Face-Detection-Solution
Face Detection 人脸检测设计方案
1. 整体网络架构设计
DSFD:ResNet101, DPN−98, SE-ResNeXt101 32×4d、ResNet152、SE-ResNet101(SSD 架构、未进行上下层的融合)
Faceboxes:(conv+CReLU+pool)2 + inception 3 + conv * 4(SSD 架构、未进行上下层的融合)
PymaridBox:VGG16(LFPN架构)
VIM-FD : densenet121 (SSD+attention:STR+STC)
S3FD:VGG16 (SSD + norm)
SSH: vgg16
Scale Face:Resnet 50
smallhardface:VGG16 (one shot、直通式架构:能实现这个性能简直有点不可思议! 值得研究的架构)
SRN:combining DRN with Root-ResNet-18 to have a training speed/accuracy trade-off backbone for SRN
(比较新的架构、值得研究一下:STR+STC)
MSFD:VGG 16(上中下三层融合机制)
对于主干架构,通常选择 vgg16 或者 resnet50/101, 如果追求轻量级可以使用 mobilenetv2 or shufflenet v2。
2. 如何设计多尺度特征
常见的多尺度的设计方案:
(a)图像金字塔,即将图像做成不同的scale,然后不同scale的图像生成对应的不同scale的特征。这种方法的缺点在于增加了时间成本。有些算法会在测试时候采用图像金字塔。
(b)像SPP net,Fast RCNN,Faster RCNN是采用这种方式,即仅采用网络最后一层的特征。
(c)像SSD(Single Shot Detector)采用这种多尺度特征融合的方式,没有上采样过程,即从网络不同层抽取不同尺度的特征做预测,这种方式不会增加额外的计算量。作者认为SSD算法中没有用到足够低层的特征(在SSD中,最低层的特征是VGG网络的conv4_3),而在作者看来足够低层的特征对于检测小物体是很有帮助的。
(d)本文作者是采用这种方式,顶层特征通过上采样和低层特征做融合,而且每层都是独立预测的。
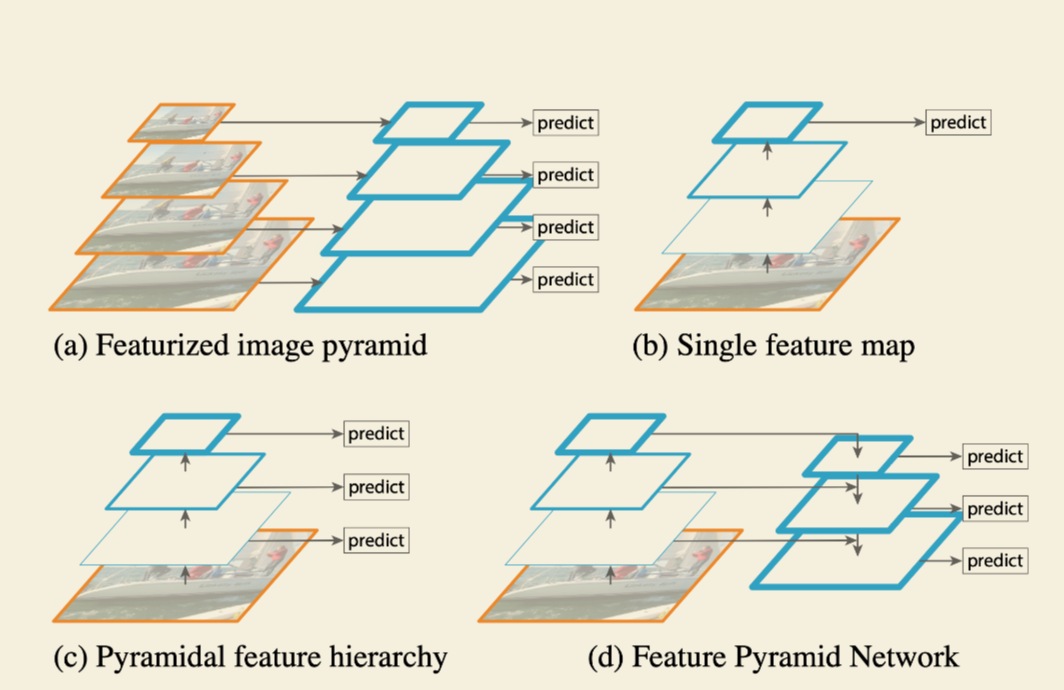
进入 2018年以来,大部分网络均采用 FPN 网络结构的形式,融合多个特征层进行检测。有时候会搭配一个独特设计的网络,比如SRN 的 STR_STC 结构、MSFD 的三层融合机制、DSFD 的 Two-shot 结构。都进行了不同程度的创新。
3. Loss 设计
(1)smooth l1 loss
