MTCNN
论文阅读: MTCNN Joint Face Detection and Alignment using Multi-task Cascaded Convolutional Networks
1. 概述
相比于R-CNN系列通用检测方法,本文更加针对人脸检测这一专门的任务,速度和精度都有足够的提升。R-CNN,Fast R-CNN,FasterR-CNN这一系列的方法不是一篇博客能讲清楚的,有兴趣可以找相关论文阅读。类似于TCDCN,本文提出了一种 Multi-task的人脸检测框架,将人脸检测和人脸特征点检测同时进行。论文使用3个CNN级联的方式,和Viola-Jones类似,实现了coarse-to-fine的算法结构。
2. 框架
(1).算法流程
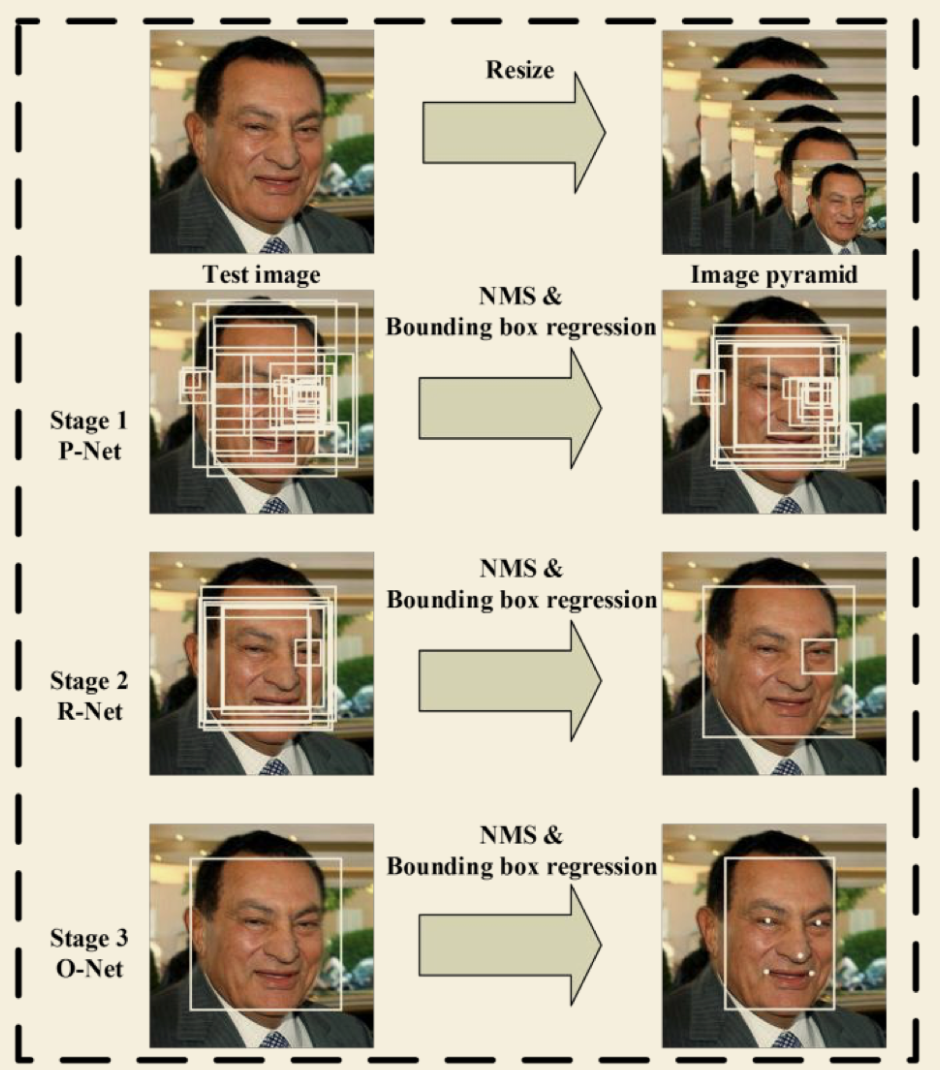
当给定一张照片的时候,将其缩放到不同尺度形成图像金字塔,以达到尺度不变。
Stage 1:使用P-Net是一个全卷积网络,用来生成候选窗和边框回归向量(bounding box regression vectors)。使用Bounding box regression的方法来校正这些候选窗,使用非极大值抑制(NMS)合并重叠的候选框。全卷积网络和Faster R-CNN中的RPN一脉相承。
Stage 2:使用N-Net改善候选窗。将通过P-Net的候选窗输入R-Net中,拒绝掉大部分false的窗口,继续使用Bounding box regression和NMS合并。
Stage 3:最后使用O-Net输出最终的人脸框和特征点位置。和第二步类似,但是不同的是生成5个特征点位置。
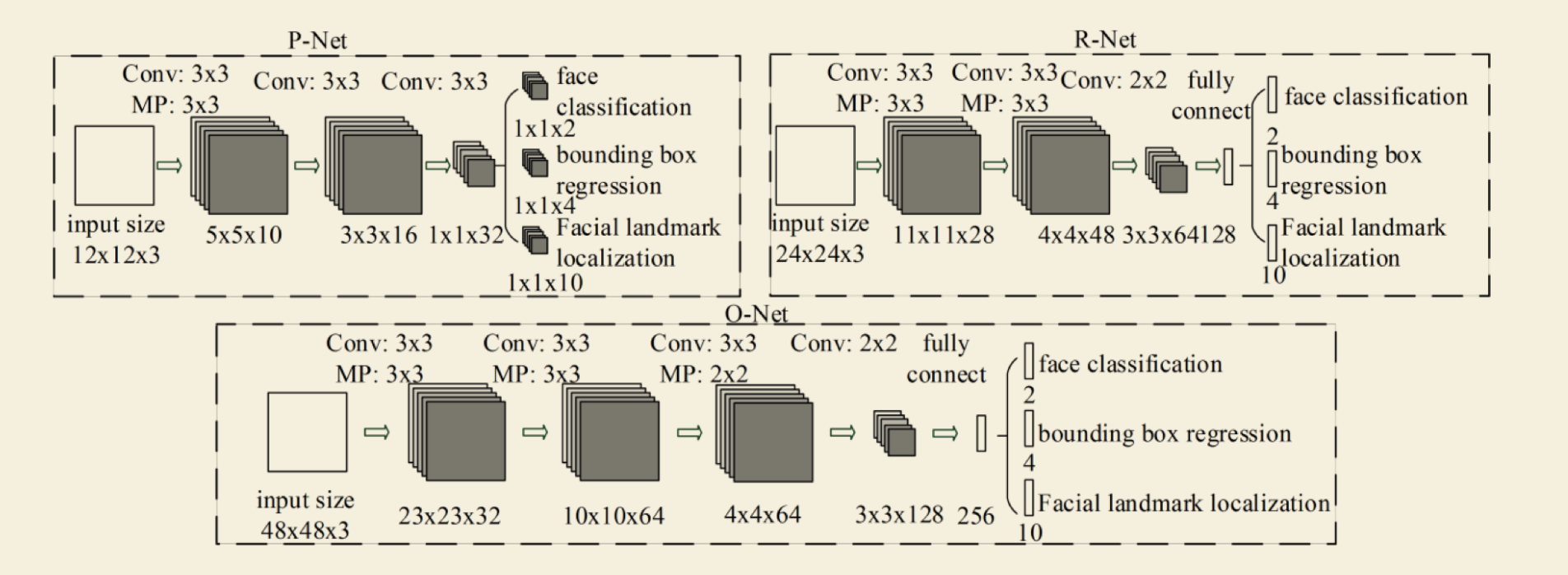
(2)CNN结构
本文使用三个CNN,结构如图:
(3).训练
这个算法需要实现三个任务的学习:人脸非人脸的分类,bounding box regression和人脸特征点定位。
(1)人脸检测
这就是一个分类任务,使用交叉熵损失函数即可:
(2)Bounding box regression
这是一个回归问题,使用平方和损失函数:
(3)人脸特征点定位
这也是一个回归问题,目标是5个特征点与标定好的数据的平方和损失:
(4)多任务训练
不是每个sample都要使用这三种损失函数的,比如对于背景只需要计算$L^{det}_i$,不需要计算别的损失,这样就需要引入一个指示值指示样本是否需要计算某一项损失。最终的训练目标函数是:
