FaceBoxes
FaceBoxes: A CPU Real-time Face Detector with High Accuracy
FaceBoxes: A CPU Real-time Face Detector with High Accuracy
论文阅读:FaceBoxes: A CPU Real-time Face Detector with High Accuracy
文章: http://cn.arxiv.org/abs/1708.05234
Introduction
2个挑战:
1) 在杂乱背景下人脸视角大的变化需要人脸检测器精准的解决复杂人脸和非人脸的分类问题。
2) 较大的搜索空间和人脸尺寸进一步增加了时间效率的需要。
传统方法效率高但在人脸大的视角变化下精度不够,基于CNN的方法精度高但速度很慢。受到Faster R-CNN的RPN以及SSD中多尺度机制的启发,便有了这篇可以在CPU上实时跑的FaceBoxes。
FaceBoxes
(1)RDCL:Rapidly Digested Convolutional Layers, 加速计算
缩小输入的空间大小:为了快速减小输入的空间尺度大小,在卷积核池化上使用了一系列的大的stride,在Conv1,Pool1,Conv2,Pool2上stride分别是4,2,2,2,RDCL的stride一共是32,意味着输入的尺度大小被快速减小了32倍。这里是区别于YOLO v3 的关键, YOLO v3 整体下降了32倍,这里仅仅在 RDCL 部分就下降了32倍,参数量是少了很多,可以加快速度,这个点还是值得借鉴的
选择合适的kernel size:一个网络开始的一些层的kernel size应该比较小以用来加速,同时也应该足够大用以减轻空间大小减小带来的信息损失。Conv1,Conv2和所有的Pool分别选取7x7, 5x5, 3x3的kernel size。
减少输出通道数:使用C.ReLU来增加输出通道数,比使用卷积增加通道数需要的参数量更少。
