Classification_neural_network
本文主要梳理了四种主要常见的分类网络 alexnet、vgg、inception、resnet。
一. 较为基础的分类网络
1. Alexnet
Alexnet 将 LeNet 的思想发扬光大,把CNN 的基本原理应用到了很深很宽的网络中。
AlexNet 主要用到的新技术点如下:
(1) 成功使用ReLU作为CNN 的激活函数,并验证其效果在较深的网络超过 Sigmoid, 成功解决了Sigmoid在网络较深时的梯度弥散问题。
(2) 训练时使用Dropout随机忽略一部分神经元,以避免过拟合。
(3)在CNN中使用重叠的最大池化。此前CNN 中普遍采用平均池化,AlexNet 全部使用最大池化,避免平均池化的模糊化效果。并且 AlexNet 中提出让步长比池化核的尺寸小,这样池化层的输出之间有重叠和覆盖,提高了特征的丰富性。
(4)提出LRN层,对局部神经元的活动创建竞争机制,使得其中响应比较大的值变得相对更大,并抑制其他反馈较小的神经元,增强模型的泛化能力。
(5) 使用CUDA加速深度卷积网络的训练,利用GPU强大的并行能力,处理神经网络训练时大量的矩阵运算。
(6)数据增强,随机地从 256 x 256 的原始图像中截取 224 x 224 大小的区域(以及水平翻转的镜像)相当于增加了(256-224)^2 * 2 = 2048 倍的数据量。大大减轻了模型过拟合,提升泛化能力。同时 AlexNet 论文中提到了会对图像的RGB 数据进行PCA 处理,并对主成分做一个标准差为0.1的高斯扰动, 增加一些噪声。

2. VGGNet
VGGNet探索了卷积神经网络的深度与其性能之间的关系,通过反复堆叠3x3的小型卷积核和2x2 的最大池化层, VGGnet成功构筑了16~19层深的卷积神经网络。
(1)通过将多个卷积层堆叠在一起,可以减少参数数目的同时增加卷积层的非线性变换,使得CNN 对特征的学习能力更强。
(2)VGGNet 在训练时有个小技巧,先训练级别A 的简单网络,再复用A网络的权重来初始化后面几个复杂模型,这样训练收敛的速度更快。