N是训练样本的数量,$\alphaj$表示任务的重要性。在 P-Net 和 R-Net 中,$\alpha{det}=1, \alpha{box}=0.5, \alpha{landmark}=0.5$,在O-Net中,$\alpha{det}=1, \alpha{box}=0.5, \alpha_{landmark}=1$
(5)online hard sample mining
传统的难例处理方法是检测过一次以后,手动检测哪些困难的样本无法被分类,本文采用online hard sample mining的方法。具体就是在每个mini-batch中,取loss最大的70%进行反向传播,忽略那些简单的样本。
3. 实验
本文主要使用三个数据集进行训练:FDDB,Wider Face,AFLW。
A、训练数据
本文将数据分成4种:
Negative:非人脸
Positive:人脸
Part faces:部分人脸
Landmark face:标记好特征点的人脸
分别用于训练三种不同的任务。Negative和Positive用于人脸分类,positive和part faces用于bounding box regression,landmark face用于特征点定位。
B、效果
本文的人脸检测和人脸特征点定位的效果都非常好。关键是这个算法速度很快,在2.6GHZ的CPU上达到16fps,在Nvidia Titan达到99fps。
4. 总结
本文使用一种级联的结构进行人脸检测和特征点检测,该方法速度快效果好,可以考虑在移动设备上使用。这种方法也是一种由粗到细的方法,和Viola-Jones的级联AdaBoost思路相似。
类似于Viola-Jones:1、如何选择待检测区域:图像金字塔+P-Net;2、如何提取目标特征:CNN;3、如何判断是不是指定目标:级联判断。
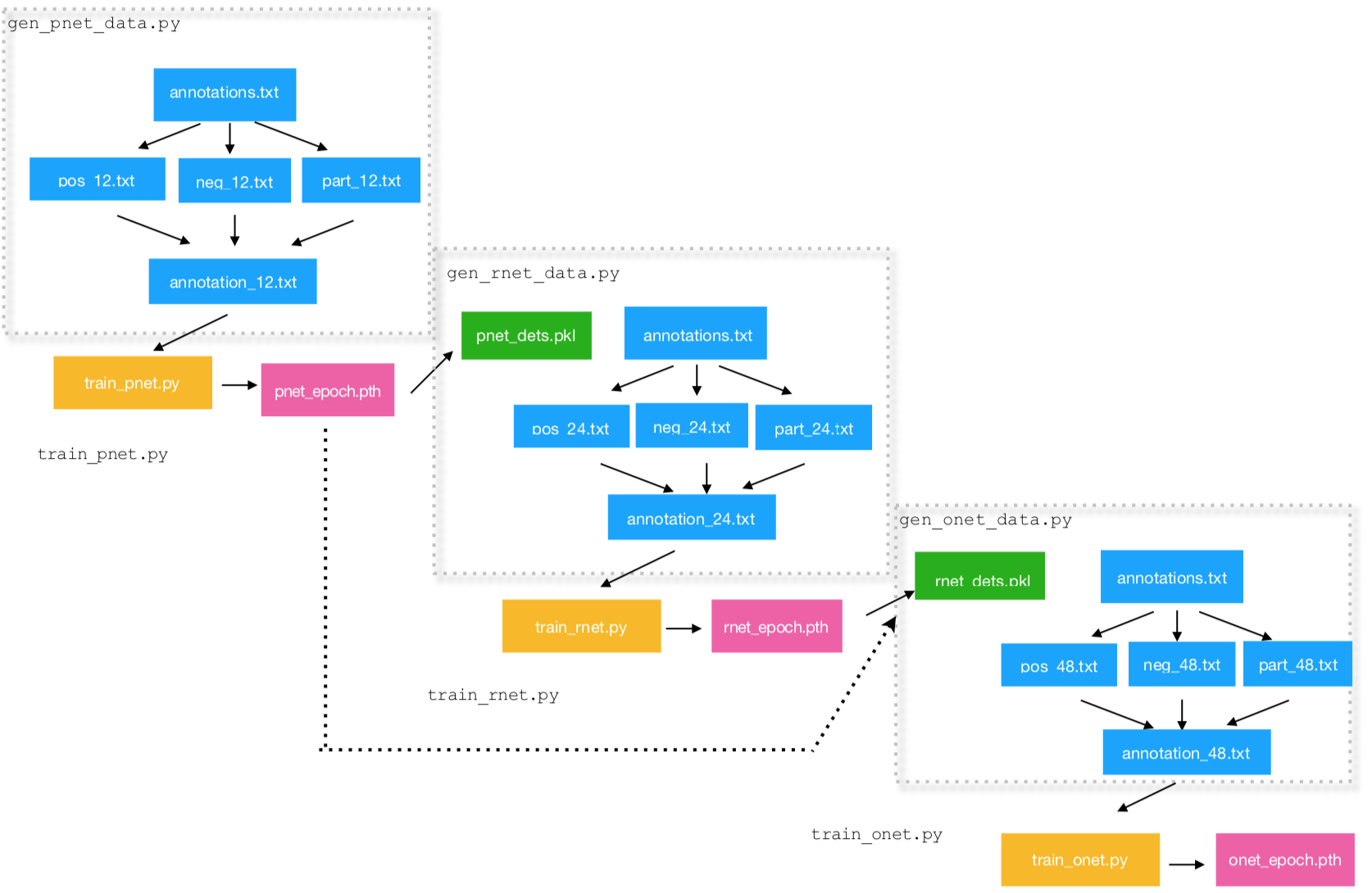
5. 训练流程
第一阶段:首先对原图片构建一个金字塔,对不同尺寸的图片调整到12x12输入到PNet(Propossal)中,PNet会返回诸多的Bbox,利用nms选取合适的Bbox。
第二阶段,由PNet得出的候选框输送给RNet(Refine), RNet会对相应的Bbox进行精细回归,并返回置信度。利用nms对精细回归后的Bbox进行nms选取, 并舍弃相应的置信度较低的人脸。
第三阶段和第二阶段相似,只不过最后会返回相应的Landmark坐标。
具体的训练过程如下所示:
具体的技术细节:
(1) 如何构造金字塔:
如果输入图像为100×120, 假设输入图像中存在一个人脸,则其中人脸最小为20×20,最大为100×100——对应图像较短边长, 为了将人脸放缩到12×12,同时保证相邻层间缩放比率factor=0.709,则金子塔中图像尺寸依次为 60×72、52×61、36×43、26×31、18×22、13×16,其中60×72对应把20×20的人脸缩放到12×12,13×16对应把100×100的人脸缩放到12×12
# scales for scaling the image
scales = []
m = min_detection_size/min_face_size
min_length *= m
factor_count = 0
while min_length > min_detection_size:
scales.append(m*factor**factor_count)
min_length *= factor
factor_count += 1(2) 如何生成训练数据?
PNet 网络:pos、part、neg 是随机裁剪得到的图像,landmark截取的是带有关键点的图像。将这些图像都resize成12x12 作为PNet的输入。
RNet网络:图片(金字塔之后)经过PNet 产生产生的大量人脸框,然后将其resize为 24x24大小作为Rnet 输入。
ONet网络: 图片(金字塔之后)经过PNet 和 RNet 产生的过滤后的人脸框,然后将其 resize 为 48x48大小作为ONet 的输入。
注意:
- pos[IoU>0.65]、part[0.4<=IoU<0.65]、neg[IoU<0.3]
- BBox 和 Landmark 都是需要进行归一化的
(2)NMS的基本原理:
非极大值抑制(NMS)顾名思义就是抑制不是极大值的元素,搜索局部的极大值。
- 将所有框的得分降序排列,选中最高分及其对应的框。
- 遍历其余的框,如果和当前最高分框的重叠面积(IOU)大于一定阈值,我们就将框删除。
- 从未处理的框中继续选一个得分最高的,重复上述过程。
# nms python cpu 实现
import numpy as np
def py_cpu_nms(dets, thresh):
"""Pure Python NMS baseline."""
x1 = dets[:, 0]
y1 = dets[:, 1]
x2 = dets[:, 2]