Smooth l1 loss 的定义如下所示:
(2)focal loss
4. anchor 设计
anchor 设计的三个原则:
(1) anchor 的尺寸、长宽比、位置都应该 match 源数据中的bbox。一种方法是针对特定数据集设计anchor,如YOLOv2中的聚类,和近期有论文CNN训练anchor的设置,这些方法或许更适合某一数据集,但也可能影响模型的泛化能力,换一个库是否依然够用。
(2) anchor的size 必须小于感受野
(3) 不同size的anchor应当具有相同的空间密度分布。密度一致的话,要求 anchor/stride 为一个定值。
5. 数据增强策略:
S3FD:Color distort、Random crop、Horizontal flip
Faceboxes:Color distort、Random crop、Horizontal flip、Scale transformation、Face-box filter
SRN:photometric distortions, randomly expanding by zero-padding operation, randomly cropping patches、 data-anchor-sampling in PyramidBox
Pyramid box: color distort, random crop and horizontal flip.data-anchor-sampling
VIMFD: data-anchor-sampling method in PyramidBox
Small hard face: random cropping,photometric distortion
Tiny face: resize
最常见的几种方案是:Color distort、Random crop(resize)、Horizontal flip、data-anchor-sampling method in PyramidBox
其他值得借鉴的数据增强策略:
[1] SSD & YOLO v3 相关数据增强
[3] torchvision
[4] mxnet:Bag of Freebies for Training Object Detection Neural Networks
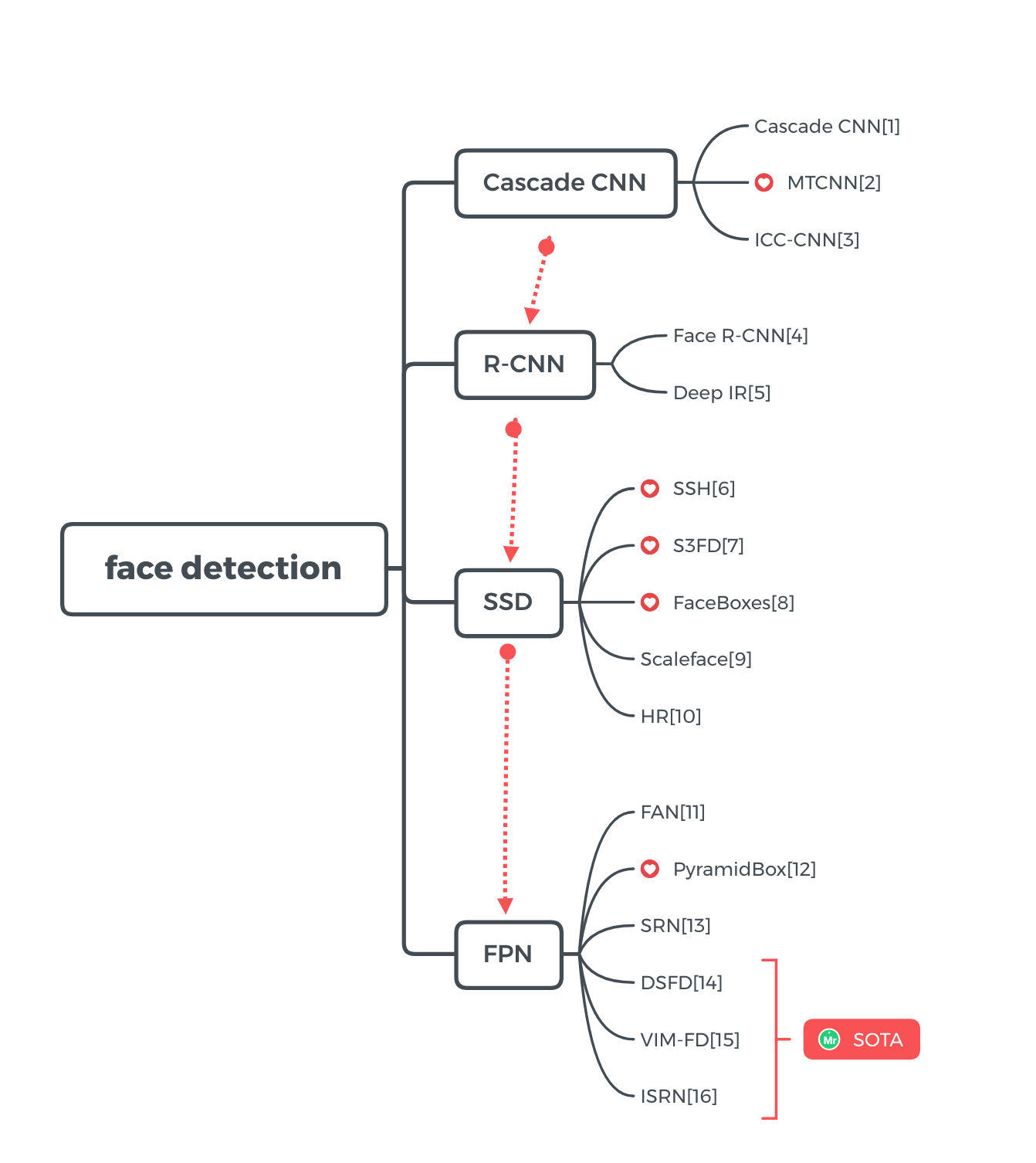
6. 深度学习人脸检测方案的发展
7. 常见数据集
FDDB
Wider-Face
PASCAL
AFW
相比而言:WIDER-FACE 更加权威、FDDB 次之,PASCAL和AFW 都是比较小的数据集,基本可以忽略。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!