卷积,然后将所有通道相加,作为一个输出通道。
Hexconv module 的实现代码如下所示
class HetConv(nn.Module):
def __init__(self, in_channels, out_channels, p=2):
super(HetConv, self).__init__()
if in_channels % groups != 0:
raise ValueError('in_channels must be divisible by groups')
self.in_channels = in_channels
self.out_channels = out_channels
self.blocks = nn.ModuleList()
for i in range(out_channels):
self.blocks.append(self._make_hetconv_layer(i, p))
def _make_hetconv_layer(self, n, p):
layers = nn.ModuleList()
for i in range(self.in_channels):
if ((i - n) % (p)) == 0:
layers.append(nn.Conv2d(in_channels=1, out_channels=1, kernel_size=3, padding=1))
else:
layers.append(nn.Conv2d(in_channels=1, out_channels=1, kernel_size=1, padding=0))
return layers
def forward(self, x):
out = []
for i in range(0, self.out_channels):
out_ = self.blocks[i][0](x[:, 0: 1, :, :])
for j in range(1, self.in_channels):
out_ += self.blocks[i][j](x[:, j:j + 1, :, :])
out.append(out_)
return torch.cat(out, 1)三种卷积的构造方式总结:
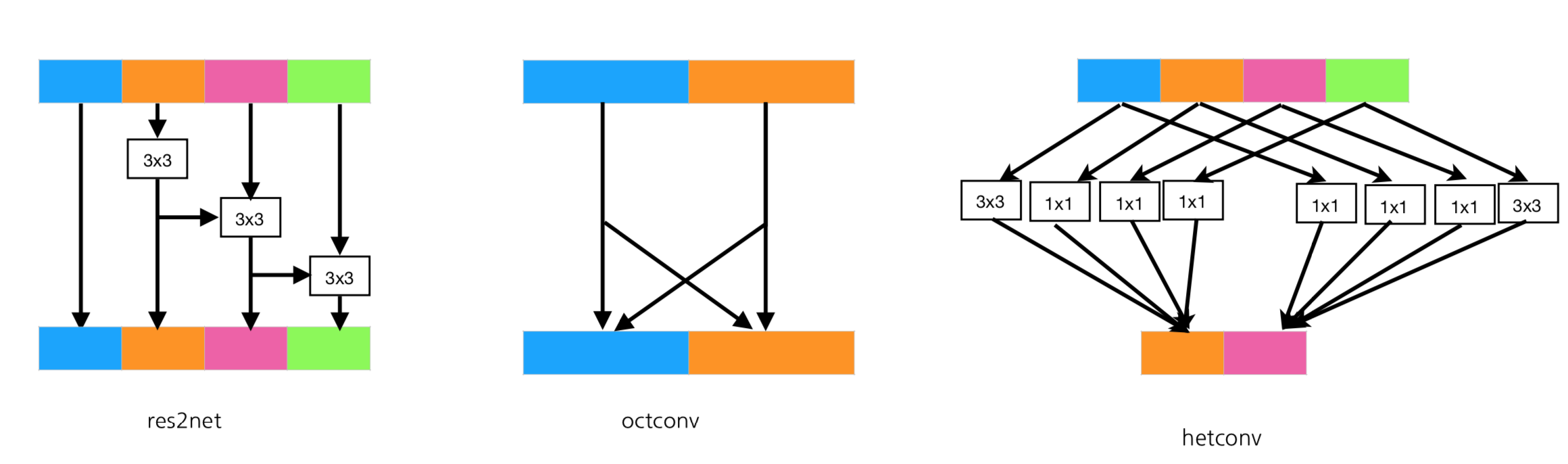
- 三种卷积均在输入通道进行改进,前两种方案(res2net、octconv)都进行了特征通道的融合。但是第一种方案对硬件并不友好(没有进行试验的验证)。第三种方案可以看做是传统卷积的改善,将其中的某些通道设置为3x3,其他通道设置为1x1卷积。
- 常见的多尺度的获取方式:
- 细粒度卷积(res2net方式)
- NIN(例如 Inception 样式的卷积也可以)
- 多尺度图像输出(图像金字塔)
- 特征多尺度(融合多个尺度的特征图:FPN网络)
- 空间金字塔池化(Spatial Pyramid Pooling)
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!