(2)MSCL:Multiple Scale Convolutional Layers,丰富感受野,使不同层的anchor离散化以处理多尺度人脸
将RPN作为一个人脸检测器,不能获取很好的性能有以下两个原因:(1) RPN中的anchor只和最后一个卷积层相关,其中的特征和分辨率在处理人脸变化上太弱。(2) anchor相应的层使用一系列不同的尺度来检测人脸,但只有单一的感受野,不能匹配不同尺度的人脸。
为解决这个问题,对MSCL从以下两个角度去设计:
Multi-scale design along the dimension of network depth.如下图,anchor在多尺度的feature map上面取,类似SSD。
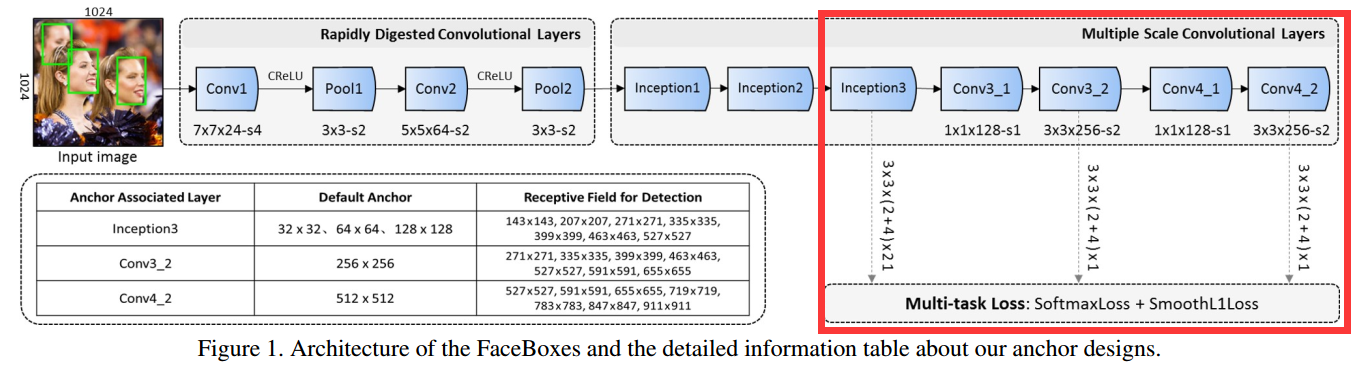
Multi-scale design along the dimension of network width.使用inception模块,内部使用不同大小的卷积核,可以捕获到更多的尺度信息。
(3)Anchor densification strategy:
Inception的anchor尺度为3232,6464,128128,Conv3_2、Conv4_2的尺度分别为256256和512512。比如Conv3_2的stride是64、anchor大小为256256,表示对应输入图片每64像素大小有一个256*256的anchor。

我们定义 anchor密度为:Adensity = Ascale/Ainterval。Ascale表示anchor的尺度,Ainterval表示anchor间隔。
显然在不同尺度上anchor的密度不均衡。相比大的anchor(128-256-512),小的anchor(32和64)过于稀疏,将会导致在小脸检测中低的召回率。
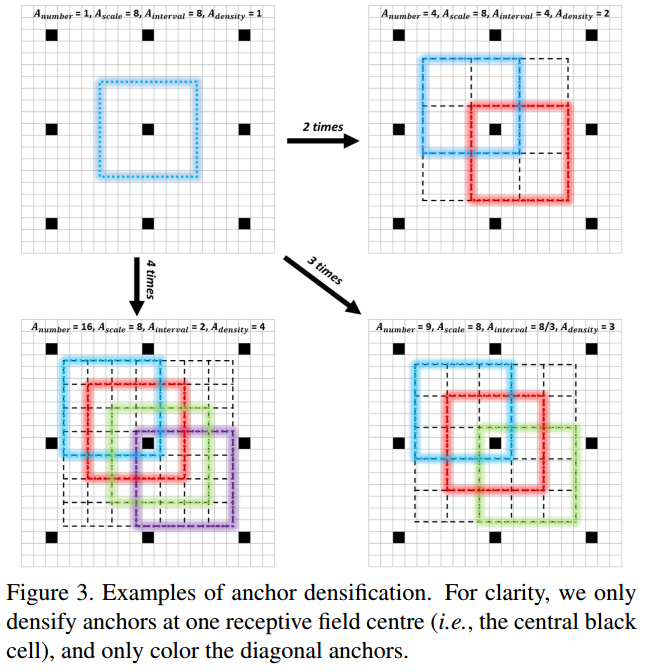