(3)在测试,VGG 采用了 Multi-Scale 的方法,将 图像scale到一个尺寸Q, 并将图片输入卷积网络运算。再将不同尺寸Q的结果平均得到最后结果,这样提高图片数据的利用率并提升准确率。同时在训练中还是用了Multi-Scale 的方法做数据增强。
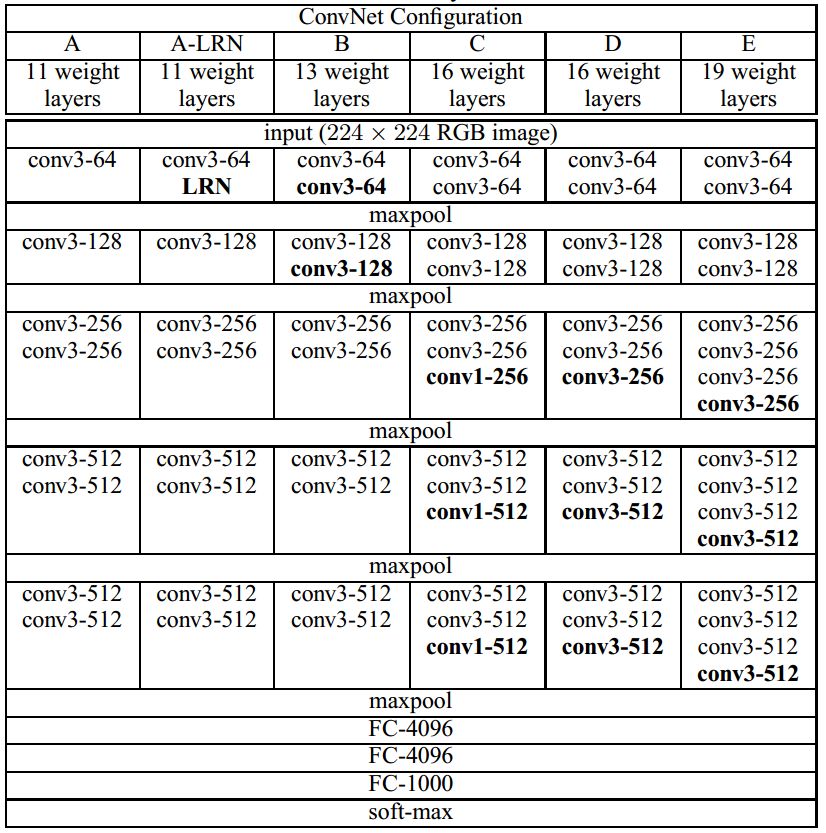
3. Google Inception Net
(1)精心设计了 Inception Module提高参数的利用效率,其结构如下所示,Inception Module中包含3种不同尺寸的卷积核1个最大池化,增加了网络对不同尺度的适应性。
第一个分支对输入进行 1x1卷积,1x1卷积可以跨通道组织信息,提高网络的表达能力,同时可以对输出通道升维和降维。
第二个分支先使用了 1x1 卷积,然后连接 3x3 卷积,相当于进行两次特征变换。
第三个分支和第二个分支类似,先是使用了1x1 的卷积,然后连接 5x5 的卷积。
最后一个分支则是3x3 最大池化后直接使用1x1卷积。
Inception Module 的4个分支在最后通过一个聚合操作合并(再输出通道这个维度上聚合)
(2) 去除了最后的全连接层,用全局平均池化层来取代它。
4. ResNet
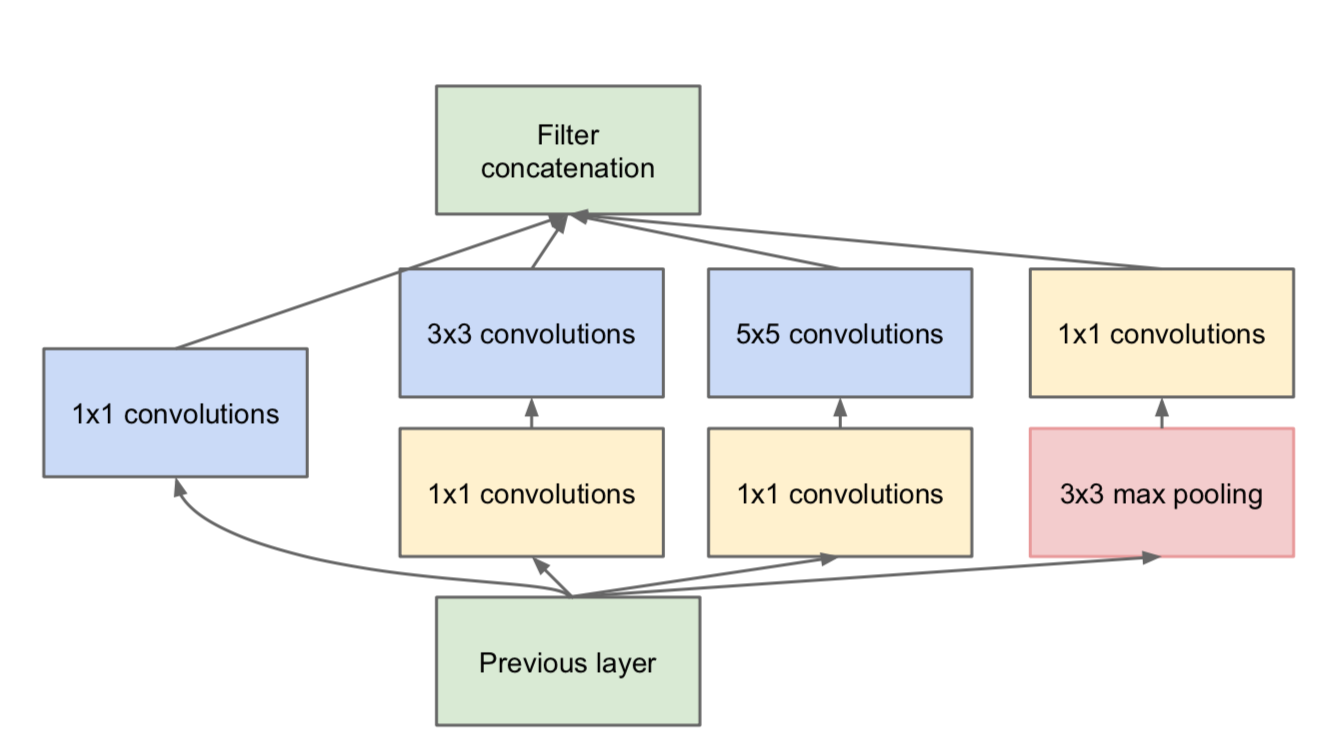
ResNet 通过调整网络结构来解决梯度消失问题(反向传播时,梯度将涉及多层参数的交叉相乘,可能会在离输入近的网络层中产生梯度消失的现象)。首先考虑两层神经网络的简单叠加,这时 x 经过两个网络层的变换得到H(x), 激活函数采用 ReLU, 如下图所示。既然离输入近的神经网络层较难训练,那么我们可以将它短接到更靠近输出的层,如下图所示。输入 经过两个神经网络变换得到F(x) , 同时也短接到两层之后,最后这个包含两层的神经网络模块输出H(x) = F(x) + x 。这样一来,F(x) 被设计为只需要拟合输入x与目标输入H(x)的残差H(x)-x , 残差网络的名称也因此而来。如果某一层的输出已经较好的拟合了期望结果,那么多加入一层也不会使得模型变得更差,因为该层的输出将直接短接到两层之后,相当于直接学习了一个恒等映射,而跳过的两层只需要拟合上层输出和目标之间的残差即可。