y2 = dets[:, 3]
scores = dets[:, 4]
areas = (x2 - x1 + 1) * (y2 - y1 + 1)
order = scores.argsort()[::-1]
keep = []
while order.size > 0:
i = order[0]
keep.append(i)
xx1 = np.maximum(x1[i], x1[order[1:]])
yy1 = np.maximum(y1[i], y1[order[1:]])
xx2 = np.minimum(x2[i], x2[order[1:]])
yy2 = np.minimum(y2[i], y2[order[1:]])
w = np.maximum(0.0, xx2 - xx1 + 1)
h = np.maximum(0.0, yy2 - yy1 + 1)
inter = w * h
ovr = inter / (areas[i] + areas[order[1:]] - inter)
inds = np.where(ovr <= thresh)[0]
order = order[inds + 1]
return keep(3)三个任务的损失是什么?函数如何平衡?
第一个任务是分类任务:其损失函数为交叉熵损失函数。第二个任务和第三个任务均是回归任务,其损失是平方均差损失函数。通过加权 $\alpha$ 来平衡三个任务的权重:在 P-Net 和 R-Net 中,$\alpha{det}=1$, $\alpha{box}=0.5$, $\alpha{landmark}=0.5$,在O-Net中,$\alpha{det}=1$, $\alpha{box}=0.5$, $\alpha{landmark}=1$
(4)论文的主要创新点? 尽量简单概括
通过级联三个卷积神经网络来实现人脸的检测和Landmark定位。另外本文也提出了一种online hard sample mining方法,具体就是在每个mini-batch中,取loss最大的70%进行反向传播,忽略那些简单的样本。
(5)有什么改进措施?
- 融入 anchor机制, 同时可以修改损失函数为 focal loss
- 加大数据增强方法
- bn层、leakey relu/prelu
- 模仿shufflenet、mobilenet进行改进提高速度
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!