为解决不均衡问题,此处提出新的anchor策略。为了加大一种anchor的密度,在一个感受野的中心均匀的堆叠n^2 个anchor(本来是1个)用来预测。文章里对3232的anchor做了4倍,对6464的anchor做了2倍,这样就可以保证不同尺度的anchor有相同的密度。
训练
1. Training dataset:
WIDER FACE的子集,12880个图片。
(1)Data augmentation:
Color distorition:根据《Some Improvements on Deep Convolutional Neural Network Based Image Classification》
Random cropping: 从原图中随机裁剪5个方块patch:一个最大方块,其他的分别在范围[0.3, 1]之于原图尺寸。
Scale transformation:将随机裁剪后的方块patch给resize到1024*1024.
Horizontal flipping: 0.5的概率翻转。
Face-box filter: 如果face box的中心在处理后的图片上,则保持其重叠,然后将高或宽小于20像素的face box过滤出来。
(2)Matching strategy:
在训练时需要判断哪个anchor是和哪个face bounding box相关的。首先使用jaccard overlap将每个脸和anchor对应起来,然后对anchor和任意脸jaccard overlap高于阈值(0.35)的匹配起来。
(3)Loss function:
和Faster R-CNN中的RPN用同样的loss,一个2分类的softmax loss用来做分类,smooth L1用来做回归。
(4)Hard negative mining:
在anchor匹配后,大多数anchor都是负样本,导致正样本和负样本严重不均衡。为了更快更稳定的训练,将他们按照loss值排序并选取最高的几个,保证正样本和负样本的比例最高不超过3:1.
(5)Other implementation details:
Xavier随机初始化、优化器SGD、momentum:0.9、weight decay:5e-4,batch size:32,迭代最大次数:120k,初始80k迭代learning rate:1e-3,80-100k迭代用1e-4,,100-120k迭代用1e-5,使用caffe实现。
Experiments
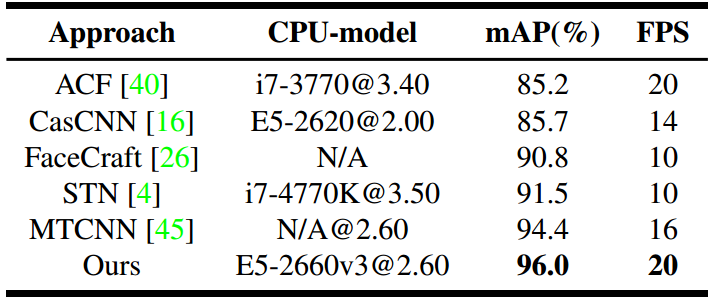
(2) Model analysis
FDDB相比 AFW 和 PASCAL face 较为困难,因此这里在FDDB上作分析。
(2) Ablative Setting:
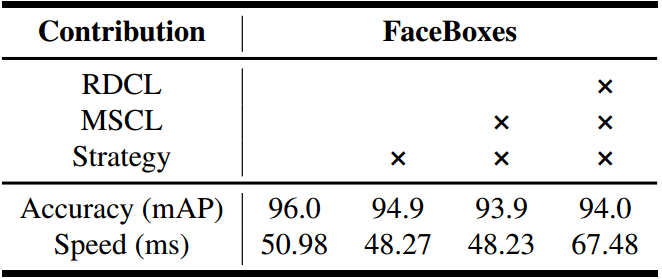
1) 去掉 anchor densification strategy. => Anchor densification strategy is crucial. 这种 anchor 策略也提升了大约1个百分点
2)把 MSCL 替换为三层卷积,其大小都为3*3,输出数都和MSCL中前三个Inception的保持一致. 同时,把anchor只和最后一层卷积关联。 => MSCL is better. 稍微慢了 1点,但是精度提高了一个点(!FPN 已经成为现有网络都借鉴的一点)
3)把RDCL中的C.ReLU替换为ReLU。=> RDCL is efficient and accuracy-preserving. 不改变精确度的情况下, 提升了大约 1/3 的速度
(3) 实验结果:
AFW:
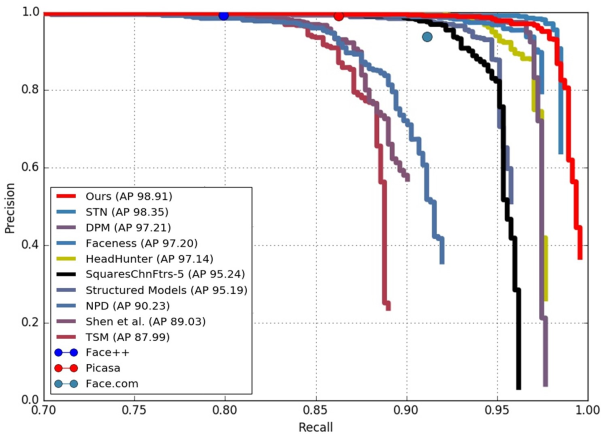
PASCAL face:
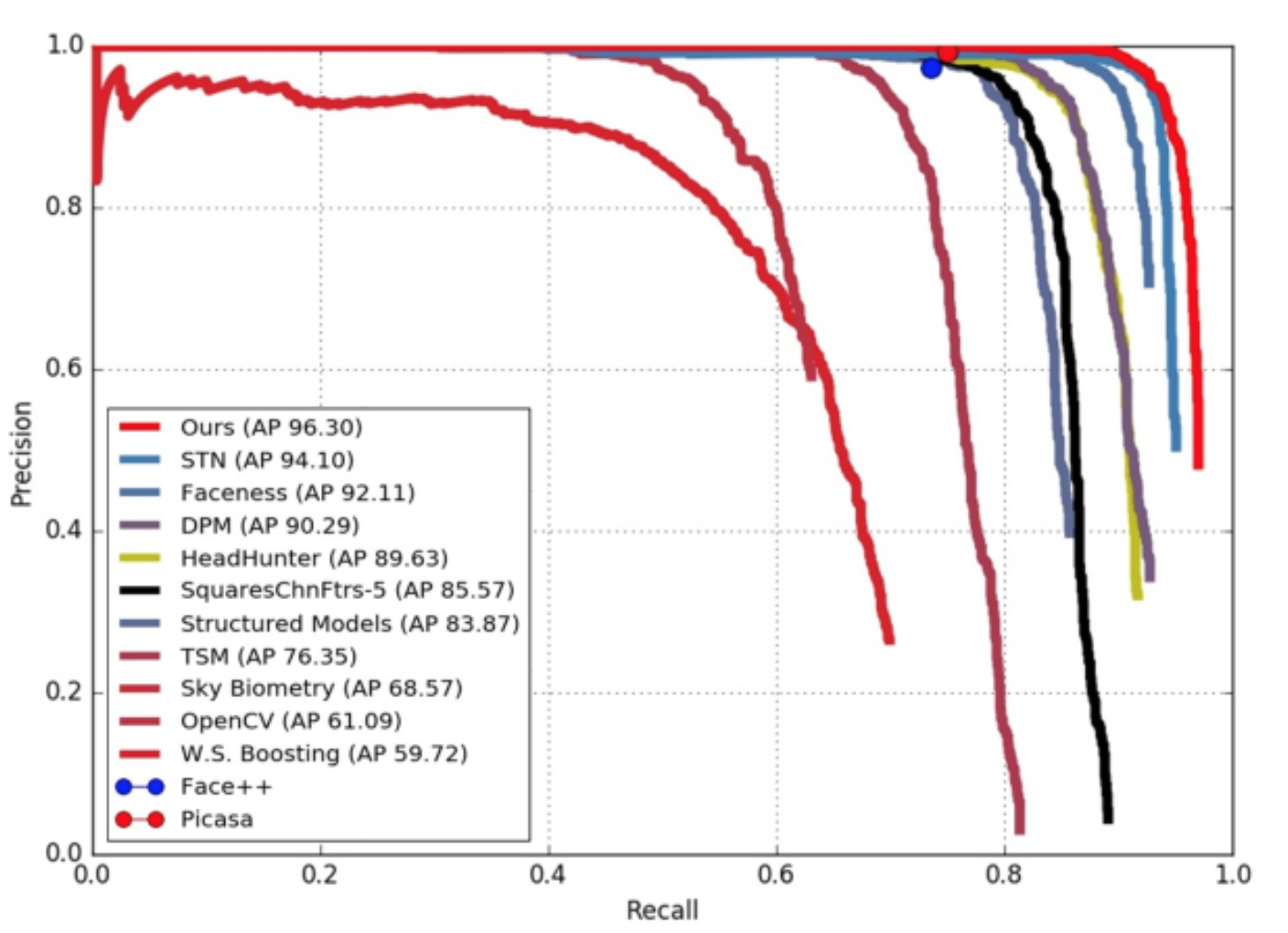
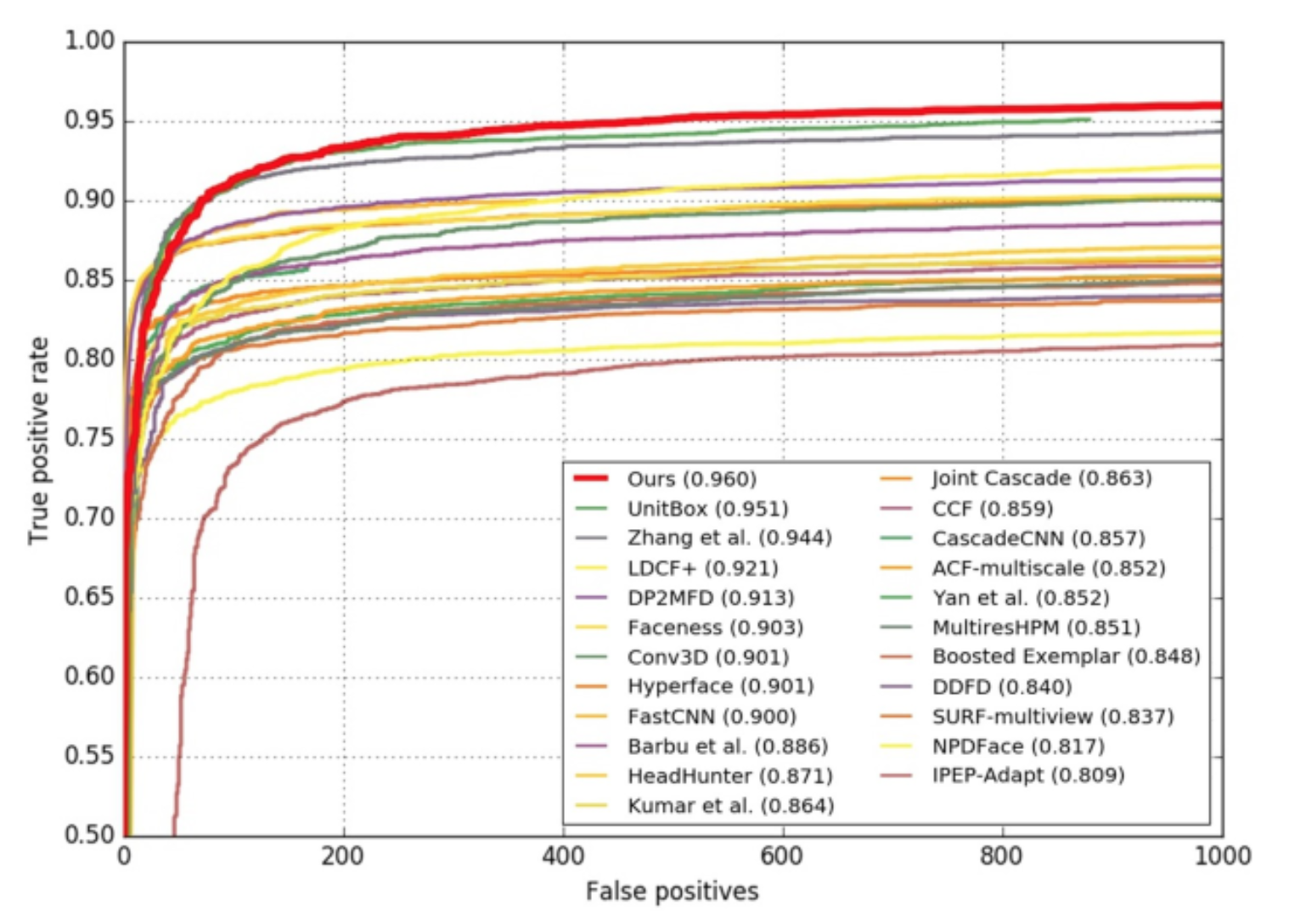
FDDB:
总结:
- 大卷积快速降低运算量 + CReLU
- anchor 采样机制
- 多尺度特征融合
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!