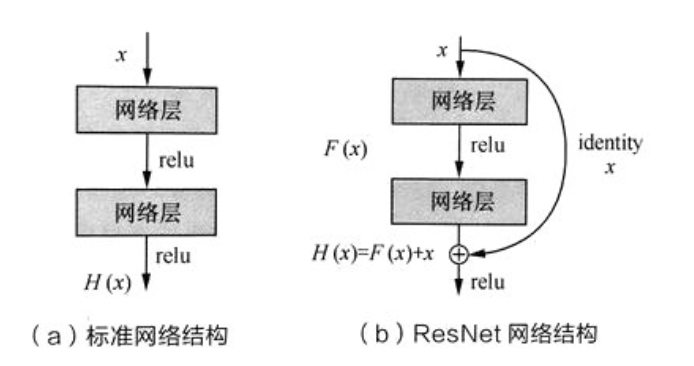
# resnet basicblock
class BasicBlock(nn.Module):
expansion = 1
def __init__(self, inplanes, planes, stride=1, downsample=None, groups=1,
base_width=64, norm_layer=None):
super(BasicBlock, self).__init__()
if norm_layer is None:
norm_layer = nn.BatchNorm2d
if groups != 1 or base_width != 64:
raise ValueError('BasicBlock only supports groups=1 and base_width=64')
# Both self.conv1 and self.downsample layers downsample the input when stride != 1
self.conv1 = conv3x3(inplanes, planes, stride)
self.bn1 = norm_layer(planes)
self.relu = nn.ReLU(inplace=True)
self.conv2 = conv3x3(planes, planes)
self.bn2 = norm_layer(planes)
self.downsample = downsample
self.stride = stride
def forward(self, x):
identity = x
out = self.conv1(x)
out = self.bn1(out)
out = self.relu(out)
out = self.conv2(out)
out = self.bn2(out)
if self.downsample is not None:
identity = self.downsample(x)
out += identity
out = self.relu(out)
return out二、简述 Inception V1 - V4 网络? 🌟
Inception V1(GoogLeNet) 精心设计了 Inception Module 来提高参数的利用效率,该模块包含3种不同尺寸的卷积核1个最大池化,增加了网络对不同尺度的适应性。(1x1conv、1x1conv+3x3conv、1x1conv+5x5conv、3x3pool+1x1conv)
Inception V2 提出来 Batch Normalization, 用来加速网络收敛。
Inception v3 改进了 Inception Module, 将大卷积分解为对称的堆叠小卷积(VGG), 把n*n的卷积核替换成1*n和n*1的堆叠卷积核,在降低运算量的同时增加网络的非线性,减少过拟合。
Inception v4 实际上是 inception + resnet。
# Inception
class Inception(nn.Module):
def __init__(self, in_channels, ch1x1, ch3x3red, ch3x3, ch5x5red, ch5x5, pool_proj):
super(Inception, self).__init__()
self.branch1 = BasicConv2d(in_channels, ch1x1, kernel_size=1)
self.branch2 = nn.Sequential(
BasicConv2d(in_channels, ch3x3red, kernel_size=1),
BasicConv2d(ch3x3red, ch3x3, kernel_size=3, padding=1)
)
self.branch3 = nn.Sequential(
BasicConv2d(in_channels, ch5x5red, kernel_size=1),
BasicConv2d(ch5x5red, ch5x5, kernel_size=3, padding=1)
)
self.branch4 = nn.Sequential(
nn.MaxPool2d(kernel_size=3, stride=1, padding=1, ceil_mode=True),
BasicConv2d(in_channels, pool_proj, kernel_size=1)
)
def forward(self, x):
branch1 = self.branch1(x)
branch2 = self.branch2(x)
branch3 = self.branch3(x)
branch4 = self.branch4(x)
outputs = [branch1, branch2, branch3, branch4]
return torch.cat(outputs, 1)
三. 具体阐述一下你知道的resnet的相关变种 ?
1. resnetv2
将激活函数放置在旁路中, short-cut 构建 clean information path
旁路中的结构从 conv-bn-relu 转换为 bn-relu-conv
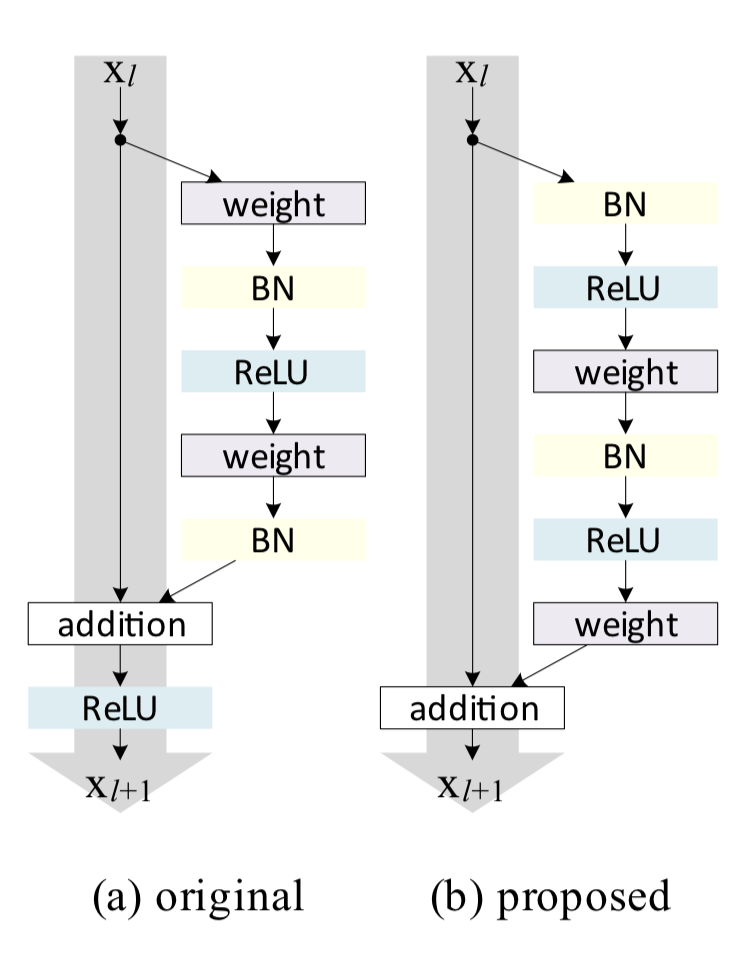
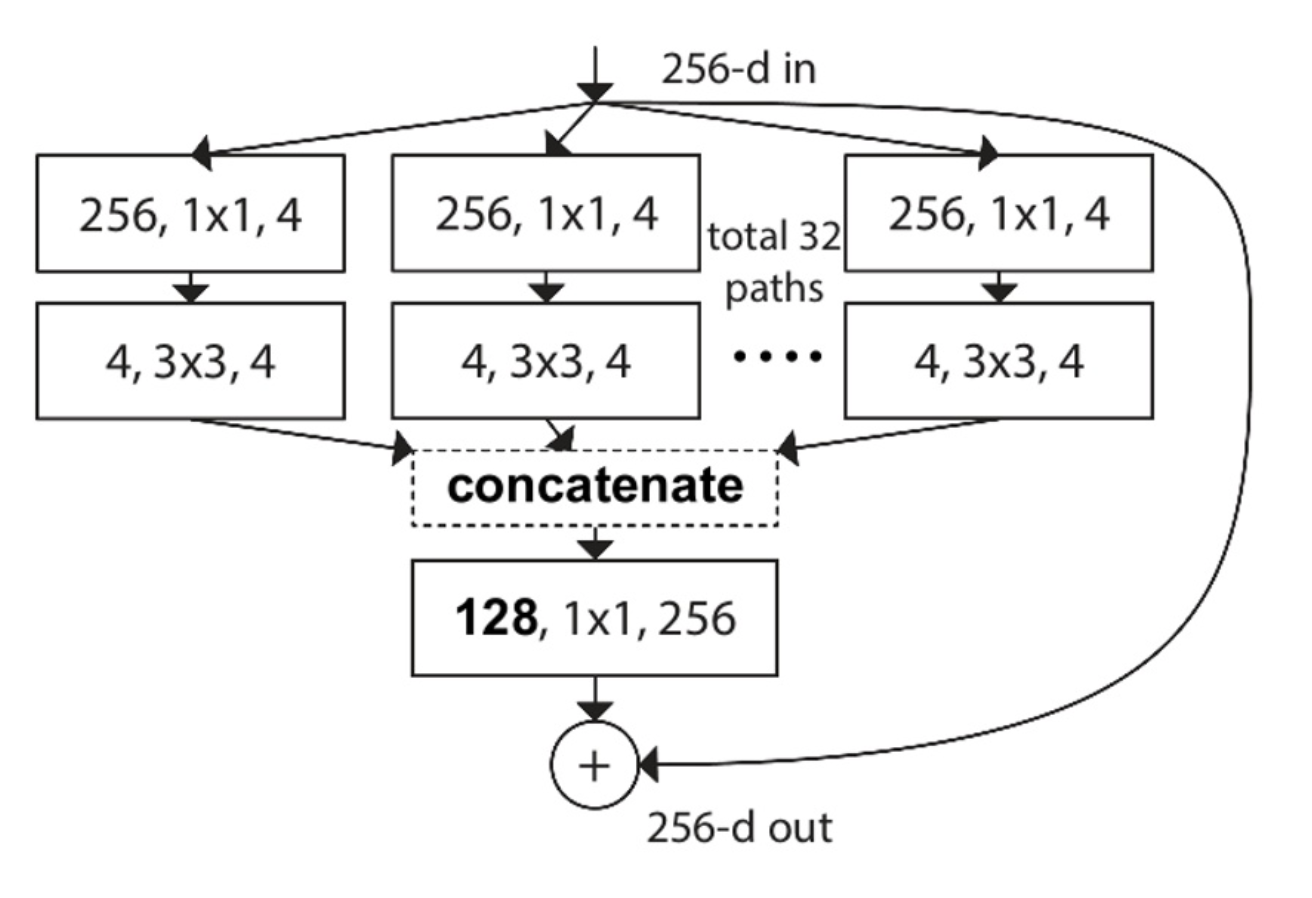
2. resnext
借鉴了 Inception split-transform-merge 的模式, 将单路卷积变成多个支路的多路卷积,不过分组结构一致,进行分组卷积。
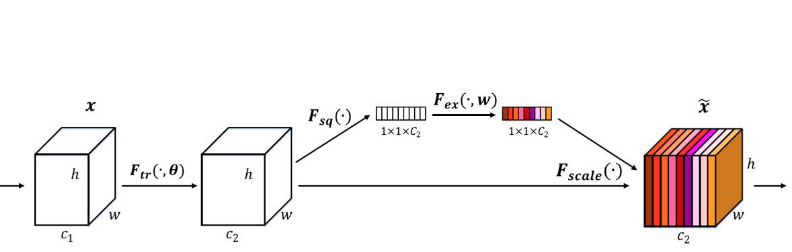
3. SENet
采用了一种全新的「特征重标定」的策略。具体来说,就是通过学习的方式来自动获取到每个特征通道的重要程度,然后依照这个重要程度去提升有用的特征并抑制对当前任务用处不大的特征。
4. Densenet
DenseNet 的目标是提升网络层级间信息流与梯度流的效率,并提高参数效率。它也如同 ResNet那样连接前层特征图与后层特征图,但 DenseNet 并不会像 ResNet 那样对两个特征图求和,而是直接将特征图按深度相互拼接在一起。DenseNet最大的特点即每一层的输出都会作为后面所有层的输入,这样最后一层将拼接前面所有层级的输出特征图。这种结构确保了每一层能从损失函数直接访问到梯度,因此可以训练非常深的网络。
5. res2net
Paper: Res2Net: A New Multi-scale Backbone Architecture
Methods:
作者提出了一种在更加细粒度 (卷积层) 的层面提升多尺度表达能力。其基本结构如下图(b) 所示:

传统的resnet结构如上图所示,作者在其基础上进行改进,在不增加计算量的同时,使其具备更强的多尺度提取能力。如上图(b)所示,作者采用了更小的卷积组来替代 bottleneck block 里面的 3x3 卷积。具体操作为:
- 首先将 1x1 卷积后的特征图均分为 s 个特征图子集。每个特征图子集的大小相同,但是通道数是输入特征图的 1/s。
- 对每一个特征图子集 $Xi$,有一个对应的 3x3 卷积 $K_i$ , 假设 $K_i$的输出是 $y_i$。接下来每个特征图子集 $X_i $会加上 $K{i-1}$ 的输出,然后一起输入进 $K_i$。为了在增大 s 的值时减少参数量,作者省去了 $X_1$ 的 3x3 网络。因此,输出 $y_i$ 可以用如下公式表示:
根据图(b),可以发现每一个 $X_j (j<=i)$ 下的 3x3 卷积可以利用之前所有的特性信息,它的输出会有比 $X_j$ 更大的感受野。因此这样的组合可以使 Res2Net 的输出有更多样的感受野信息。为了更好的融合不同尺度的信息,作者将它们的输出拼接起来,然后再送入 1x1 卷积,如上图(b)所示。
四. 一些问题
- 关于通道的求和与拼接 ?
(1) 常见的 add 操作见于 resnet 和 FPN、CPN。 而 concat 操作见于 Unet 和 Dense net。
(2) add等价于concat之后对应通道共享同一个卷积核。当两路输入可以具有“对应通道的特征图语义类似” 的性质的时候,可以用add来替代concat,这样更节省参数和计算量(concat是add的2倍)。
本博客所有文章除特别声明外,均采用 CC BY-SA 4.0 协议 ,转载请注明出处!